前言
最近在阅读Flink官网的时候,阅读到Storm Compatibility Beta章节,就是Flink可以无缝兼容Storm。
- 在Flink执行一个完整的Storm拓扑;
- 在Flink流程序中使用Storm的Spout/Bolt作为数据源/操作器。
对于Storm的一些基本概念不懂的同学,还是有必要先熟悉了解下Storm的基本概念。
Storm基本元素
storm分布式计算结构称为topology(拓扑)由stream,spout,bolt组成。
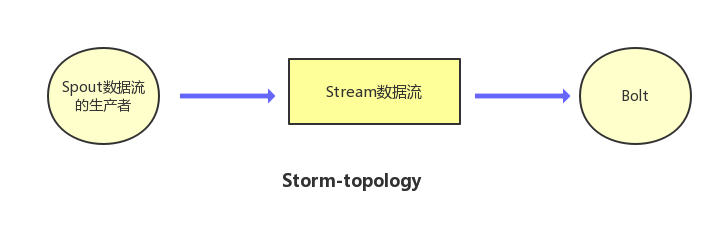
spout代表一个storm拓扑中的数据入口,连接到数据源,将数据转化为一个个tuple,并发射tuple。
stream是由无限制个tuple组成的序列。tuple为storm的核心数据结构,是包含了一个或多个键值对的列表。
bolt可以理解为计算程序中的运算或者函数,bolt的上游是输入流,经过bolt实施运算后,可输出一个或者多个输出流。
bolt可以订阅多个由spout或者其他bolt发射的数据流,用以构建复杂的数据流转换网络。
