详解深度学习中的正则化方法
详解深度学习中的正则化方法
什么是正则化
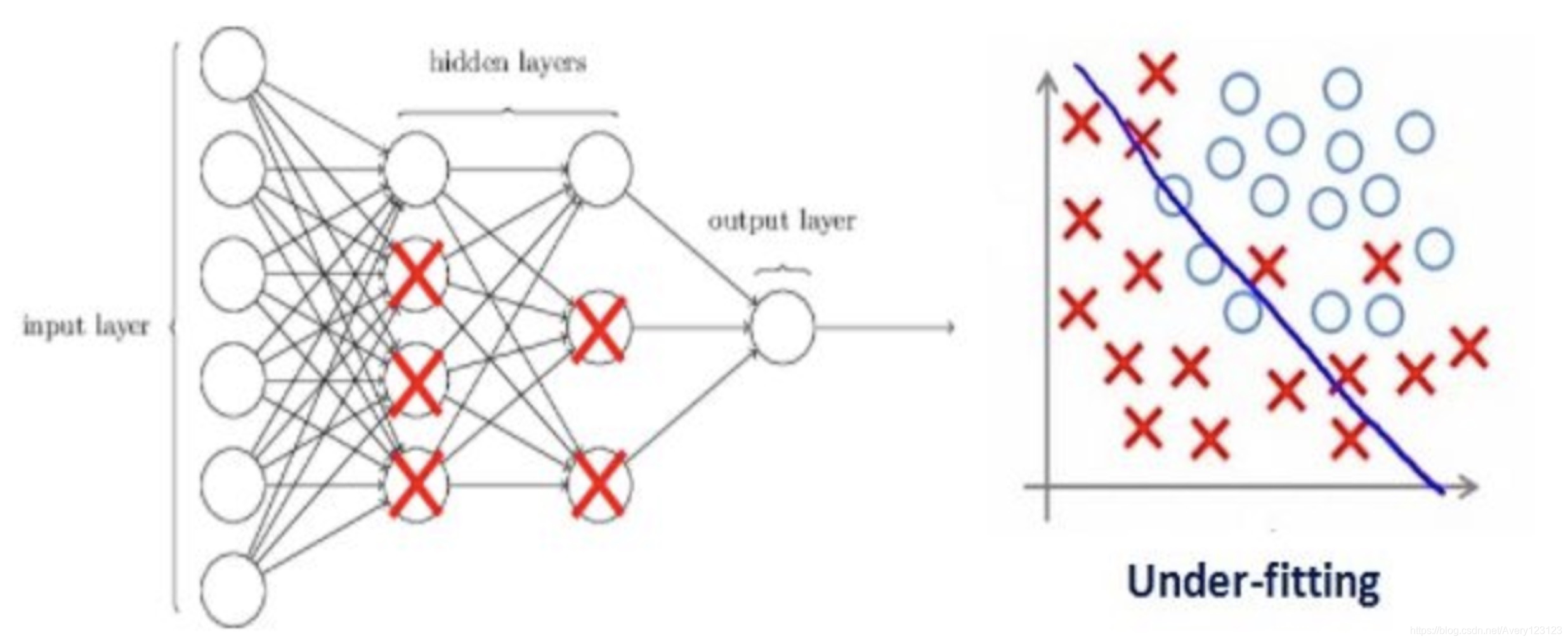
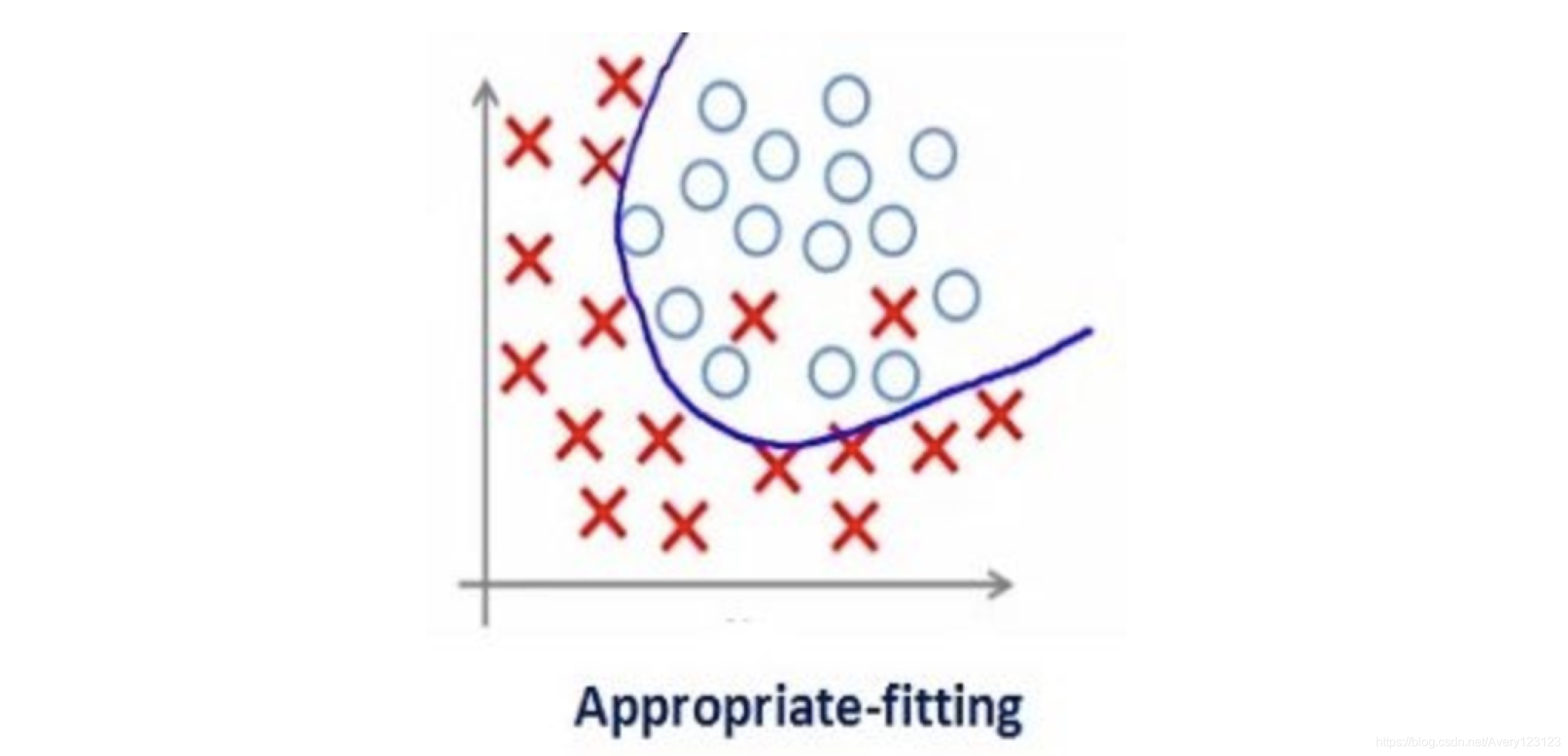
在我们深入了解这个话题之前,先看看下面三幅图像:
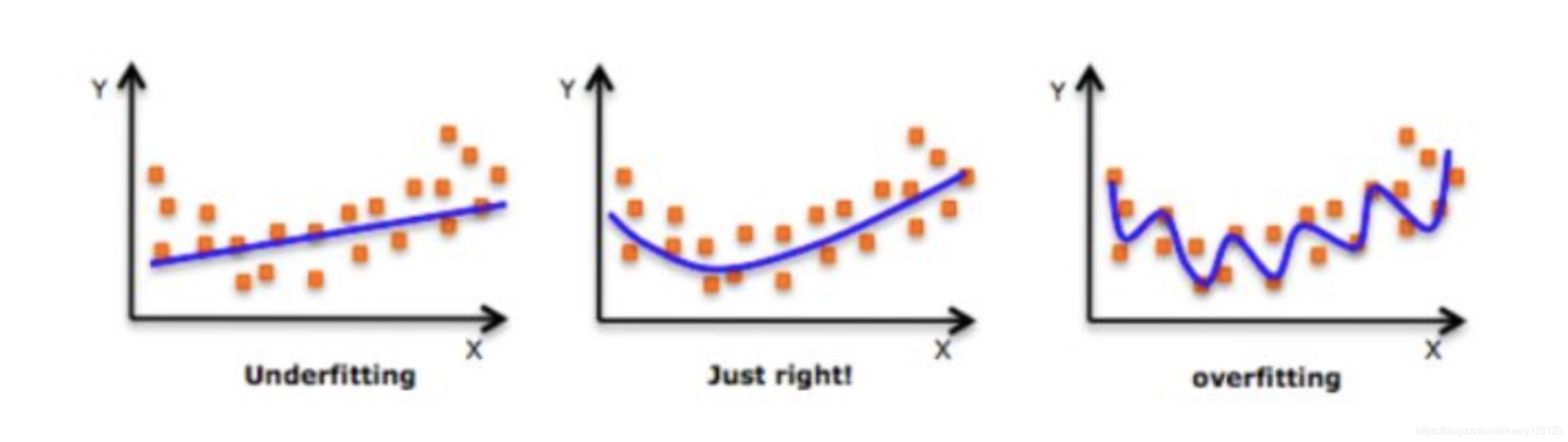
这三张图以此表示的是欠拟合、正好和过拟合。我们可以看到,模型努力地学习训练数据中的细节和噪声数据,但是学得过了头,最终在不可见数据上表现的很糟糕。
