MYSQL
索引:存储引擎级别的概念,不同引擎实现方式不同
索引本身很大,往往以文件形式存储到磁盘,查找过程产生IO消耗,so索引结构组织尽量减少查找过程中IO次数;B-/+Tree性能优势:使用IO次数评价
先安排一些比较常见的基础知识:
主键索引
ALTER TABLE 'table_name' ADD PRIMARY KEY 'index_name' ('column');
唯一索引
ALTER TABLE 'table_name' ADD UNIQUE 'index_name' ('column');
普通索引
ALTER TABLE 'table_name' ADD INDEX 'index_name' ('column');
全文索引
ALTER TABLE 'table_name' ADD FULLTEXT 'index_name' ('column');
还有一个组合索引:ALTER TABLE 表名 ADD INDEX 索引名 (列名1,列名2, 列名3)
B-Tree 附tree
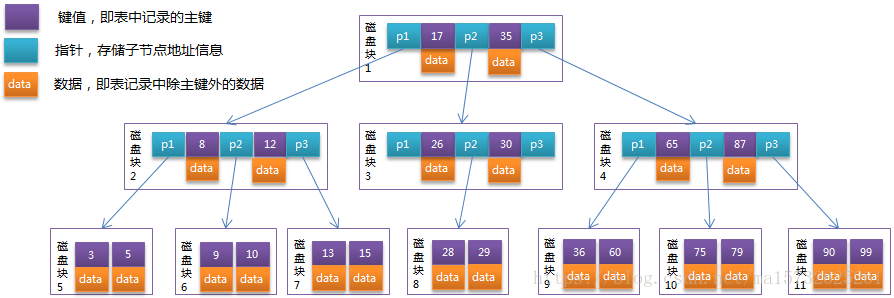
二元组[key,data]
1、d>1正整数 度 ;2、h正整数 高度
3、非叶子节点由n-1个key n个指针组,d<=n<=2d
4、叶子节点min含1key 2指针,max 2d-1key 2d指针
5、all叶节点same深度=h; 6、key 指针互隔 节点两端is指针
7、节点的key从左到右非递减排列 ;8、all节点组成树结构
下面这个是什么?不是从左到右非递减排列吗?
如果某个指针在节点node最左边且不为null,则其指向节点的所有key小于v(key1)v(key1),其中v(key1)v(key1)为node的第一个key的值。
如果某个指针在节点node最右边且不为null,则其指向节点的所有key大于v(keym)v(keym),其中v(keym)v(keym)为node的最后一个key的值。
如果某个指针在节点node的左右相邻key分别是keyikeyi和keyi+1keyi+1且不为null,则其指向节点的所有key小于v(keyi+1)v(keyi+1)且大于v(keyi)v(keyi)。
B+Tree:
数据按键值大小存同一层叶子节点上,非叶子只存key,拥更大的出度、性能,降高度和大小;
指针上限2d,叶子不存指针存数据,叶子节间有链指针,定索引据此定数据
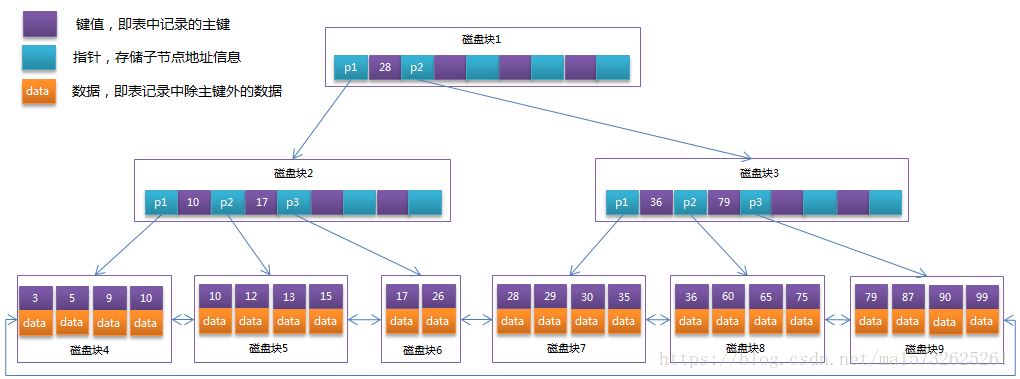
看一个推算:好强大的B+Tree
InnoDB存储引擎中页的大小为16KB,一般表的主键类型为INT(占用4个字节)或BIGINT(占用8个字节),指针类型也一般为4或8个字节,也就是说一个页(B+Tree中的一个节点)中大概存储16KB/(8B+8B)=1K个键值(因为是估值,为方便计算,这里的K取值为〖10〗^3)。也就是说一个深度为3的B+Tree索引可以维护10^3 * 10^3 * 10^3 = 10亿 条记录。
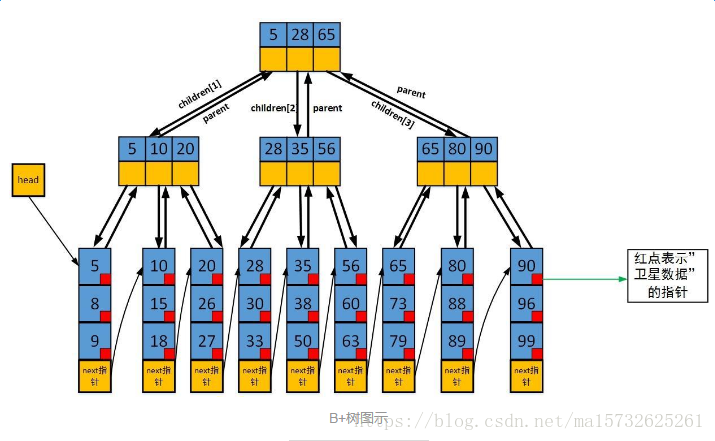
B-/+Tree索引性能分析:
磁盘预读原理,将一个节点大小=一页,节点物理上也存一页里,计算机存储分配按页对齐,一次IO节点载入;
