爬取高考志愿填报系统(https://gkcx.eol.cn/)的所有学校
(一)、第一种方法
1.分析请求
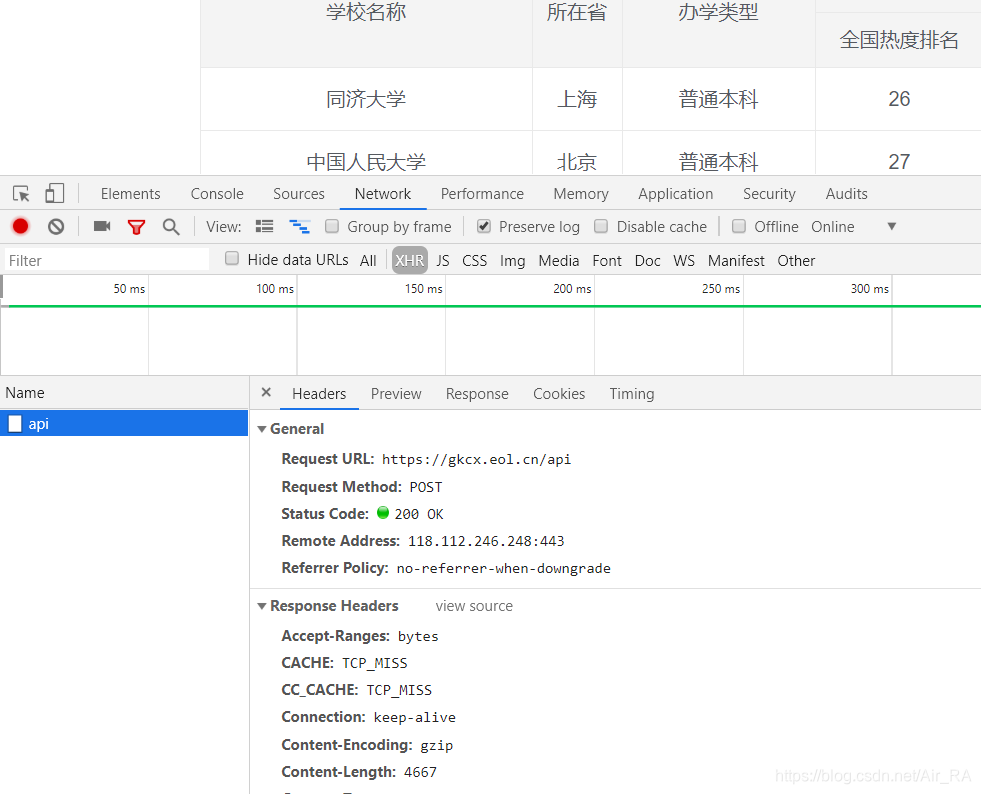
2.构造url
base_url='https://gkcx.eol.cn/api?'
data={
'admissions': "",
'central': "",
'department': "",
'dual_class': "",
'f211': "",
'f985': "",
'is_dual_class': "",
'keyword': "",
'page': 1,
'province_id': "",
'request_type': 1,
'school_type': "",
'size': 20,
'sort': "view_total",
'type': "",
'uri': "gksjk/api/school/hotlists"
}
url=base_url+urlencode(data)结果:
https://gkcx.eol.cn/api?admissions=¢ral=&department=&dual_class=&f211=&f985=&is_dual_class=&keyword=&page=1&province_id=&request_type=1&school_type=&size=20&sort=view_total&type=&uri=gksjk%2Fapi%2Fschool%2Fhotlists
打开这个url:

解析json:
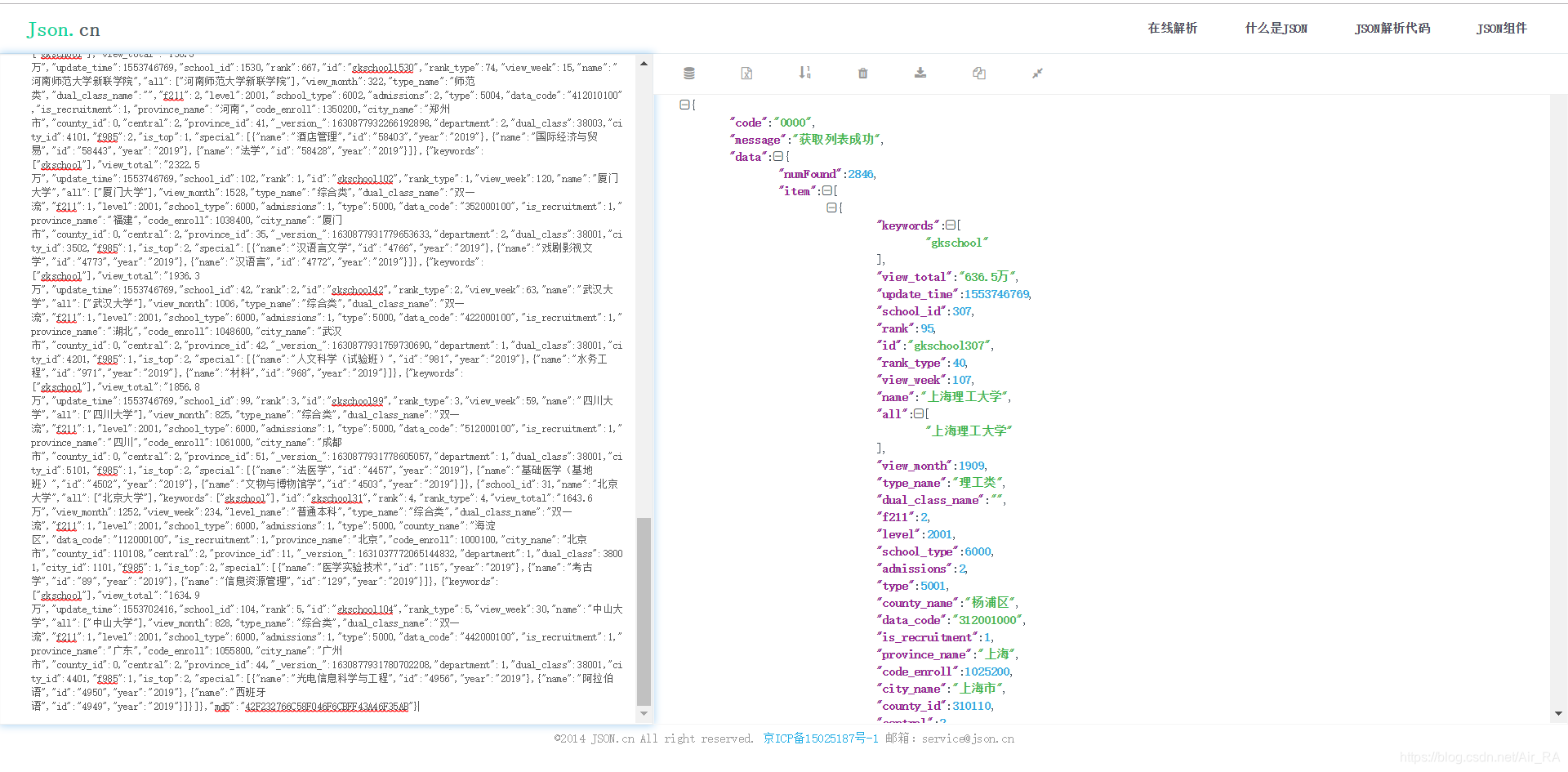
3.提取数据:
items=json.get('data').get('item')
item_list=[]
for item in items:
a_dict={}
a_dict['name']=item.get('name')
a_dict['type']=item.get('dual_class_name')
a_dict['origin']=item.get('province_name')
item_list.append(a_dict)结果:
[{'name': '上海理工大学', 'type': '', 'origin': '上海'}, {'name': '上海对外经贸大学', 'type': '', 'origin': '上海'}, {'name': '重庆邮电大学', 'type': '', 'origin': '重庆'}, {'name': '重庆邮电大学移通学院', 'type': '', 'origin': '重庆'}, {'name': '重庆师范大学涉外商贸学院', 'type': '', 'origin': '重庆'}, {'name': '重庆工商大学融智学院', 'type': '', 'origin': '重庆'}, {'name': '黑龙江东方学院', 'type': '', 'origin': '黑龙江'}, {'name': '重庆电子工程职业学院', 'type': '', 'origin': '重庆'}, {'name': '黑龙江外国语学院', 'type': '', 'origin': '黑龙江'}, {'name': '广州工商学院', 'type': '', 'origin': '广东'}, {'name': '河北环境工程学院', 'type': '', 'origin': '河北'}, {'name': '重庆交通职业学院', 'type': '', 'origin': '重庆'}, {'name': '河北旅游职业学院', 'type': '', 'origin': '河北'}, {'name': '承德护理职业学院', 'type': '', 'origin': '河北'}, {'name': '河南师范大学新联学院', 'type': '', 'origin': '河南'}, {'name': '厦门大学', 'type': '双一流', 'origin': '福建'}, {'name': '武汉大学', 'type': '双一流', 'origin': '湖北'}, {'name': '四川大学', 'type': '双一流', 'origin': '四川'}, {'name': '北京大学', 'type': '双一流', 'origin': '北京'}, {'name': '中山大学', 'type': '双一流', 'origin': '广东'}]