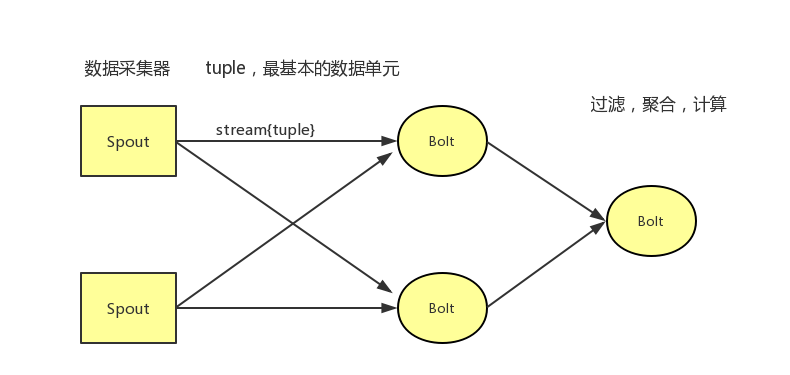
上述即为storm最基本的组成元素,无论storm如何运行,都是以stream,spout,bolt做为最基本的运行单元。而这三者则是共同构成了一个storm拓扑topology。
storm集群组成部分
首先需要明确一个概念,bolt,spout实例,都属于任务,spout产生数据流,并发射,bolt消费数据流,进行计算,并进行落地或再发射,他们的存在以及运行过程都需要消耗资源,而storm集群是一个提供了资源的集群,我们要做的就是将spout/boult实例合理分配到storm集群提供的计算资源上,这样就可以让spout/bolt得以执行。
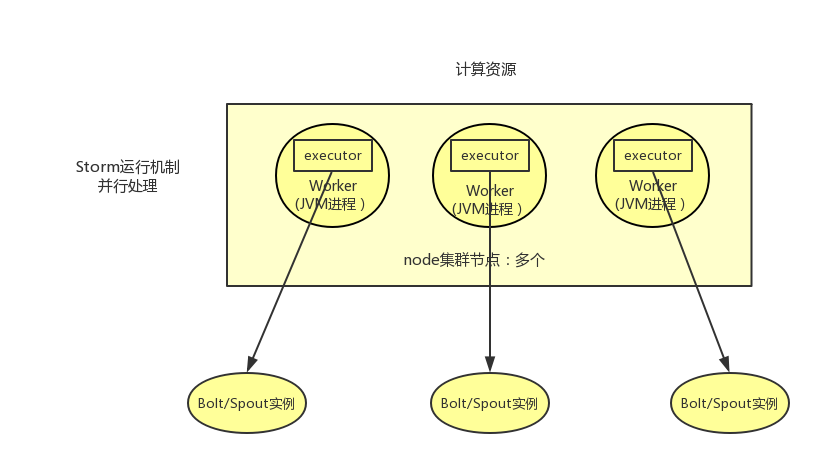
worker为JVM进程,一个topology会分配到一个或者多个worker上运行。
executor是worker内的java线程,是具体执行bolt/spout实例用的。下篇文章在介绍如何提供storm并行计算能力时会介绍worker以及executor的配置。
