简而言之,爬虫就是抓取网页中的数据。
一、爬虫的工作流程
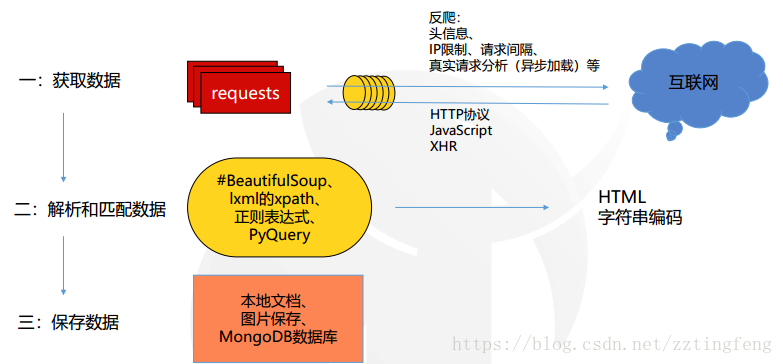
二、浏览器和服务器交互过程
浏览器和服务器通过HTTP请求建立联系
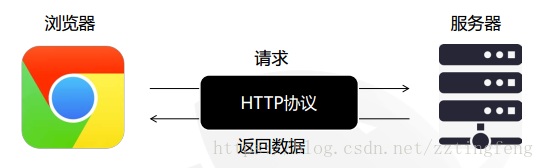
客户端和服务器通过三次握手、四次挥手建立联系
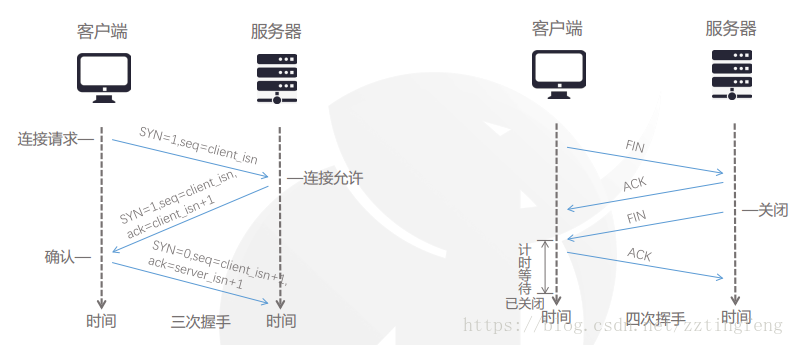
服务器通过浏览器将数据返回到计算机页面
三、python requests库
1、安装Requests
pip install requests2、导入Requests
>>> import requests3、 requests方法
requests.get() #获取HTML网页的主要方法,对应HTTP的GET4、 获取流程
url="http://www.mingchaonaxieshier.com/hong-wu-da-di-qianyan.html"
#使用get方法获取数据,返回包含网页数据的response响应,超时时间测试
r = requests.get(url,timeout=XXX))
#http请求的返回状态, 200表示连接成功
r.status_code
#返回对象的文本内容
r.text
#返回对象的二进制形式
r.content
#分析返回对象的编码方式
r.encoding
#响应内容编码方式(备选编码方式)
r.appearent_encoding
#抛出异常
raise_for_status四、解析和匹配数据
三种方法:BeautifulSoup、lxml的xpath、正则表达式
效率比较:
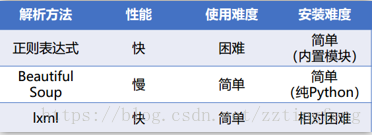
2.1 xpath
2.1.1 导入lxml,返回xml结构:
from lxml import etree
html ='''
#省略
'''
s = etree.HTML(html)
print(s.xpath())2.2.2 xpath的几个方法
#获取文本内容
text()
#获取注释
comment()
@xx#获取其它任何属性 @href、@src、@value
#获取某个标签下所有的文本(包括子标签下的文本),使用string
string()
#匹配字符串前面相等
starts-with
#匹配任何位置相等
containsxpath常用的符号:

代码:
import requests
from lxml import etree
url = 'https://www.douban.com/note/667285773/'
r = requests.get(url).text
s = etree.HTML(r)
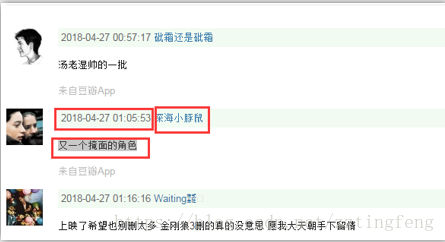
print(s.xpath('//div[@class="author"]/span/text()')[1])
print(s.xpath('//div[@class="author"]/a/text()')[1])
print(s.xpath('//div[@class="content report-comment"]/p/text()')[1])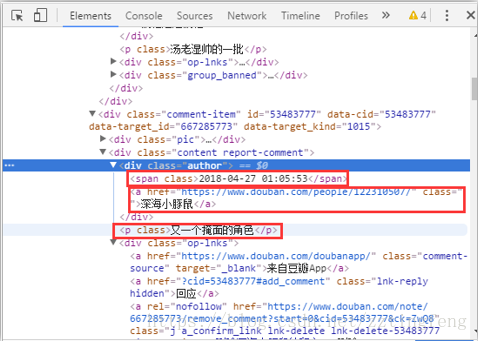

2.3 正则表达式
几个常见的正则表达式如下:

3、Beautiful Soup
Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据。
import requests
import bs4
from bs4 import BeautifulSoup
r=requests.get("http://quotes.toscrape.com/")
soup = BeautifulSoup(r.text,'lxml')
soup.title
soup.head.children
soup.find_all('a')
a=soup.find_all('small',attrs={'class':'author'})
soup.find('small',attrs={'class':'author'}).get_text()
soup.find('div',attrs={'class':'quote'}).get_text()
for i in range(len(a)):
print(a[i].get_text())