2017.5.21
白天跟着TensorFlow的官方文档把最简单的MNIST模型跑通了,基本过程算是大致理清了,但程序看一遍下来,发现TensorFlow中很多基本概念还不是很理解,比如tensor这个东西怎么理解,基于图又是怎么回事,于是打道回府从基本概念开始看起。
庆幸的是目前有很多人在学这个,很多学习资料已经归类整理好了,省去了自己重新找的时间,这里整理了一下自己查阅的资料,汇总了一篇。
TensorFlow是基于计算图的框架:
- 使用
图 (graph)来表示计算任务. - 使用
tensor表示数据. - 在被称之为
会话 (Session)的上下文 (context) 中执行图. - 通过
变量 (Variable)维护状态. - 使用
feed和fetch可以为任意的操作(operation)赋值或者从其中获取数据.
TensorFlow程序通常可以分为两个阶段: 图的构建阶段和图的执行阶段
一、计算图(Graph)
现在假如我们要计算下面的表达式,可见,要计算c就需要a和b,计算d需要b,计算e需要c和d,这样就形成了依赖关系。这种有向无环图就叫做计算图。
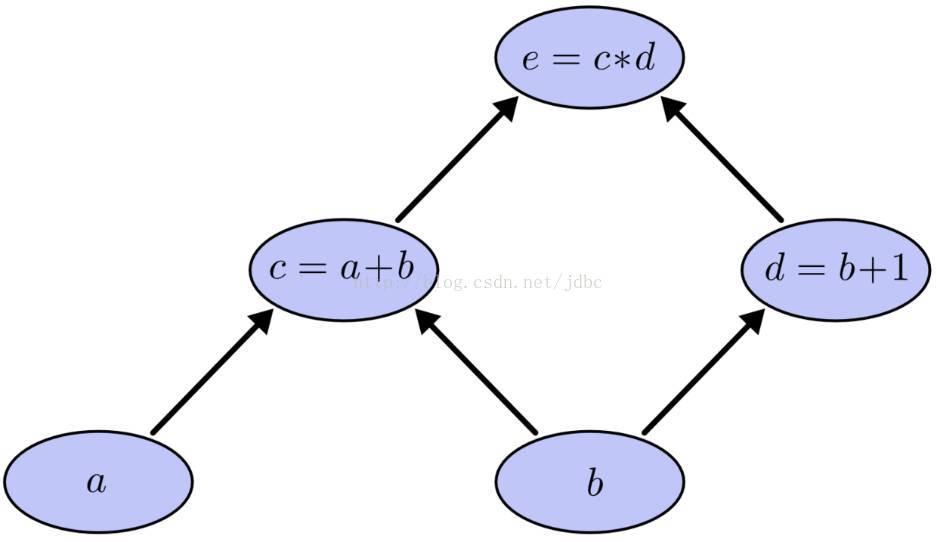
图中的每个节点就是一个操作(operation),operation以0个或多个tensor作为输入,以0个或多个tensor作为输出。比如图中节点c=a+b,a和b是作为输入的两个tensor,c是作为输出的tensor。tensor就在图中沿着箭头方向流动,我想这就是为什么这个框架叫做TensorFlow的原因吧。tensor的概念在第二节再细讲。
在TensorFlow的Python库中已经有一个默认图了,用户可以在图中添加节点,对于大多数程序,这个默认图已经够用了,当然,用户也可以根据需要管理多张图。
graph仅仅定义了operation和tensor的流向,并不进行任何运算。之后session通过graph的定义预分配资源,计算operation,得出结果。tensor是各个操作之间的输入或者输出,除了用Variable维护的tensor外所有的tensor在流入下一个节点后都不再保存。
二、Tensor
在TensorFlow中,数据用tensor表示,在计算图中,所有operation之间传递的数据都是tensor。其实一个tensor可以看成一个多维数组,里面可以存放不同类型的数据。(本来还纠结tensor到底是个什么东西,和MATLAB对比后秒懂=.=)。将tensor在控制台输出,里面有3个属性:
>>> import tensorflow as tf
>>> a = tf.ones([2, 3])
>>> print(a)
Tensor("ones:0", shape=(2, 3), dtype=float32)
>>> b = tf.zeros([2, 3])
>>> print(b)
Tensor("zeros:0", shape=(2, 3), dtype=float32)
>>> c = a + b;
>>> print(c)
Tensor("add:0", shape=(2, 3), dtype=float32)括号里第一个属性是操作的类型(后面那个数字好像是设备号还是什么,这个问题先放在这,以后遇到再去查),第二个是tensor的维度,第三个是tensor的类型。
和单纯的多维数组不同,tensor中还有有rank这个概念,自己敲了几行代码试了下:
>>> import tensorflow as tf
>>> a = tf.ones([4])
>>> b = tf.ones([3, 4])
>>> c = tf.ones([2, 3, 4])
>>> sess = tf.Session()
Creating TensorFlow device (/gpu:0) -> (device: 0, name: GeForce GTX 960M, pci bus id: 0000:01:00.0)
>>> print(sess.run(a)) # rank=1,a是一个向量
[ 1. 1. 1. 1.]
