文章目录
hadoop生态

- Pig:一个基于Hadoop的大规模数据分析平台,为海量数据的并行计算,提供了一个简单的操作和编程接口
- Hive:就是一个工具,有完整的SQL查询的功能,可以将sql语句转换为MapReduce任务进行运行 ,当然也要基于hadoop
- ZooKeeper:高效的,可拓展的协调系统,存储和协调关键共享状态
- HBase:一个开源的,基于列存储模型的分布式数据库
- HDFS:一个分布式文件系统,有着高容错性的特点,适合那些超大数据集的应用程序;
- MapReduce:一种编程模型,用于大规模数据集(大于1TB)的并行运算
MapReduce的基本原理就是:将大的数据分析拿到手,拆分成小块一个个地分析,最后再将提取出来的数据汇总分析,就能得到想要的内容;至于怎么分块分析,怎么做Reduce操作,那就很复杂,感兴趣的可以去了解了解
hadoop已经实现了数据分析,我们只需要编写简单的需求命令,就可以拿到想要的数据。
hadoop典型应用有搜索、日志处理、推荐系统、数据分析、视频图像分析、数据保存等。
Spark Streaming
Spark流是对于Spark核心API的拓展,从而支持对于实时数据流的可拓展,高吞吐量和容错性流处理。数据可以由多个源取得,例如:Kafka,Flume,Twitter,ZeroMQ,Kinesis或者TCP接口,同时可以使用由如map,reduce,join和window这样的高层接口描述的复杂算法进行处理。最终,处理过的数据可以被推送到文件系统,数据库和HDFS。

在内部,其按如下方式运行。Spark Streaming接收到实时数据流同时将其划分为分批,这些数据的分批将会被Spark的引擎所处理从而生成同样按批次形式的最终流。
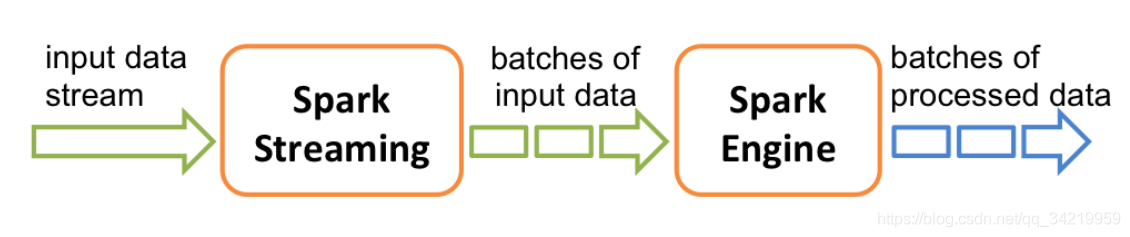
Spark Streaming提供了被称为离散化流或者DStream的高层抽象,这个高层抽象用于表示数据的连续流。
创建DStream的两种方式:
- 由Kafka,Flume取得的数据作为输入数据流。
- 在其他DStream进行的高层操作。
在内部,DStream被表达为RDDs的一个序列。
这个指南会指引你如何利用DStreams编写Spark Streaming的程序。你可以使用诸如Scala,Java或者Python来编写Spark Streaming的程序。文中的标签可以让你在不同编程语言间切换。
