有许多正则化策略。
有些策略向机器学习模型添加限制参数值的额外约束。
有些策略向目标函数增加额外项来对参数值进行软约束
有时候,这些约束和惩罚被设计为编码特定类型的先验知识;
其他时候,这些约束和惩罚被设计为偏好简单模型,以便提高泛化能力。
有时,惩罚和和约束对于确定欠定的问题是必要的
其他形式的正则化,如被称为集成的方法,则结合多个假说来解释训练数据
估计的正则化以偏差的增加换取方差的减少。一个有效的正则化能显著减少方差而不过度增加偏差。
前述泛化和过拟合,主要侧重模型训练的3种情况:
(1)不包括真实的数据生成过程——对应欠拟合和含有偏差的情况
(2)匹配真实数据生成过程
(3)除了包括真实的数据生成过程,还包括许多其他可能的生成过程——方差(而不是偏差)主导的过拟合
正则化的目标是使模型从第三种情况转化为第二种情况
从最小化泛化误差的意义上,最好的拟合模型是一个适当正则化的大型模型。
1、参数范数惩罚
![]()
在神经网络中,通常只对权重做惩罚而不对偏置做正则惩罚,一是每个偏置仅控制一个单变量,不对其正则化也不会导致太大的方差。二是正则化偏置参数可能会导致明显的欠拟合。
在神经网络情况下,有时希望对网络的每一层使用单独的惩罚,并分配不同的α系数。
θ表示所有参数,w表示应受范数惩罚影响的权重
![]() 参数正则化
参数正则化
通常被称为权重衰减的![]() 参数范数惩罚
参数范数惩罚
通过向目标函数添加一个正则项 ![]() ,使权重更加接近原点(更一般地,可以将参数正则化为接近空间中的任意特定点)。也被称为岭回归或Tikhonov正则。
,使权重更加接近原点(更一般地,可以将参数正则化为接近空间中的任意特定点)。也被称为岭回归或Tikhonov正则。
目标函数:![]()
梯度:![]()
梯度更新:![]()
加入权重衰减后,每步执行通常的梯度更新之前先收缩权重向量
![]()
![]()
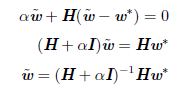
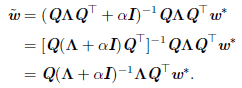
权重衰减的效果是沿着由H 的特征向量所定义的轴缩放w*。具体来说,我们会根据 ![]() 因子缩放与H 第i 个特征向量对齐的w* 的分量。
因子缩放与H 第i 个特征向量对齐的w* 的分量。
沿着 H 特征值较大的方向 (如 λi ≫ α ) 正则化的影响较小。而 λi≪ α 的分量将会收缩到几乎为零。

例,线性回归:
代价函数:![]()
加入L2正则项:![]()
解从![]()
变为 ![]()
![]() 矩阵的对角项对应每个输入特征的方差。
矩阵的对角项对应每个输入特征的方差。
L2正则化能让学习算法“感知”到具有较高方差的输入x,因此与输出目标的协方差较小(相对增加方差)的特征的权重将会收缩。
只有在显著减小目标函数方向上的参数会保留得相对完好。在无助于目标函数减小的方向(对应Hessian 矩阵较小的特征值)上改变参数不会显著增加梯度。这种不重要方向对应的分量会在训练过程中因正则化而衰减掉。
![]() 正则化
正则化
![]()
![]()
求梯度:![]()
![]() 正则化不线性缩放
正则化不线性缩放 ![]() ,而是添加了一项常数
,而是添加了一项常数
一个解析解形式:![]()