简单来说,正则化是一种为了减小测试误差的行为(有时候会增加训练误差)。我们在构造机器学习模型时,最终目的是让模型在面对新数据的时候,可以有很好的表现。当你用比较复杂的模型比如神经网络,去拟合数据时,很容易出现过拟合现象(训练集表现很好,测试集表现较差),这会导致模型的泛化能力下降,这时候,我们就需要使用正则化,降低模型的复杂度。
换句话说,虽然模型的发展方向是正确的,随着模型越来越复杂,训练误差有所下降,但测试误差却没有。如下图所示:

正则化惩罚项
为什么引入正则化惩罚项
在训练数据不够多时,或者过度训练模型(overt raining )时,常常会导致过拟合(over fitting)。正则化方法即为在此时向原始模型引入额外信息,以便防止过拟合和提高模型泛化性能的一类方法的统称,这就引入了正则化惩罚项。在实际中,最好的拟合模型(从最小化泛化误差的意义上来说)是一个适当正则化的模型。
L1正则与L2正则
L1正则

L1范式的意义

L2正则

L2范数的意义

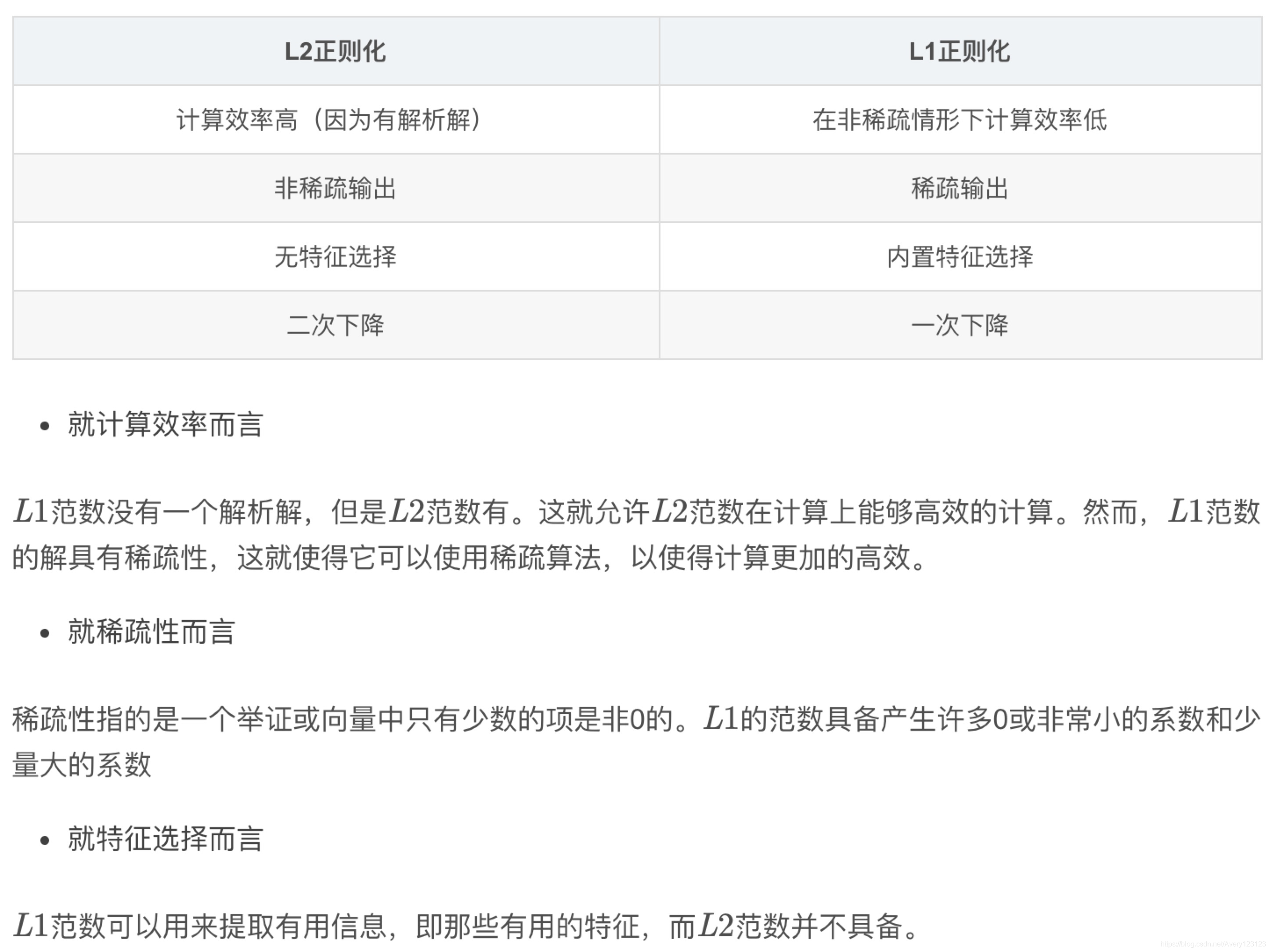
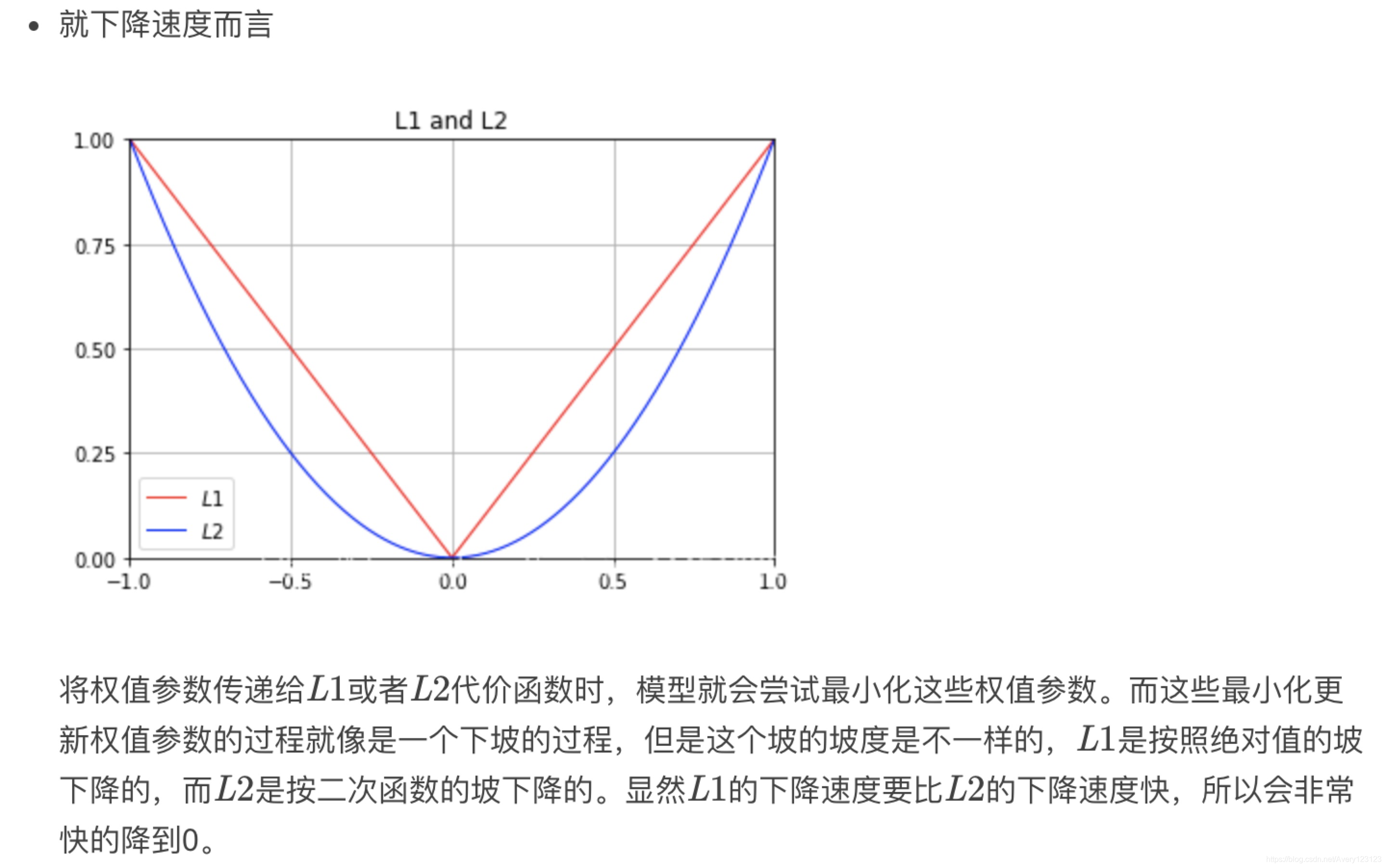
