Abstract
跨场景人群计数是一个困难任务。目前大多数人群计数方法当应用到一个从未见过的场景中时,性能都会有大幅下降。我们提出了一种CNN,可以被选择训练来进行人群密度和人群计数,这种可切换式的学习途径能获得更好的局部最优解。针对从未见过的目标人群场景,我们提出了一种数据驱动的方法微调训练好的CNN模型来达到目的。提出了一个新的数据集。
Introduction
人群计数是一个具有挑战性的任务,因为有严重的遮挡,场景畸变和不同的人群分布。从一个特定场景中训练出来的人群计数模型只能用于相同的场景。给一个新的场景或者改变场景布局,模型就需要重新训练。很少研究涉及到跨场景人群计数,尽管这很重要。
在这篇论文中,我们提出了一个跨场景人群计数框架。对于新的场景不需要额外的注释。我们的目标是学习出一个从图像到人群数量的映射,然后将这个映射用在新的场景中。为了实现这个目标,我们面临的困难有:
1.找出有效的特征。之前的工作用的都是手工设计的特征。
2.不同的场景有不同的视角畸变,人群分配和灯光情况。
3.最近许多研究中,前景分割式不可缺少的,但是人群分割是很难的,而且不能准确的获得,现场也有可能有静止不动的人。
4.现在的数据集不能支持和评估跨场景计数研究。
对于这些问题,我们提出了CNN方法来进行跨场景计数。CNN用固定数据集训练的,我们引入了一种数据驱动的方法去微调CNN网络使其适应新的目标场景。我们的设计优点是:
1.我们的CNN模型是通过一个可切换的过程训练的,有两个目的(人群密度和人群计数),这两个不同但是相关的目的可以互相帮助来获得更好的局部最优。
2.目标场景不需要额外的标注。
3.该框架不依赖于前景分割结果,因为我们的方法只考虑外观信息。
4.介绍了一个新的数据集。
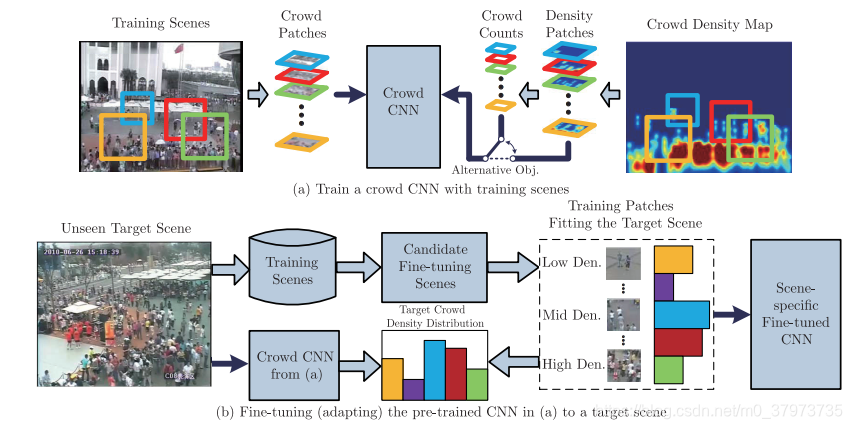
Method
Normalized crowd density map for training
我们的主要目的是获得一个映射F:X一>D,X是从训练集中提取出来的低级特征的集合,D是图像的人群密度图。假定每个行人都被标注了,密度图可以通过行人的空间位置、人的身体形状和图像的视角畸变创建出来。从训练图像中随机选取出局部图像作为训练集,并将相应斑块的密度图作为CNN模型的真值图。在被选择的局部图像中人群总数是通过整合密度图来获得的。
视角归一化是对于估计行人尺度是必须的。我们首先随机选取几个人并将其标注。假设人的平均身高是175cm,视角图可以用下图表示:
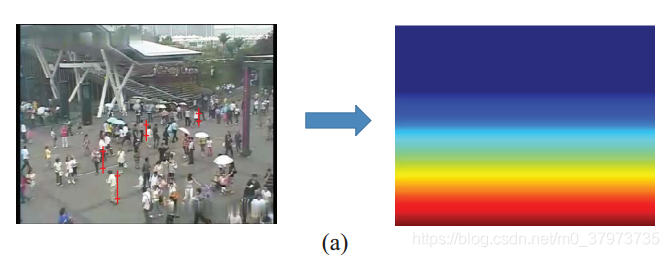
视角图中的像素值表示在这个位置上实际场景中的一米转化为几个像素(假设像素值为100,表示在该区域,100个像素代表实际场景中的1米,即用简单的比例尺方法建立了图像从上到下的比例关系)
Crowd CNN model
这个CNN网络的总览如下图所示:
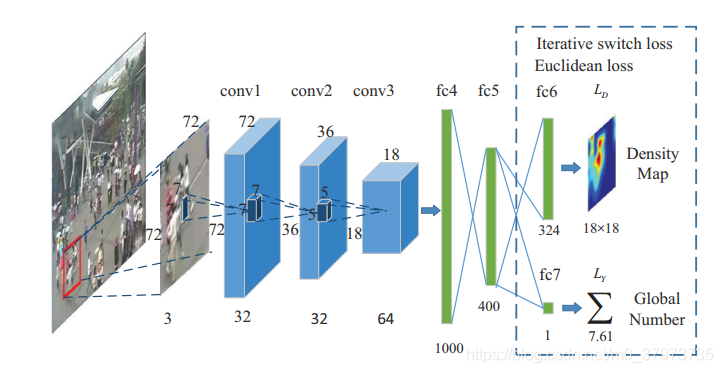
将训练图像裁剪成小块输入,为了获得同一尺度的行人,不同位置图像块的尺寸应该根据它中心像素的视角值得出(即通过上文中的视角归一化图),如下图所示:

