下载和加载包
下载:install.packages(’包名称’)
加载:library(包名称)
更新:update.packages()
向量
创建向量:v = c(1,4,4,3,2,2,3) 或者 w = c(”apple”,”banana”,”orange”)
返回指定的元素:v[c(2,3,4)] 或者 v[2:4] 或者 v[c(2,4,3)]
删除指定的元素:v = v[-2] 或者 v = v[-2:-4]
选取符合条件的元素:v[v<3]
寻找指定的元素:which(v==3) 注意:放回的是下标
向量下标从1开始
> v=c(1,4,4,3,2,2,3)# 创建一个向量
> v[c(2,3,4)] # 向量切片
[1] 4 4 3
> v[2:4]
[1] 4 4 3
> v[c(2,4,3)]
[1] 4 3 4
> v[-2] # 向量删除序列号为2的值,返回新的向量,不改变原来的
[1] 1 4 3 2 2 3
> v[-2:-4]
[1] 1 2 2 3
> v[v<3] # 返回所有小于3的元素
[1] 1 2 2
> which(v==3)#返回 等于3的数的序列号
[1] 4 7
> which.max(v) # 返回最大值序列号 第一个
[1] 2
> which.min(v) # 返回最小值序列号 第一个
[1] 1
随机数
set.seed的作用是设置随机数种子,我们可以看到,相同的随机数种子所产生的随机数序列是有着一定的顺序的。具体可以看这篇
https://blog.csdn.net/vencent_cy/article/details/50350020
runif(n,min=0,max=1) (生成均匀分布随机数)n表示生成的随机数数量,min表示均匀分布的下限,max表示均匀分布的上限;若省略参数则默认生成[0,1]上的均匀分布随机数。
> set.seed(250) #随机数种子
> a = runif(3,min=0,max=100)
> a
[1] 26.54018 77.90907 16.90836
> set.seed(125)
> a = runif(3,min=0,max=100)
> a
[1] 82.46744 11.68510 29.97806
> a = runif(3,min=0,max=100)
> a
[1] 35.65607 96.51950 96.75605
> a = runif(3,min=0,max=100)
> a
[1] 53.30924 33.21555 65.38438
> set.seed(250)
> a = runif(3,min=0,max=100)
> a
[1] 26.54018 77.90907 16.90836
> a = runif(3,min=0,max=100)
> a
[1] 84.26782 79.99474 96.74011
> set.seed(125)
> a = runif(3,min=0,max=100)
> a
[1] 82.46744 11.68510 29.97806
> a = runif(3,min=0,max=100)
> a
[1] 35.65607 96.51950 96.75605
floor函数向下取整 直接去掉小数位
ceiling函数向上取整 只要有小数就进一
round保留指定位数的有效小数
> floor(a)
[1] 26 77 16
> ceiling(a)
[1] 27 78 17
> round(a,4)
[1] 26.5402 77.9091 16.9084