B+Tree更适外存索引
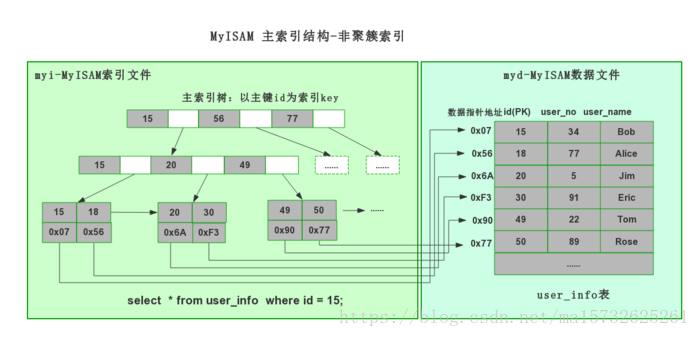
MyIASM:B+Tree 叶data域存放数据记录的地址
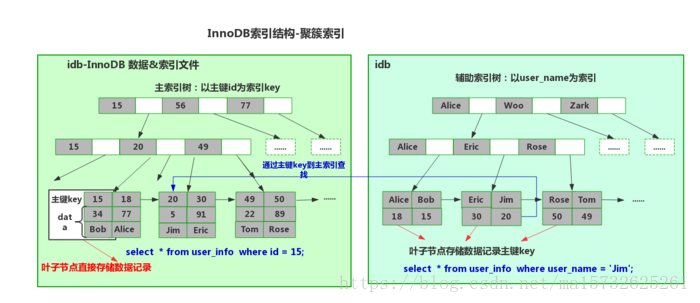
非聚簇索引(索引数据文件分开)索引存指针地址,叶子data存数据记录的指针地址,主辅索引没什么区别,主唯一【图源】
InnoDB:B+Tree
聚簇索引
1、事务ACID支出 2、扩展性优良 3、读写不冲突 4、缓存加速
物理存储文件结构:
表空间Tablespace结构组织,每tablespace含多个segment段,每段(叶子&非叶子)含*Extent,每Extent占1M含64Page,Page含有序ROw行data,其含Filed属性数据
一个逻辑节点分配一个物理page,一节点一IO:一索引一B+Tree,一B+Tree一物理page16K
索引分类(实现):
聚集索引clustered index:数据文件本身即索引文件(主索引)按主键聚集,叶data域存 完整(all) 数据记录,索引key主键;
辅助索引secondary index:辅助索引data域存主键值,辅助索引搜需检索2遍:检查辅助索引获得数据记录主键,主键到主索引检索获数据
不建议使用过长字段做主键:辅助索引引用主索引,过长令辅助索引变得过大;非单调字段为主键X,数据文件B+Tree,造成插入新记录时数据文件为维持B+Tree而频繁分裂电子
索引原理
数据&索引文件为idb,表数据文件=主索引,相邻索引临近存储,叶节点data存完整数据记录:数据[除主键id外其他列data]+主索引[索引ke:主键id];叶子节点存数据记录,主键id为key
数据文件按照主键聚集,如没主键自动选择可唯一表示数据记录的列为主键,否自动生成隐含6字节长整型主键,辅助索引引用数据记录的主键为data域
索引使用策略及优化:B+Tree
结构、查询优化
索引对顺序敏感,mysql查询优化器自动调整where条件顺序
最左前缀原理:
最左优先,查询条件精确匹配索引的左边连续*列时,索引可以被用到一部分(条件组成的最左前缀)
更人性化的翻译:结合下方的多列索引,多列索引建议后根据业务需求,将where字句使用最频繁的一列放在最左边
另一种人性化解释:当b+树的数据项是复合的数据结构,比如(name,age,sex)的时候,b+数是按照从左到右的顺序来建立搜索树的,比如当(张三,20,F)这样的数据来检索的时候,b+树会优先比较name来确定下一步的所搜方向,如果name相同再依次比较age和sex,最后得到检索的数据;但当(20,F)这样的没有name的数据来的时候,b+树就不知道下一步该查哪个节点,因为建立搜索树的时候name就是第一个比较因子,必须要先根据name来搜索才能知道下一步去哪里查询。比如当(张三,F)这样的数据来检索时,b+树可以用name来指定搜索方向,但下一个字段age的缺失,所以只能把名字等于张三的数据都找到,然后再匹配性别是F的数据了;
根据索引的顺序层层筛选,像楼梯一样,首先走到第一层才能上到第二层,依此上第三层、第*层,如果下面的层没有怎么走到上面?因此where查询条件中不包含索引列中的最左索引列,将无法使用到索引查询(建索引时顺序很重要)