L1正则与L2正则的区别
深度学习的正则化方法
正则化是如何减缓过拟合的?
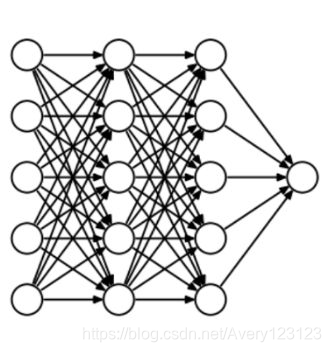
我们假设有个神经网络在训练数据上出现了过拟合,如下所示:
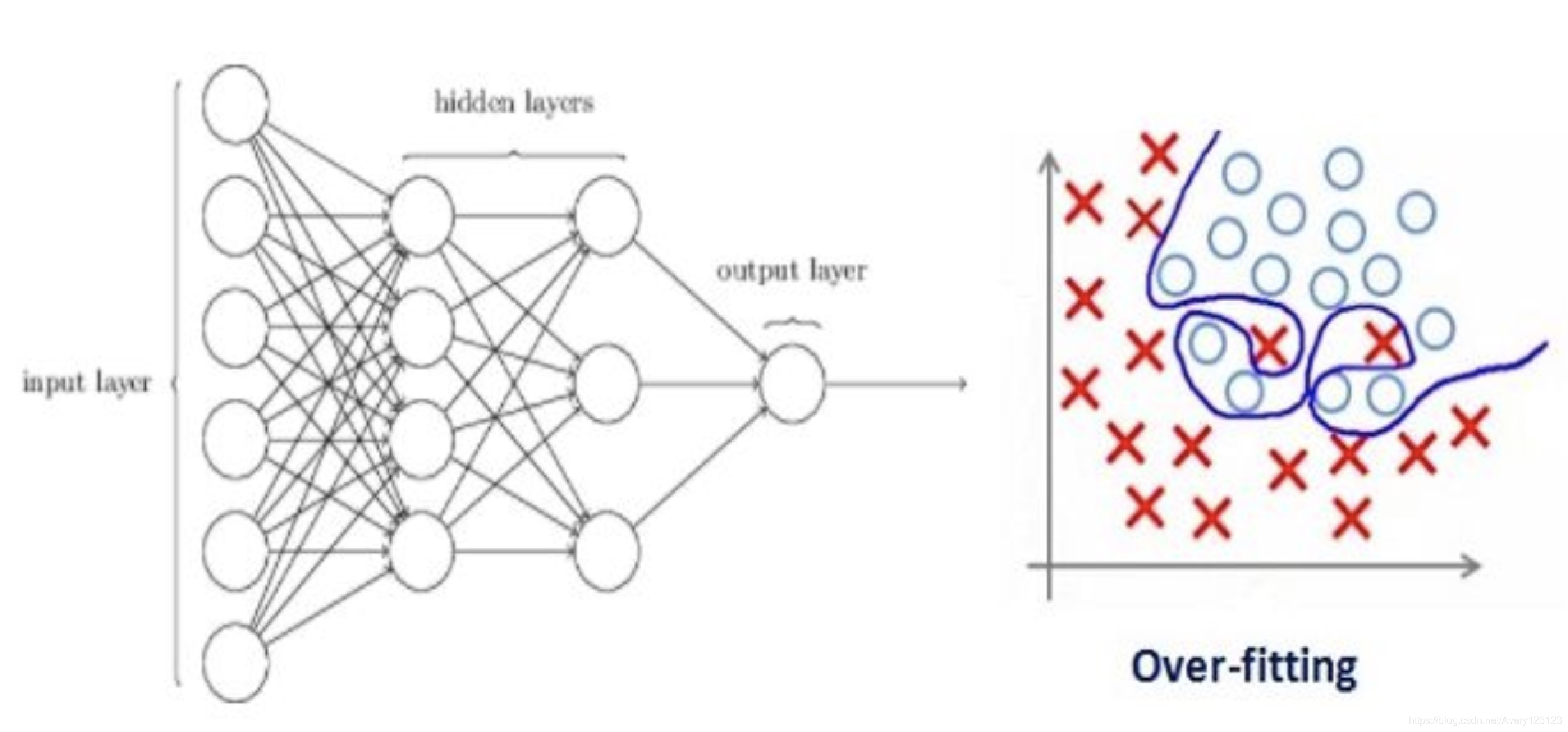
如果你研究过机器学习中的正则化概念,你应该知道正则化会惩罚系数。在深度学习中,正则化会惩罚神经网络节点的权重矩阵。
假设我们的正则化系数非常高,有些权重矩阵几乎等于0。