在storm中,worker是由supervisor进程创建,并进行监控的。storm集群遵循主从模式,主为nimbus,从为supervisor,storm集群由一个主节点(确实有单点问题),和多个工作节点(supervisor)组成,并使用zookeeper来协调集群中的状态信息,比如任务分配情况,worker状态,supervisor的拓扑度量。
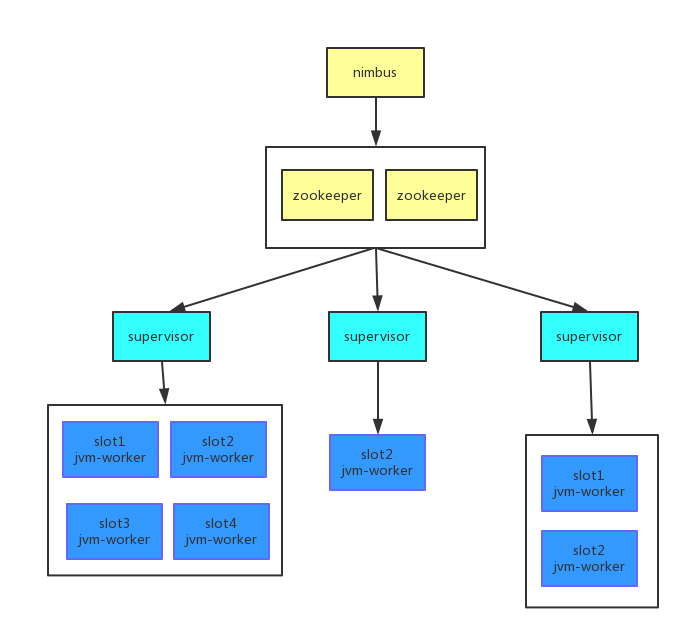
通过配置可指定supervisor上可运行多少worker。一个worker代表一个slot。
nimbus守护进程的主要职责是管理,协调和监控在集群上运行的topology.包括topology的发布,任务指派,事件处理失败时重新指派任务。
supervisor守护进程等待nimbus分配任务后生成并监控workers执行任务。supervosior和worker都是运行在不同的JVM进程上。
笔者定义了一个spout,两个bolt 运算过程如下:
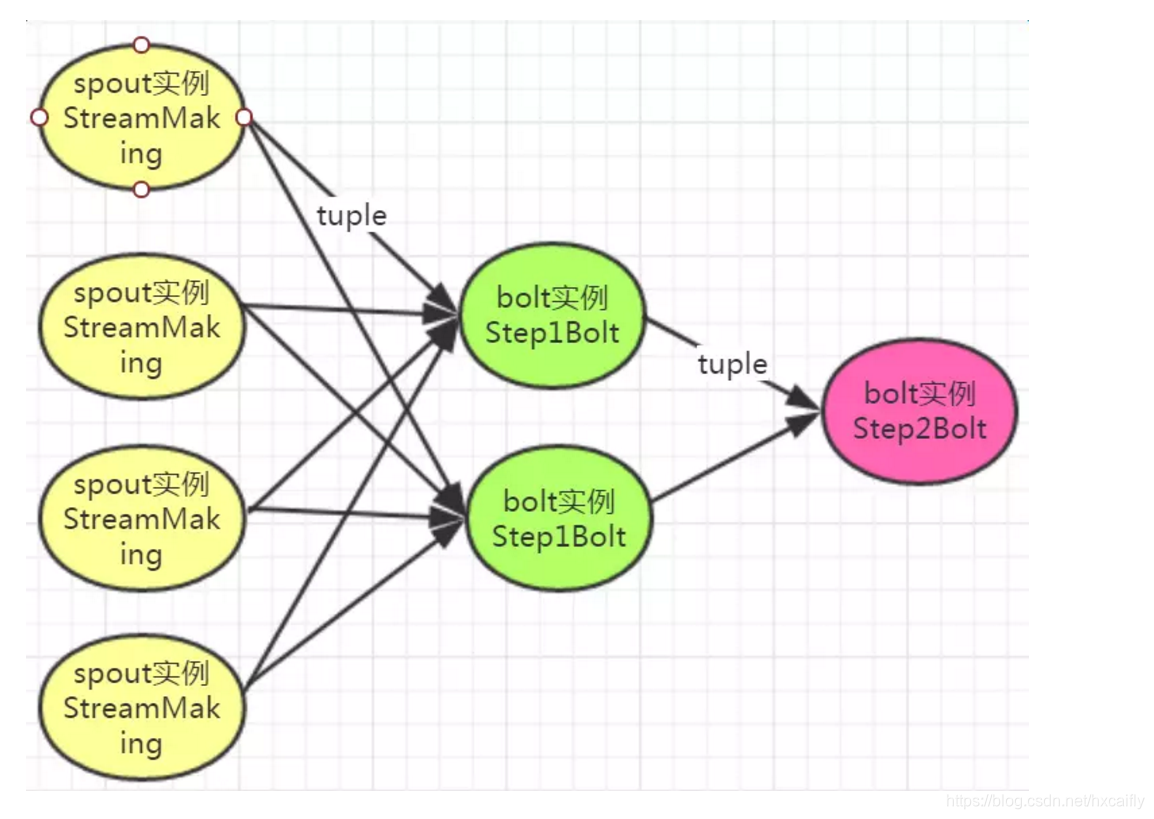
