集中趋势
定义
反映的是一组数据向某一中心聚拢的趋势。
度量值
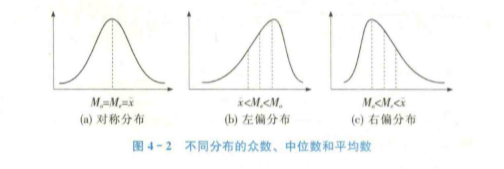
- 众数:反应一组数据的最高峰 ,适用于分类数据。
- 中位数:反应的是一组数据的中间值 ,适用于顺序数据。
- 平均数:全部数据的加权平均值或者简单平均值,适用于顺序数据和数值数据。
- 四分位数:四分点,排序后处于25%和75%的数值,,适用于顺序数据。
python实现
import pandas as pd
import numpy as np
df=pd.read_csv(r'C:\Users\admin\Desktop\test.csv')
yuwen=list(df['语文'])
avg_yw=np.mean(yuwen)
mid_yw=np.median(yuwen)
cur_yw=np.argmax(np.bincount(yuwen))
qu_yw_1=np.quantile(yuwen,0.25)
qu_yw_2=np.quantile(yuwen,0.75)
print("平均值:",avg_yw)
print("中位数:",mid_yw)
print("众数:",cur_yw)
print("四分位25%",qu_yw_1)
print("四分位75%",qu_yw_2)

离散程度
定义
反应的是一组数据远离中心值的趋势。
度量值
- 异众比例:频数/总频数*100%,适用于分类数据。
- 四分位差:上四分位值-下四分位值,反映了中间50%数值的离散程度,适用于顺序数据。
- 极差:最大值-最小值,反映了整体数值的离散程度,容易受极值影响,适用于数值数据。
- 平均差:各变量与平均值离差绝对值的平均数,以平均数为中心,反应每个数据与平均数的平均离散程度,适用于数值数据。
- 方差:各变量与平均值离差平方的平均数,最常反应离散程度的测量值,适用于数值数据。
- 标准差:根号下方差,与方差区别在于标准差有量纲,适用于数值数据。
- 离散系数:标准差/平均数,主要反应的是不同样本的离散程度,适用于样本间的相对离散程度。
python实现
import pandas as pd
import numpy as np
df=pd.read_csv(r'C:\Users\admin\Desktop\test.csv')
yuwen=list(df['语文'])
qu_yw_1=np.quantile(yuwen,0.25)
qu_yw_2=np.quantile(yuwen,0.75)
max_yw=np.max(yuwen)
min_yw=np.min(yuwen)
cov_yw=np.cov(yuwen)
std_yw=np.std(yuwen)
print("四分位差:",qu_yw_2-qu_yw_1)
print("极差:",max_yw-min_yw)
print("方差:",cov_yw)
print("标准差:",std_yw)

分布形状
定义
偏态和峰态主要反应的是数据分布形态是否对称、偏斜的程度以及分布的扁平程度等。
度量值
- 偏态系数:对于数据对称性的度量值(> 0,右偏;< 0,左偏;= 0,正态)
- 峰态系数:相对于正态分布而言的度量值(= 3,正态;> 3,厚态;< 3,瘦态)
python实现
import pandas as pd
import numpy as np
df=pd.read_csv(r'C:\Users\admin\Desktop\test.csv')
yuwen=list(df['语文'])
avg_yw=np.mean(yuwen)
cov_yw=np.cov(yuwen)
sc_yw=np.mean((yuwen-avg_yw)**3)
ku_yw=np.mean((yuwen-avg_yw)**4)/pow(cov_yw,2)
print("偏斜度",sc_yw)
print("峰度",ku_yw)

从数据上看,整体数据分布右偏,瘦尾。