使用?round或??round可以查看文档帮助
读取文件
读取本地文件:
> read.csv(file=” /documents/rugby.txt”)
> read.table(file=” /documents/rugby.txt”)
读取网络文件
> read.csv('http://www.macalester.edu/~kaplan/ISM/datasets/swim100m.csv')
> read.table('http://www.macalester.edu/~kaplan/ISM/datasets/swim100m.csv')
两种方法区别

数据读完后,我们可以看到csv读取的数据只有62行,而table读取的数据只有1列
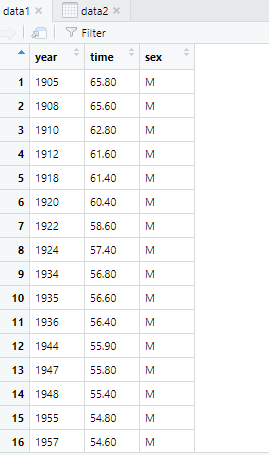
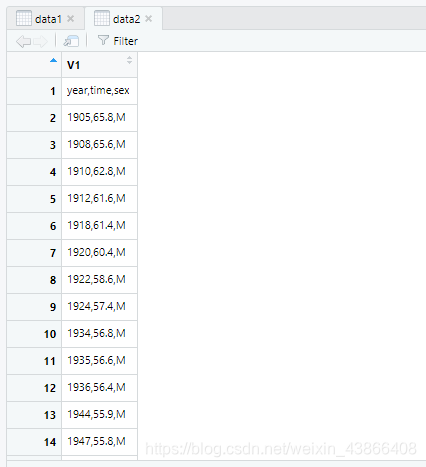
我们发现read.taoble在读取的时候将标题行(第一行也算入了数据中)
而read.csv确没有这样,他默认把第一行当做标题行来对待
attach可以讲上述数据中的列名转化为变量名来使用 ,如下
> data1 = read.csv('http://www.macalester.edu/~kaplan/ISM/datasets/swim100m.csv')
> year
错误: 找不到对象'year'
> attach(data1)
> year
[1] 1905 1908 1910 1912 1918 1920 1922 1924
[9] 1934 1935 1936 1944 1947 1948 1955 1957
[17] 1961 1964 1967 1968 1970 1972 1975 1976
[25] 1981 1985 1986 1988 1994 2000 2000 1908
[33] 1910 1911 1912 1915 1920 1923 1924 1926
[41] 1929 1930 1931 1933 1934 1936 1956 1958
[49] 1960 1962 1964 1972 1973 1974 1976 1978
[57] 1980 1986 1992 1994 2000 2004
简单画图
> set.seed(123)
> x=rnorm(100,mean = 100,sd = 10)#正态分布,平均数100,反差是10
> set.seed(234)
> y=rnorm(100,mean = 100,sd = 10)
> hist(x,breaks = 20)
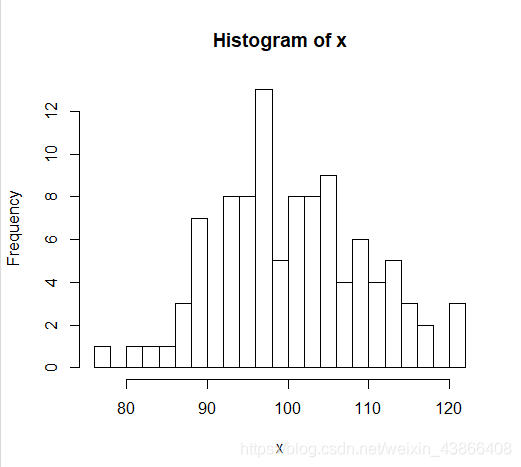
直方图的绘制
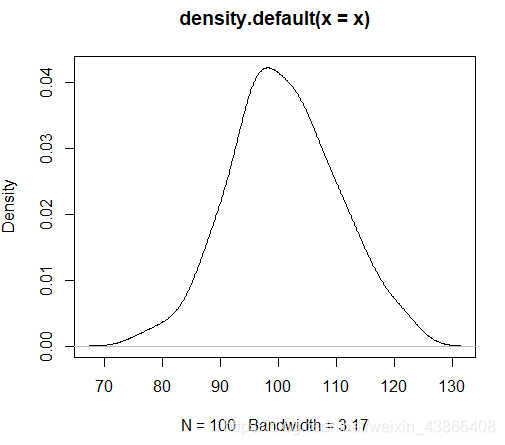
plot(density(x)) #density计算密度
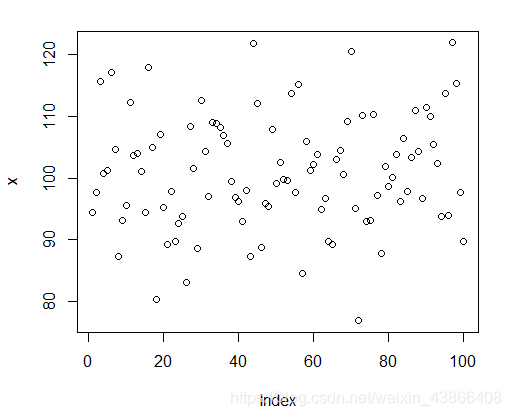
plot(x) # 散点图
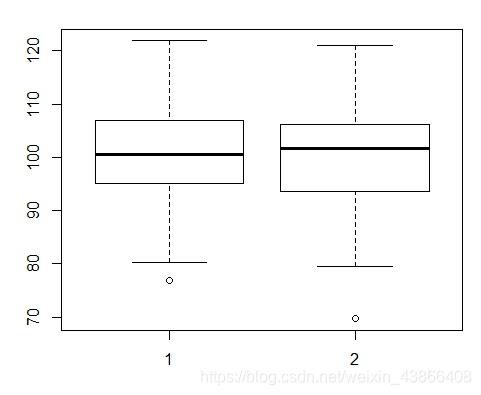
boxplot(x,y) # 箱图
QQ图
QQ图可以帮我们鉴别样本的分布是否近似于某种类型的分布
qqnorm函数绘制正态分布的QQ图qqline函数用于绘制QQ图的近似直线,其解析式为y=ax+b,a是正态分布的标准差,b为均值
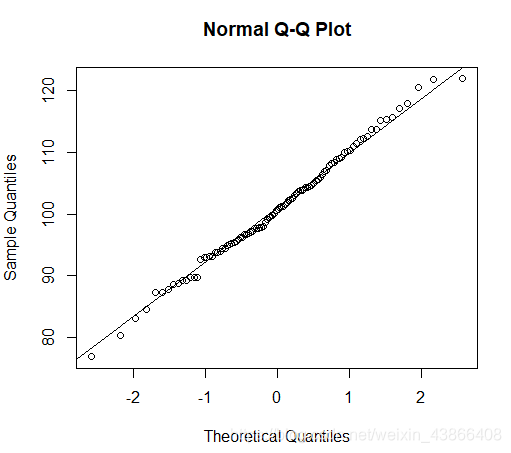
qqplot(x,y)