注意:少量的API在Python中要么是不可用的,要么是和其他有差异的。
案例可以参考博客:ss例子
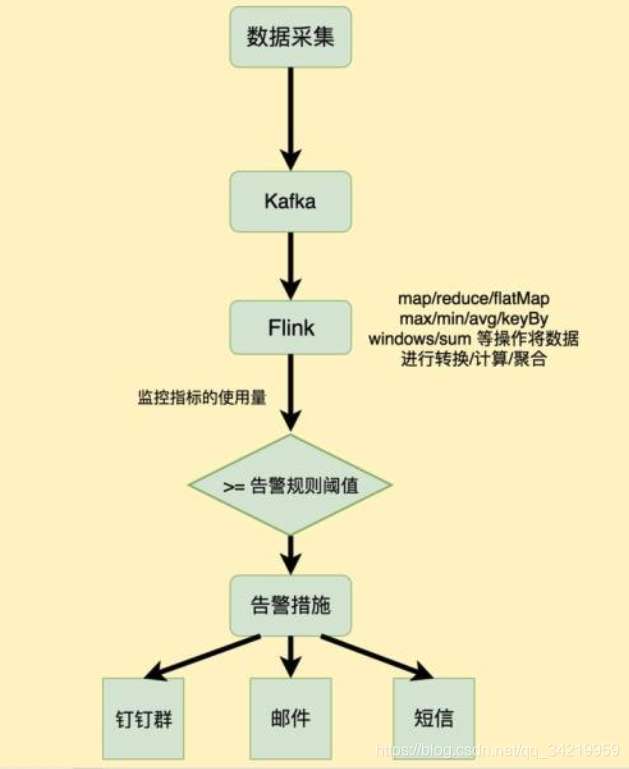
Flink
Flink核心是一个流式的数据流执行引擎,其针对数据流的分布式计算提供了数据分布、数据通信以及容错机制等功能。基于流执行引擎,Flink提供了诸多更高抽象层的API以便用户编写分布式任务:
- DataSet API, 对静态数据进行批处理操作,将静态数据抽象成分布式的数据集,用户可以方便地使用Flink提供的各种操作符对分布式数据集进行处理,支持Java、Scala和Python。
- DataStream API,对数据流进行流处理操作,将流式的数据抽象成分布式的数据流,用户可以方便地对分布式数据流进行各种操作,支持Java和Scala。
- Table API,对结构化数据进行查询操作,将结构化数据抽象成关系表,并通过类SQL的DSL对关系表进行各种查询操作,支持Java和Scala。
此外,Flink还针对特定的应用领域提供了领域库,例如: - Flink ML,Flink的机器学习库,提供了机器学习Pipelines API并实现了多种机器学习算法。
- Gelly,Flink的图计算库,提供了图计算的相关API及多种图计算算法实现
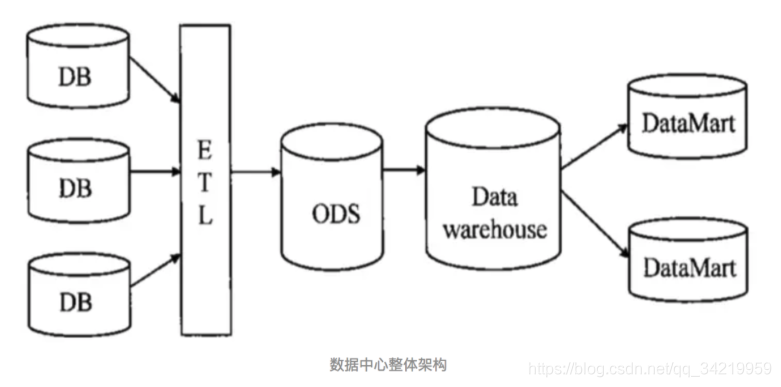
ETL
ETL,Extraction-Transformation-Loading的缩写,中文名称为数据抽取、转换和加载。
一般随着业务的发展扩张,产线也越来越多,产生的数据也越来越多,这些数据的收集方式、原始数据格式、数据量、存储要求、使用场景等方面有很大的差异。作为数据中心,既要保证数据的准确性,存储的安全性,后续的扩展性,以及数据分析的时效性,这是一个很大的挑战。
名词解释:
ODS——操作性数据
DW——数据仓库
DM——数据集市
ELT相关的工具有很多,这里只列举一些常用的,而且各公司的技术原型也不一样,就需要根据实际情况来选择
数据抽取工具:
kafka
flume
sync
数据清洗
hive/tez
pig/tez
storm
spark
其它工具
数据存储:hadoop、hbase,ES、redis
任务管理:azkaban、oozie
数据同步:datax、sqoop