前缀索引:
相关 索引选择性:不重复的索引值(基数Cardinality)与表记录数(#T)的比值Index Selectivity = Cardinality / #T 范围(0,1] 越高索引价值越大
列前缀代替列作索引key,前缀长度合适时既使前缀索引选择性接近全列索引又因索引key短检索索引文件大小、维护开销,但是不能用order by 和group by covering index
SELECT count(DISTINCT(concat(first_name, left(last_name, 3))))/count(*) AS Selectivity FROM employees.employees;查看选择性alter table employees.employees add index 'first_name_last_name4' (first_name,last_name(4));建立前缀索引ICP index condition pushdown mysql5.6中引入索引优化技术
原理:在存储引擎内筛选利用索引筛选的where条件(通索引与where对比筛掉不符条件的记录),不是将all的index access结果取出放server进行where筛选;ICP存储引擎用索引过滤可以过滤的where条件,用索引做data access,被index condition过滤掉的数据不必读取也不返回server端,减少了server层和引擎层的交互次数 张洋写于2013-12-05 PHP中文网

对where过滤条件的处理:根据索引使用分为index key,index filter,table filter
1、index key:确定查询在索引中连续范围
2、index filter:上面确定的范围内有数据不符where条件,如果可以使用索引过滤那就是index filter
3、table filter:where条件不能用索引使用table、条件过滤
5.6前不区分index table filter ,统一将范围内索引记录回表读取完整记录,返server过滤,5.6后index Filter下降到InnoDB索引层面进行过滤,减少回表与返回mysql server层的记录交互开销,提高sql执行效率,ICP是index filter技术,因为mysql架构分成了server和引擎层,将原来在server层table filter中可以进行index filter部分在引擎层使用index filter处理
注意:ICP只用于二级索引
加速效果取决于在存储引擎内通过ICP筛选掉的数据的比例
如某where条件字段不再索引中,还是要读取整条记录,到server端做where筛选
Hash索引:
数据索引以hash形式组织起来,不支持范围查找和排序,单值查找系统,用= <=>进行相等比较,键-值存储
单、多列索引
单:设一列为索引,查询时范围限制在这一列上,有一个结果集,再次基础上再次查询产生结果集
多:B-Tree、无须扫描任何记录可得最终结果;如创建了lname_fname_age多列索引,相当于创建了(lname)单列索引,(lname,fname)组合索引以及(lname,fname,age)组合索引