其中streamMaking是一个不断生成随机数(5~30)的spout实例,Step1Bolt会过滤掉15以下的随机数(过滤),15以上的随机数会乘以16(计算),再将结果向后发射。Step2Bolt订阅Step1Bolt发射的数据,接收数据后,打印输出。流程结束。
笔者在定义spout/bolt实例时,配置了spout,bolt的并行执行数。其中
streamMaking:4 Step1Bolt:2 Step2Bolt 1
这样,发布成功后,storm会根据我的配置,分配足够的计算资源给予spout/bolt进行执行。
发布:
发布时,spout和bolt都是在一起以jar的形式发布到nimbus上的,分配后,内部定义的spout和bolt将以组件的形式被nimbus分配至worker进程中执行。
其中worker都是由supervisor创建的,创建出来的worker进程与supervisor是分开的不同进程。一个supervisor可创建多少worker可通过修改storm安装目录下的storm.yaml进行配置。
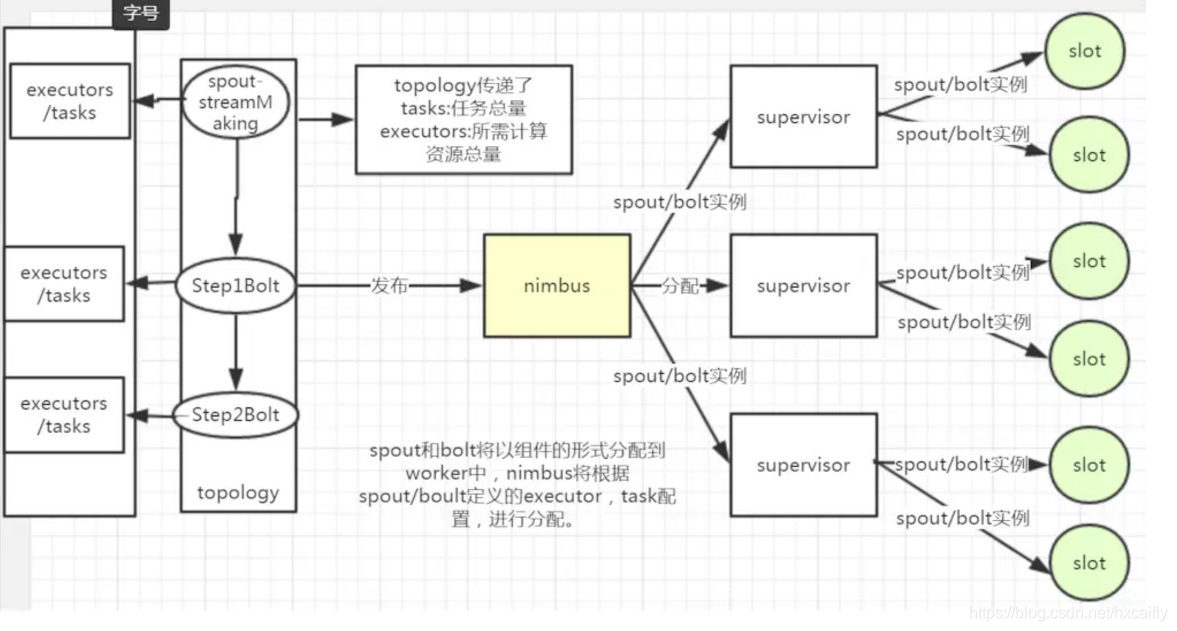