网络包含了三个卷积层、三个全连接层。Conv是7×7×3(因为是彩色图像),32通道。Conv2为7×7×32,32通道。Conv3是5×5×32,64通道。Conv1和Conv2后有2×2的最大池化层。每个卷积层和全连接层后都有激活函数ReLU。
我们引入了一个迭代的可切换的过程可选择地最优化估计密度图和计数。主要任务是估计输入Patch中的人群密度。因为有两个最大池化层,导致输出的密度图像降采样到了18×18。密度图中包含了丰富且详细的信息。总数计算是第二个工作,通过整合局部密度图来获得。两个任务相互帮助。损失函数是常用的欧几里得方法。
因为密度图可以提供更多的空间信息,所以将密度图估计作为第一个任务。当第一个目标收敛后,模型开始对第二个目标(人群计数)进行优化,这个相比于第一个目标要简单的多。优化过程中应该注意保证这两个目标的尺度一致。也就是通过分别优化两个目标,达到整体优化的目的。
Nonparametric fine-tuning for target scene
由于不同的场景中,观察角度、尺度和密度分布都不同。为了将模型应用到未见过的场景中,我们设计了一种不涉及参数的微调方案。方法是:给定一个未见过场景中的目标视频。从训练过的场景集中找到具有相似属性的场景,将其加到训练样本中对模型进行微调。方法分为两个部分:候选场景检索和局部图像检索。
Candidate scene retrieval
场景的视角和规模是影响人群外观的主要因素。透视图可以直接表示尺度和比例尺。因此,非参数微调方法的第一步重点是从所有训练场景中检索与目标场景具有相似透视图的训练场景。检索需要一个标准,这里的标准就是垂直方向的描述符。因为视角一般会随着垂直方向发生变化。最终检索出透视图最相似的20个场景进行下一步。
Local patch retrieval
第二步是从候选场景中选择与测试场景密度分布相似的patch。除了视角和尺度,人群密度分布也会影响人群的外观形态。密度越高,闭塞越严重,只能观察到头肩。相反,在稀疏的人群中,行人呈现出完整的体型。因此,我们需要检索出与目标场景patches密度相似的patches,用这些patches对模型进行训练来微调。
那么如何获得目标场景patches的密度呢。文中的方法是直接用之前训练好的模型进行预测。得出目标场景patches中人数的分布直方图。然后从检索到的训练场景中随机选取patch,控制不同密度的patch的数量,使其与目标场景的密度分布相匹配。至此,选出的patches与目标图像具有相似的尺度、角度和分布密度,用这些数据训练进行微调。
创新点
1.采用透视图的方法来解决尺度问题。往常也有对网络改进以解决尺度问题的方法。但是透视图的作用还包括找出与目标场景尺度相似的场景。
2.提出了一种跨场景人群密度估计和计数方法。实质上是在训练集中拼凑出一个与目标场景相似的场景,以此来对模型进行微调,等于“将目标场景加入训练集中”。
3.多任务方法。人群密度和人群计数是两个相关的任务,模型分别对这两个任务进行优化以获得整体的优化。
不足之处
1.以人的身高为基准进行比例尺估算,可能不准,但是似乎也没有别的方法。
2.比较依赖数据集,因为要进行场景检索。