1.数据库索引是什么
数据库索引是为了加快查询速度对表的字段增加的一种标识。DB在执行sql语句的时候,如果没有索引,将会根据搜索条件进行全局遍历,如果对某一字段增加索引,会根据索引定位数据具体所在的位置,减少了查找的次数,加快了操作速度。
2.索引的优缺点
优点:
通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。(依赖于B+Tree)
通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
缺点:
创建索引和维护索引要耗费时间。
索引需要占物理空间。
当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
3.B-Tree的学习
InnoDB,是MySQL的数据库引擎之一,现为MySQL的默认存储引擎,最大特色就是支持了ACID兼容的事务(Transaction)功能。
通过下面语句可以指导InnoDB支持的磁盘页的大小:
show variables like 'innodb_page_size';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| innodb_page_size | 16384 |
+------------------+-------+
每个结点代表一个磁盘区块,如上,一个磁盘区块的大小是16384个字节。
(1)一个M阶的B树,每个非叶节点需要M-1个关键字,和M个分支。
假设每个关键字占用32个字节,每个分支占用4个字节,32*(M-1)+4M<16384,也就是说一个结点可以有M=456个分支。
(2)保证每片树叶存储(L/2~L)条数据
假设每条数据记录占256个字节,一个区块总共可以存储64条记录。取L=64。
(3)保证每个非叶节点都有(M/2-M)条分支
取M=456,每个非叶节点可以有(228-456)个分支
如果总共有100万条数据需要存储,需要的叶子节点数为(10000000/64-10000000/32)=(156250-312500)个叶子节点。
假设按照每个非叶节点的分支数最小,每个叶子节点的数据项取最少,则需要312500个叶子结点,每层有228条分支,228228228=11,852,352>312500
因此只要三层非叶节点,树叶在第四层就可以快速访问到数据。
(4)M阶B+树的时间复杂度是log M/2 N。
4.BTree的插入和删除算法
插入:
/根据关键字沿着分支向下寻找
//如果要插入的叶子节点未满,则直接插入
//如果要插入的叶子节点满了
//可以让邻居叶子节点领养结点并改变父节点的关键字进行插入
//也可以让叶子结点进行分裂,给父节点增加一个儿子
//如果父节点的儿子数满了,则父节点继续分裂,直到根分裂,使得树增加一层
//一般情况下,需要非叶节点分裂的情况比较少见,还是领养的情况多。
删除:
//根据关键字沿着分支向下查找
//如果删除该数据项剩余的数据项少于L/2,考虑从邻居叶子领养
//或者是两片叶子合并成一片叶子
//如果导致父节点的分支数少于M/2,考虑父节点从邻居父节点领养
//或者父节点合并,直到根的两个儿子合并,使树减少一层。
//一般也是领养的方式居多,因为结点的分裂和合并需要做的磁盘处理更多。
5.B+Tree是B-Tree的升级版
相比于B-Tree,B+Tree的特点:
(1)有m个子树的节点包含有m个关键字,只有关键字
(2)数据项只保存在叶子节点,非叶节点只保存关键字(索引)
(3)非叶节点的元素指向儿子结点的最小值或最大值,一般是最小值
(4)叶子节点中的数据项有序排列
(5)叶子结点有指向next叶子的指针,使得所有叶子结点形成有序链表。
找了一张非常形象的图片:
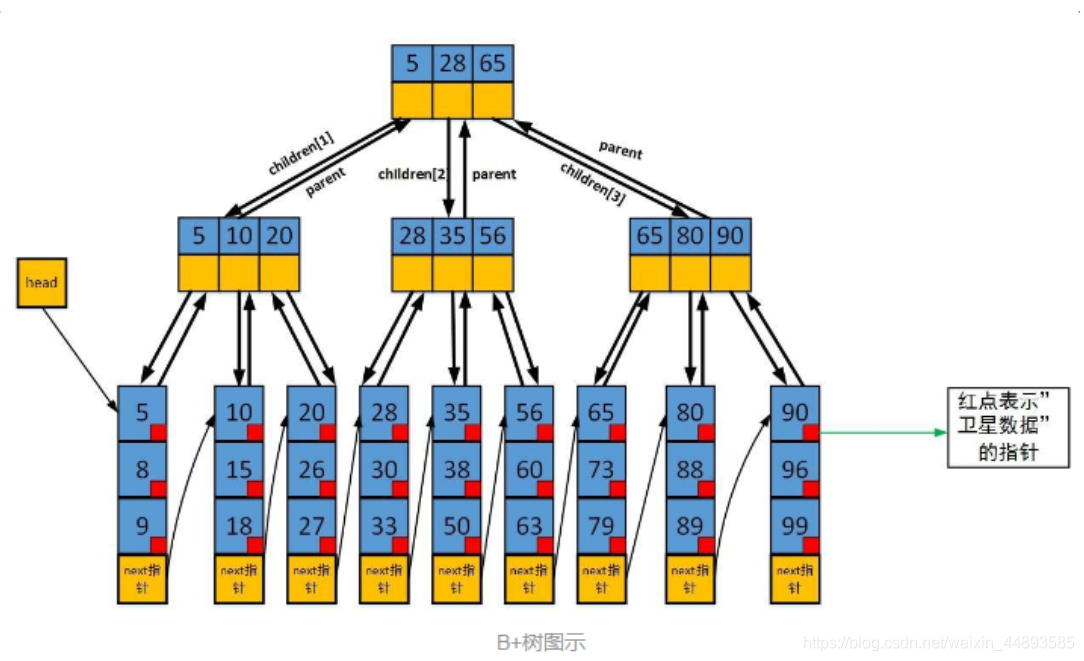
因此,相比于B-Tree,B+Tree在查找上有以下优势:
(1)非叶节点只保存关键字,不保存数据,同样的磁盘页可以有更多的分支
(2)由于数据项只保存在叶子节点中,因此数据项查找比较稳定,总是在叶子节点中找到。
(3)由于叶子节点有指向next叶子的指针,因此,对于分组查询或者排序查询非常有优势,不需要每次从根节点开始查询
另一方面,什么场景下,我们使用BTree而不是B+Tree呢
(1) B树相对于B+树的优点是,如果经常访问的数据离根节点很近,而B树的非叶子节点本身存有关键字其数据的地址,所以这种数据检索的时候会要比B+树快。
(2)从B数和B+tree的结构上来讲,B数的每一个结点都保存数据,相邻叶子节点之间不含指针;而B+tree,数据全部保存在叶子节点,非叶节点只保存关键字,而相邻叶子节点之间右指针,使数据有序。
(3)mysql数据库,经常会用到where子句,进行数据查询,是一种遍历式搜索,B+tree的结构适合于这种业务。
(4)在MongoDB里面,也可以建索引,实现类似于关系型数据库的查询业务,依赖的就是B树:B树的每一个结点都有数据,只要找到了索引就能直接访问数据,单次查询的平均性能,优于B+TRee
