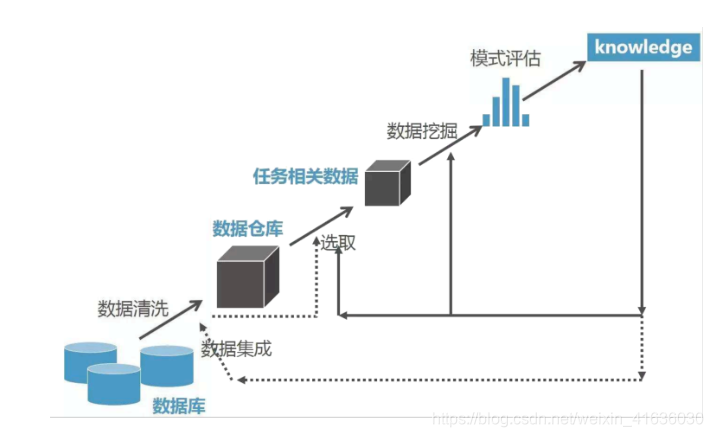
数据挖掘: 数据库知识发现
流程:
- 数据清理:消除噪声和不一致数据
- 数据集成:多种数据源可组合一起
- 数据选择:从数据库提取和分析任务相关数据
- 数据变换:通过汇总或聚集操作,把数据变换和统一成适合挖掘的形式
- 数据挖掘:使用智能方法提取数据模式
- 模式评估:根据兴趣度,识别代表知识的真正有趣模式
- 知识表示:使用可视化和知识表示技术,向用户提供挖掘知识
(crisp-dm)数据挖掘6个阶段:业务理解,数据理解,数据准备,建模,模型评估和模型发布
OLTP(online transaction processing):主要是生产型数据处理,一般常见于数据产生,故它是实时数据处理系统,比如一笔交易完成,则在数据库系统中立刻记录下来,故在构建数据库是需要考虑三范式来构建,以方便数据增删改。
OLAP(online analitics processing):主要是构建历史数据,方便进行查询,故它的表一般扁平,插入后的数据一般不会进行更改,所以它的数据一般分为事实表和维度表,用来方便分析人员进行从中调取数据进行分析,它也是数据仓库和数据集市的处理方式
数据中的知识发现(KDD)
ER关系图:不同实体之间的相关关系图
频繁项集:指频繁地在事务数据集中一起出现的商品集合,如许多顾客频繁一起购买的牛奶和面包,它一般常用语关联分析中
簇:数据对象的集合,使得同一个簇中对象相互相似,而与其他簇对象相异
离群点分析:基于聚类技术,把可能的离群点看做与其他对象高度相异的对象
数据矩阵和相异性矩阵
通常,基于内存的聚类和KNN(最近邻)算法都是在这两种数据结构上运行
数据矩阵(对象-属性结构):这种数据结构用关系表的形式或np矩阵存放n个数据对象,p个属性
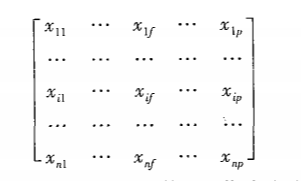
相异性矩阵(对象-对象结构):存放n个对象两两间邻近度,用nn矩阵表示

二元属性邻近性度量
用对称和非对称二元属性刻画对象相异性和相似性度量

jaccard系数:sim(i,j)描述相似程度

例子:
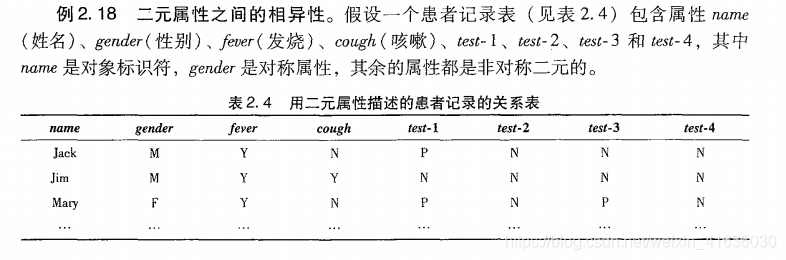
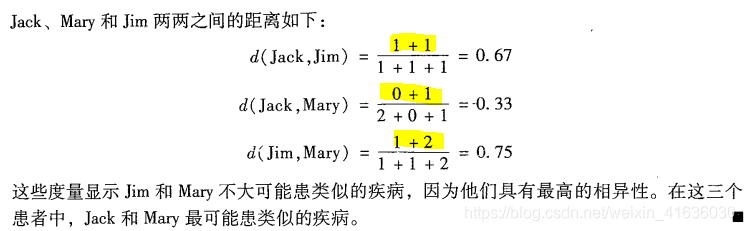
上例对于对象i,j都取0的值进行了剔除,即不参与属性的比较,故称为非对称二元相异性
参考
Slowly Changing Dimension(缓慢变化维):
https://www.nuwavesolutions.com/slowly-changing-dimensions/