相比L2正则化,![]() 正则化会产生更稀疏的解,即最优值中的一些参数为0。
正则化会产生更稀疏的解,即最优值中的一些参数为0。
由![]() 正则化导出的稀疏性质被广泛用于特征选择机制。
正则化导出的稀疏性质被广泛用于特征选择机制。
许多正则化策略可以被解释为MAP贝叶斯推断,特别是L2正则化相当于权重是高斯先验的MAP贝叶斯推断。对于L1正则化,用于正则化代价函数的惩罚项 ![]() 与通过MAP贝叶斯推断最大化的对数先验项是等价的(
与通过MAP贝叶斯推断最大化的对数先验项是等价的( ![]() ,并且权重先验是各向同性的拉普拉斯分布):
,并且权重先验是各向同性的拉普拉斯分布):
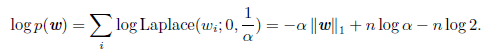
2、作为约束的范数惩罚
约束 ![]() 小于某个常数k:
小于某个常数k:
![]()
在所有过程中 α 在Ω(θ) > k 时必须增加,在Ω(θ) < k 时必须减小。所有正值的 α 都鼓励Ω(θ) 收缩。最优值 α* 也将鼓励Ω(θ) 收缩,但不会强到使得 Ω(θ) 小于k。
3、正则化和欠约束问题
![]() 求逆。
求逆。
当数据生成分布在一些方向上确实没有差异时,或因为例子较少(即相对输入特征的维数来说)而在一些方向上没有观察到方差时,这个矩阵就是奇异的。这种情况下,正则化的许多形式对应求逆 ![]() 。这个正则化矩阵可以保证是可逆的。
。这个正则化矩阵可以保证是可逆的。
大多数形式的正则化能够保证应用于欠定问题的迭代方法收敛。例如当似然的斜率等于权重衰减的系数时,权重衰减将阻止梯度下降继续增加权重的大小。
4、数据集增强
创建假数据并添加到训练集中
数据集增强对一个具体的分类问题来说是特别有效的方法:对象识别。图像是高维的并包括各种巨大的变化因素,其中有许多可以轻易地模拟。即使模型已使用卷积和池化技术(第九章)对部分平移保持不变,沿训练图像每个方向平移几个像素的操作通常可以大大改善泛化。许多其他操作如旋转图像或缩放图像也已被证明非常有效。
在神经网络的输入层注入噪声可看作是数据增强的一种方式。
向隐藏单元施加噪声也是可行的,这可以被看作在多个抽象层上进行的数据集增强
神经网络被证明对噪声不是非常健壮。
改善神经网络健壮性的方法之一是简单地将随机噪声添加到输入再进行训练。向隐藏单元施加噪声也可行,这可被看作在多个抽象层上进行的数据集增强。
5、噪声鲁棒性
将噪声用于输入,作为数据集增强策略。对于某些模型而言,向输入添加方差极小的噪声等价于对权重施加范数惩罚。在一把情况下,注入噪声远比简答地收缩参数强大,特别是噪声被添加到隐藏单元时会更加强大。
另一种正则化模型的噪声使用方式是将其加到权重。可被解释为关于权重的贝叶斯推断的随即实现。贝叶斯学习方法将权重视为不确定的,向权重添加噪声是反映这种不确定性的一种实用的随机方法。
在某些假设下,施加于权重的噪声可以被解释为与更传统的正则化形式等同,鼓励要学习的函数保持稳定。
向输出目标注入噪声:大多数数据集的y标签都有一定错误。错误的y不利于最大化log p(y|x)。避免这种情况的一种方法是显式地对标签上的噪声进行建模。
,标签平滑 通过把确切分类目标从0 和1 替换成![]() 和1 - ϵ,正则化具有k 个输出的softmax 函数的模型。标准交叉熵损失可以用在这些非确切目标的输出上。使用softmax 函数和明确目标的最大似然学习可能永远不会收敛——softmax 函数永远无法真正预测0 概率或1 概率,因此它会继续学习越来越大的权重,使预测更极端。使用如权重衰减等其他正则化策略能够防止这种情况。标签平滑的优势是能够防止模型追求确切概率而不影响模型学习正确分类。
和1 - ϵ,正则化具有k 个输出的softmax 函数的模型。标准交叉熵损失可以用在这些非确切目标的输出上。使用softmax 函数和明确目标的最大似然学习可能永远不会收敛——softmax 函数永远无法真正预测0 概率或1 概率,因此它会继续学习越来越大的权重,使预测更极端。使用如权重衰减等其他正则化策略能够防止这种情况。标签平滑的优势是能够防止模型追求确切概率而不影响模型学习正确分类。
6、半监督学习
我们可以构建这样一个模型,其中生成模型P(x) 或P(x; y) 与判别模型P(y | x)共享参数,而不用分离无监督和监督部分。我们权衡监督模型准则 -log P(y | x) 和无监督或生成模型准则(如 -log P(x) 或 -log P(x; y))。生成模型准则表达了对监督学习问题解的特殊形式的先验知识,即P(x) 的结构通过某种共享参数的方式连接到P(y | x)。通过控制在总准则中的生成准则,我们可以获得比纯生成或纯判别训练准则更好的权衡
7、多任务学习
多任务学习是通过合并几个任务中的样例(可以视为对参数施加的软约束)来提高泛化的一种方式。