ask是执行的最小单元。spout/bolt实例在定义中指定了,要起多少task,以及多少executor。也即一个topology发布之前已经定义了task总量,和需要多少资源来执行我的task总量。nimbus将根据已有的计算资源进行分配。
下图中: nimbus左边代表着计算任务量,和所需计算配置
nimbus右边代表着计算资源
nimbus将根据计算资源信息,合理的分发计算任务量。
发布成功后,通过storm自带的UI功能,可以查看你发布的topology运行以及其中每个组件的分布执行情况。
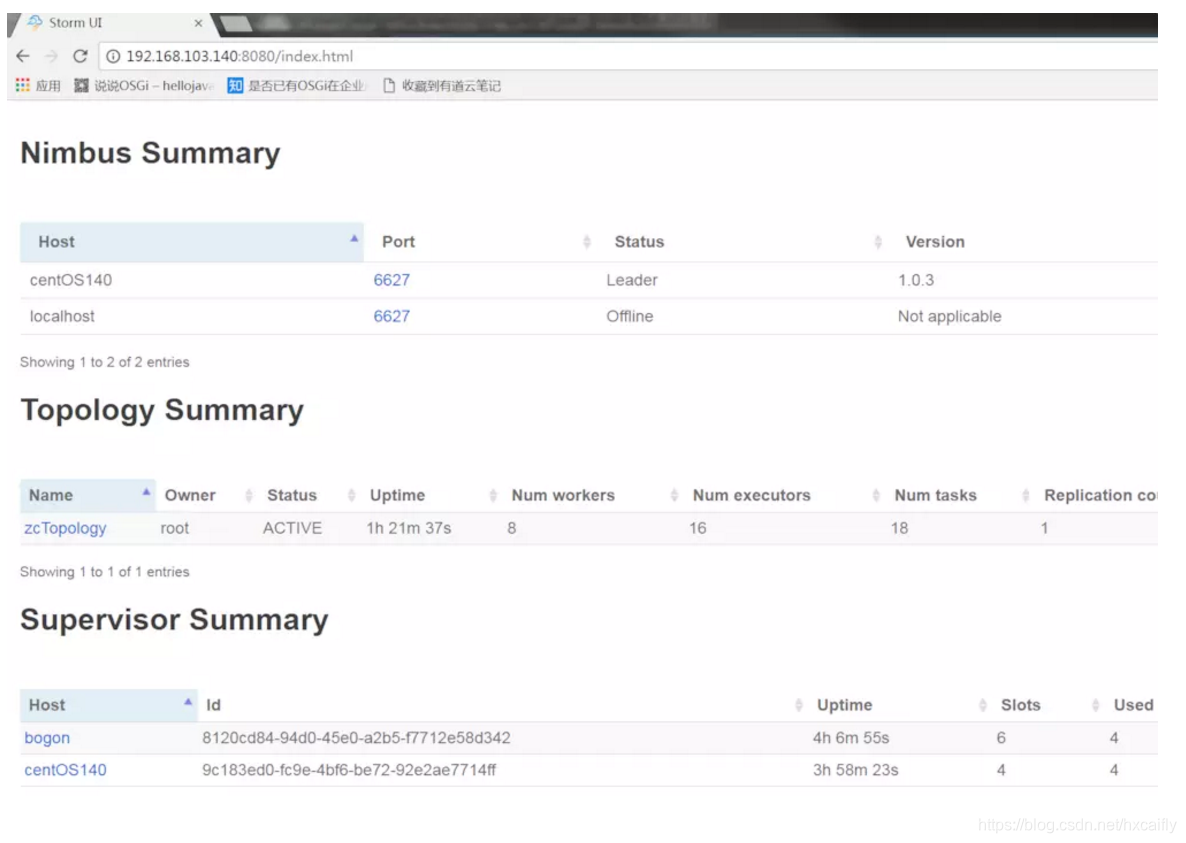
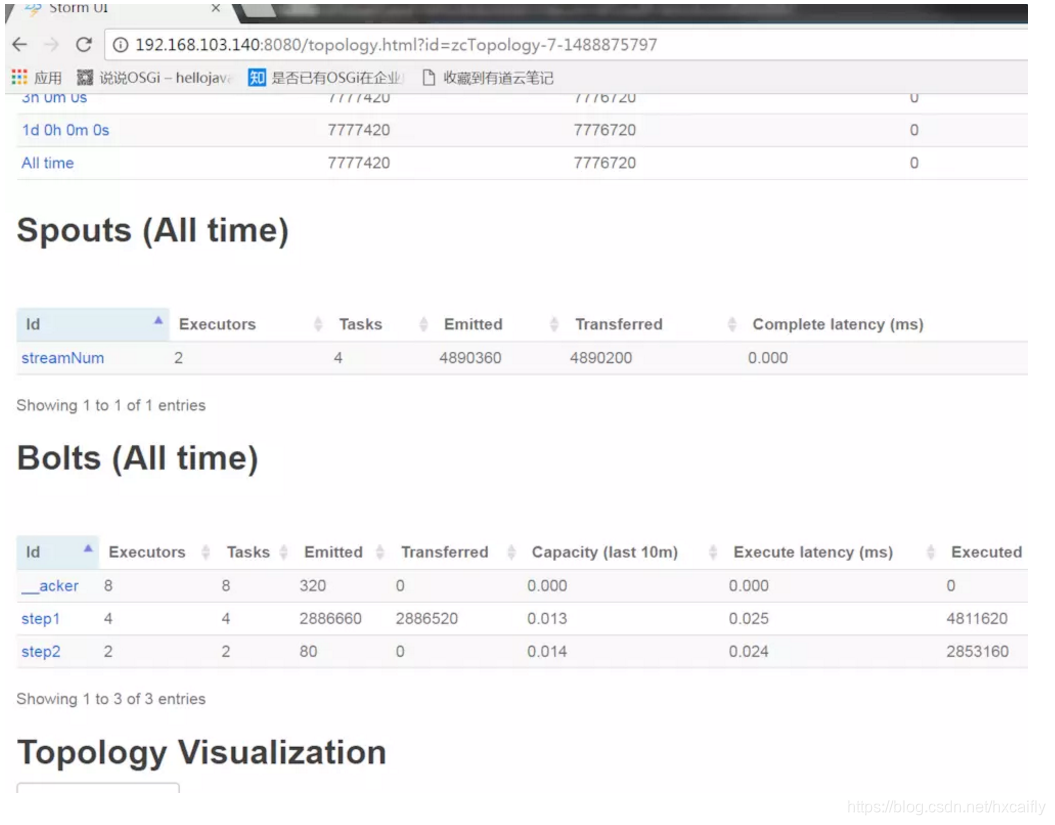
监控图像中清晰的显示了,目前部署的topology,以及topology中每个组件所分配的计算资源所在host,以及每个组件发射了多少tuple,接收了多少tuple,以及有多少个executor在并行执行。
本文讲述了storm内的基本元素以及基本概念,后续将讲述storm的重点配置信息,以及如何提高并发计算能力,窗口概念等高级特性,后续会进行源码分析,以及与其他实时计算中间件的比较。