正则化:ML中的一种策略,可减少测试误差,提高模型泛化能力。
开发更有效的正则化策略:深度学习领域主要研究工作之一。
模型族训练的三个过程:
- 不包括真实的数据生成过程,欠拟合和含有偏差。
- 匹配真实数据生成过程
- 除了2中,还包括许多其他可能的生成过程,方差主导的过拟合
正则化的目标:使得模型从第3种转化为第2种。
1. 参数范数惩罚
1.1
L2
参数正则化
权重衰减。
目标函数:
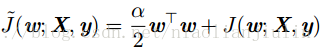
梯度为:
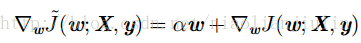
单步梯度下降:
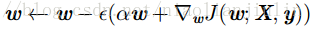
换种写法:
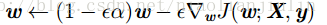
加入权重衰减引起学习规则的修改:每步梯度更新前,会先收缩权重向量。
分析训练的整个过程:
令
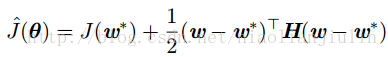
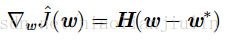
为0。在该式中添加权重衰减的梯度,用
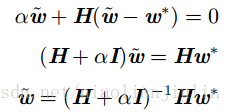
当
因为
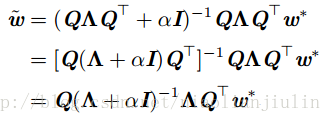
权重衰减的效果是:沿着
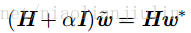
则
当
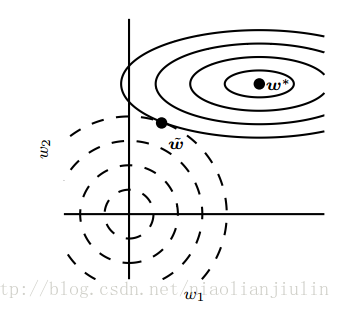
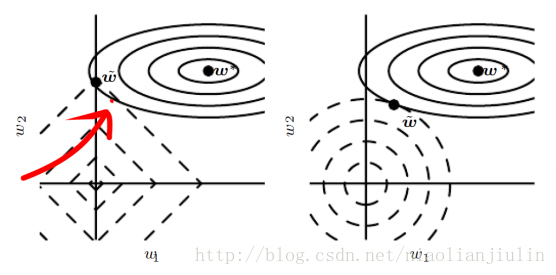
如该图:实线椭圆表示没有正则化目标的等值线。虚线圆圈表示L2正则化的等值线。在
1.2
L1
正则化
书中7.1.2节进行了假设性的讨论。不再赘述。
结论:
2. 数据集增强
提高模型泛化能力的最好办法是使用更多的数据进行训练。因实际数据量有限,一个办法是创建假数据并添加到数据集中。
例如分类问题中的对象识别,沿训练图像每个方向平移几个像素的操作通常可以大大改善泛化。旋转,缩放等也已被证明行之有效。但不能改变类别。比如OCR中的6和9,不能这样干。数据集增强对语音识别也有效的。
在NN的输入层注入噪声,也可被视为数据集增强的一种方式。然而,NN对噪声不是非常健壮(NN容易过拟合)。改善方法之一:简单的将随机噪声添加到输入再进行训练。
3. 噪声鲁棒性
对于某些模型,向输入添加方差极小的噪声,等价于对权重施加范数惩罚(1995年Bishhop就发现提出,看来需要回顾20年前的文章)。一般的,噪声注入远比简单收缩参数要更强大,Dropout算法是该做法的发展方向。
3.1 权重上加噪声
一种正则化模型的噪声方式:将其加到权重上。RNN中用。解释:关于权重的贝叶斯推断的随机实现。贝叶斯学习将权重视为不确定的,可通过概率分布表示这种不确定性。向权重添加噪声是反映这种不确定性的一种实用随机方法。
施加于权重的噪声,还可被解释为与传统正则化形式等同的效果:它鼓励要学习的函数保持稳定。鼓励参数进入权重小扰动对输出相对影响较小的参数空间区域。找到的点不只是极小点,还是由平坦区域包围的最小点。
3.2 输出上加噪声
大多数数据集的标签都有错误。我们可以显式地对标签上的噪声进行建模。例如,对标记取其是正确的概率。
标签平滑:通过把确切分类目标从0和1替换为
使用
4. 半监督学习
半监督学习框架:
DL背景下,半监督学习通常是指:学习一个表示
一般的,新空间上的线性分类器可以达到较好的泛化。例如。可以使用主成分分析(无监督)预处理,然后在投影后的新空间上分类(有监督)。合起来就是半监督。
5. 多任务学习
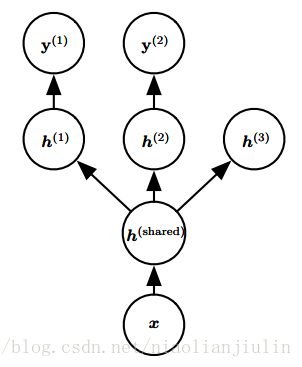
下层:所有任务共享参数
上层:具体任务的参数
共享参数的样本数量相对于单任务增加,改善泛化。前提:不同任务间存在某些统计关系的假设是合理的。
从DL看,底层的先验知识:不同任务中观察到的,解释数据变化的因素中,某些因素是跨两个或更多任务共享的。
6. 提前终止
训练中几乎一定会出现:
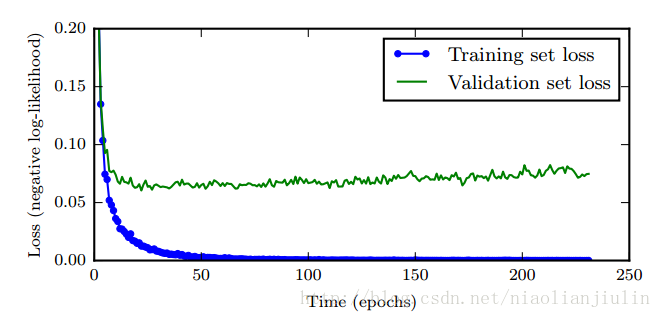
这启发我们:每次验证集误差有所改善后,存储模型参数的副本。训练算法终止时,返回最优参数,而非最新参数。当验证集上的误差在事先指定的循环次数内没有进一步改善时,算法终止。这就是提前终止策略。有效,简单,常用的正则化。
6.1 提前终止为什么具有正则化效果?
从验证集上的U形损失可看出,提前终止是起到了一种正则化策略的效果。
底层的真正机制是什么呢?作者在该节以一种假设讨论了,不赘述。
结论:提前终止可以将优化过程的参数空间,限制在初始参数值的小领域内(1995年)。
两种逼近