4.源码
import requests
from urllib.parse import urlencode
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36",
'Host': 'gkcx.eol.cn',
'Referer': 'https://gkcx.eol.cn/school/search'
}
def parse_data(json):
items=json.get('data').get('item')
item_list=[]
for item in items:
a_dict={}
a_dict['name']=item.get('name')
a_dict['type']=item.get('dual_class_name')
a_dict['origin']=item.get('province_name')
item_list.append(a_dict)
return item_list
def gethtml(page):
base_url='https://gkcx.eol.cn/api?'
data={
'admissions': "",
'central': "",
'department': "",
'dual_class': "",
'f211': "",
'f985': "",
'is_dual_class': "",
'keyword': "",
'page': page,
'province_id': "",
'request_type': 1,
'school_type': "",
'size': 20,
'sort': "view_total",
'type': "",
'uri': "gksjk/api/school/hotlists"
}
url=base_url+urlencode(data)
try:
res=requests.get(url,headers=headers)
if res.status_code==200:
data=parse_data(res.json())
print(data)
except:
print('error')
if __name__ == '__main__':
for i in range(1,144):
gethtml(i)(二)、第二种方法:
import requests
def parse_data(json):
items=json.get('data').get('item')
item_list=[]
for item in items:
a_dict={}
a_dict['name']=item.get('name')
a_dict['type']=item.get('dual_class_name')
a_dict['origin']=item.get('province_name')
# print(a_dict)
item_list.append(a_dict)
print(item_list)
return item_list
def gethtml(page):
url='https://gkcx.eol.cn/api'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"
}
data={
'admissions': "",
'central': "",
'department': "",
'dual_class': "",
'f211': "",
'f985': "",
'is_dual_class': "",
'keyword': "",
'page': page,
'province_id': "",
'request_type': 1,
'school_type': "",
'size': 20,
'sort': "view_total",
'type': "",
'uri': "gksjk/api/school/hotlists"
}
res=requests.get(url,headers=headers,params=data)
# print(res.status_code)
parse_data(res.json())
if __name__ == '__main__':
for i in range(1,144):
gethtml(i)