因为共享参数,其统计强度可大大提高。
8、提前终止
当验证集上的误差在事先指定的循环次数内没有进一步改善时,算法就会终止,这种策略被称为提前终止。这可能是深度学习中最常用的正则化形式。有效、简单。
提前终止是非常高效的超参数选择算法。
提前终止可单独使用或可与其他的正则化策略结合使用。

缺点:没有办法知道重新训练时,对参数进行相同次数的更新和对数据集进行相同次数的遍历哪一个更好。

缺点:验证集的目标不一定能达到之前的目标值,所以这种策略甚至不能保证终止。
提前终止为何具有正则化效果:
提前终止可以将优化过程的参数空间限制在初始参数值θ0的小邻域内。

在大曲率(目标函数)方向上的参数值受正则化影响小于小曲率方向。在提前终止的情况下,这实际意味着在大曲率方向的参数比较小曲率方向的参数更早地学习到。
长度为t的轨迹结束于L2正则化目标的极小点。
9、参数绑定与参数共享
上述讨论对参数添加约束或惩罚时,一直是相对于固定的区域或点,如 L2正则化对参数偏离零的固定值进行惩罚
有时需要其他方式来表达对模型参数适当值的先验知识,如想表达某些参数应当彼此接近,即![]() ,
,![]() 应该与
应该与![]() 接近,则参数范数惩罚:
接近,则参数范数惩罚:![]()
正则化一个模型(监督模式下训练的分类器)的参数,使其接近另一个无监督模式下训练的模型(捕捉观察到的输入数据的分布)的参数。构造的这种架构使得分类模型中的许多参数能与无监督模型中对应的参数匹配。
更流行的方法是使用约束:强迫某些参数相等。由于我们将各种模型或模型组件解释为共享唯一的一组参数,这种正则化方法通常被称为参数共享(parameter sharing)。和正则化参数使其接近(通过范数惩罚)相比,参数共享的一个显著优点是,只有参数(唯一一个集合)的子集需要被存储在内存中。对于某些特定模型,如卷积神经网络,这可能可以显著减少模型所占用的内存。
10、稀疏表示
还有一些其他方法通过激活值的硬性约束来获得表示稀疏。例如,正交匹配追踪通过解决以下约束优化问题将输入值x 编码成表示h:![]()
其中![]() 是h 中非零项的个数。当W 被约束为正交时,我们可以高效地解决这个问题。这种方法通常被称为OMP-k,通过k 指定允许的非零特征数量。OMP-1 可以成为深度架构中非常有效的特征提取器。
是h 中非零项的个数。当W 被约束为正交时,我们可以高效地解决这个问题。这种方法通常被称为OMP-k,通过k 指定允许的非零特征数量。OMP-1 可以成为深度架构中非常有效的特征提取器。
11、Bagging 和其他集成方法
模型平均(model averaging)奏效的原因是不同的模型通常不会在测试集上产生完全相同的误差。
假设有k 个回归模型。假设每个模型在每个例子上的误差是ϵi,这个误差服从零均值方差为![]() 且协方差为
且协方差为![]() 的多维正态分布。通过所有集成模型的平均预测所得误差是
的多维正态分布。通过所有集成模型的平均预测所得误差是![]() 。集成预测器平方误差的期望是
。集成预测器平方误差的期望是
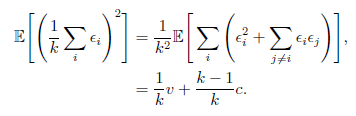
在误差完全相关即c = v 的情况下,均方误差减少到v,所以模型平均没有任何帮助。在错误完全不相关即c = 0 的情况下,该集成平方误差的期望仅为1/k *v。这意味着集成平方误差的期望会随着集成规模增大而线性减小。
神经网络能找到足够多的不同的解,意味着他们可以从模型平均中受益(即使所有模型都在同一数据集上训练)。神经网络中随机初始化的差异、小批量的随机选择、超参数的差异或不同输出的非确定性实现往往足以使得集成中的不同成员具有部分独立的误差。
不是所有构建集成的技术都是为了让集成模型比单一模型更加正则化,比如Boosting 技术。