mysql查询时只使用一个索引
空间索引:
5.7.4实验室版InnoDB存储引擎新增了几何数据空间索引,之前InnoDB将其存储为BLOB(二进制大数据),空间数据只能创建前缀索引,效率低效,获取的唯一方式:扫描表
空间索引:辅助性空间数据结构,介于空间操作算法和空间对象间,依据空间对象的位置、形状或空间对象间某种空间关系,通过筛选,排除与特点空间操作无关的空间对象,提高空间操作的速度和效率,含空间对象概要信息:标识、外接矩形及对象实体指针
不会用到索引的情况:
通配符%出现在=的开头、使用or、含义null的列不被包含到索引中
索引最多用于一个范围列<=>,范围列可以用索引(最左前缀)但其后的列无法用
等……
建索引代价:
索引文件消耗存储空间,加重插入、删除和修改的负担,mysql运行时消耗资源维护索引
不建议使用:
表记录少
索引选择性较低(不重复的索引值(基数Cardinality)与表记录数(#T)的比值Index Selectivity = Cardinality / #T (0,1] 越高索引价值越大)
使用索引的技巧:【源 还有索引的常见操作】
1、索引不会包含有null的列;2、短索引:取出列中固定的部分
有一个char(255)的列,如果在前10个或20个字符内,多数值是唯一的,那么就不要对整个列进行索引
3、mysql查询只使用一个索引,where使用了order 不用不会用,尽量不要包含多个列的排序,复合索引可以安排一下
4、不要在列上进行运算,不使用NOT IN <> != 但< <= = > >= between in 可用索引
5、索引建立在值比较唯一的字段上; 6、对于那些定义为text、image、bit的列不应加索引,因为数据量大或取值少; 7、join操作中mysql在主外键类型相同才使用索引
附:
1、多值精确匹配in
2、主键选择与插入优化:
使用InnoDB无特别需要,使用业务无关的自增为主键
InnoDB聚集索引,数据本身被存于主索引的叶子节点上,同一叶子节点内各条数据按主键存放(自增顺序排放),一条记录插入,mysql跟主键将其插入适当的节点和位置,如页面达到装载因子(默认15/16)开辟新页
使用索引排序:【源】
1、order by子句后列顺序要与组合索引的列顺序一致,都是正序或倒序
2、所查询的字段值需要包含在索引列中
3、多表连接查询时,只有当ORDER BY后的排序字段都是第一个表中的索引列时,使用索引
不能使用的情况:
SELECT user_name, city, age FROM user_test ORDER BY user_name, sex;如果sex不是索引列,则不能使用索引
排序
SELECT user_name, city, age, sex FROM user_test ORDER BY user_name;查询字段sex不是索引列
where查询条件后的user_name为范围查询,所以无法使用到索引的其他列
SELECT user_name, city, age FROM user_test WHERE user_name LIKE 'feinik%' ORDER BY city;鸣谢:
文中链接的作者们
MySQL中B+Tree索引原理