>>> print(sess.run(b)) # rank=2, b是一个二维数组,由3个4维向量组成
[[ 1. 1. 1. 1.]
[ 1. 1. 1. 1.]
[ 1. 1. 1. 1.]]
>>> print(sess.run(c)) # rank=3, c是一个三维数组,由2个3×4的二维数组组成
[[[ 1. 1. 1. 1.]
[ 1. 1. 1. 1.]
[ 1. 1. 1. 1.]]
[[ 1. 1. 1. 1.]
[ 1. 1. 1. 1.]
[ 1. 1. 1. 1.]]] 可以看出,TensorFlow中用一对中括号[]表示一个行向量,高维数组就是由若干个行向量组成,中括号可以嵌套使用。所以,一个tensor前面或者末尾有几个中括号,其rank值就等于几。
三、会话(Session)
构造阶段完成后,才能启动图。启动图的第一步是创建一个 Session 对象,如果无任何创建参数,会话构造器将启动默认图。
import tensorflow as tf
a = tf.ones([1, 3])
b = tf.ones([1, 3])
myPlus = a + b
# 启动默认图
sess = tf.Session()
# 调用Session()的run()方法执行操作
# 整个执行过程是自动化的,会话负责传递操作所需的所有输入。操作通常是并发执行的。
# 返回值 'result' 是一个 numpy `ndarray` 对象.
result = sess.run(myPlus)
print(result)
# 关闭会话,释放资源
sess.close()在实现上, TensorFlow 将图形定义转换成分布式执行的操作, 以充分利用可用的计算资源(如 CPU 或 GPU). 一般你不需要显式指定使用 CPU 还是 GPU, TensorFlow 能自动检测. 如果检测到 GPU, TensorFlow 会尽可能地利用找到的第一个 GPU 来执行操作.
如果机器上有超过一个可用的 GPU, 除第一个外的其它 GPU 默认是不参与计算的. 为了让 TensorFlow 使用这些 GPU, 你必须将 op 明确指派给它们执行. with...Device 语句用来指派特定的 CPU 或 GPU 执行操作.
with tf.device("/gpu:1"):
matrix1 = tf.constant([[3., 3.]])
matrix2 = tf.constant([[2.],[2.]])
product = tf.matmul(matrix1, matrix2)
...四、Variable
变量维护图执行过程中的状态信息。tensor一旦拥有Variable的指向就不会随session的多次载入而丢失。在session中Variable是单独保存的,在使用时必须进行初始化。
init = tf.global_variables_initializer()
sess.run(init)五、placeholder和feed_dict
当我们定义一张graph时,有时候并不知道需要计算的值,比如模型的输入数据,其只有在训练与预测时才会有值。这时就需要placeholder与feed_dict的帮助。
input1 = tf.placeholder(tf.float32)
input2 = tf.placeholder(tf.float32)
output = tf.mul(input1, input2)
with tf.Session() as sess:
print sess.run([output], feed_dict={input1:[7.], input2:[2.]})
# 输出:
# [array([ 14.], dtype=float32)]在上面程序中,input1和input2开始的值是未知的,在sess.run()中才传给它们实际的值,feed_dict={input1:[7.], input2:[2.]}中input1和input2是索引名,默认等于tensor的名字,也可以在定义占位符时自己定义索引名。
input1 = tf.placeholder(tf.float32, name = 'var1')注意,在计算图中,可以用feed_dict来替换任何tensor,并不局限于占位符。