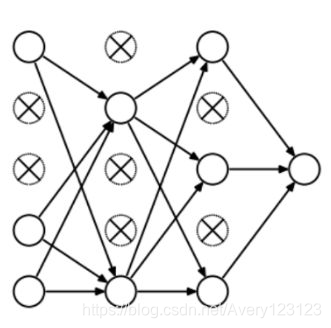
这样会让神经网络变为更加简单的线性网络,训练数据出现轻微的欠拟合。
正则化系数过高并没有用处,我们需要对其优化,从而获得拟合度适当的模型,如下所示:
深度学习中不同类型的正则化技巧
L1 & L2 正则化



Dropout
这是正则化技巧中最为有趣的一种。它的效果很好,也是深度学习领域最常用的正则化方法。
举个例子理解“丢弃法”,比方说我们有个神经网络,结构如下所示:
那么丢弃法是怎么工作的呢?在每次迭代中,它会随机选择一些节点,连同它们的输入连接和输出连接一起移除,如下所示:
每次迭代都会选择一组不同的节点,这样就形成了一组不同的输出。有时也可以把它看作机器学习中的集合学习技术。集合模型通常比单个模型有更好的性能,因为它们能捕捉更多的随机性。
同样地,丢弃法比一般的神经网络有更好的表现。应当丢弃多少节点的概率就是 dropout 函数中的超参数。如上图所示,输入层和隐藏层都能应用丢弃法。
正是由于这些原因,当我们的神经网络结构较大时,有限选择使用丢弃法来获得更多的随机性。
数据增强
减缓过拟合的最简单方法就是增加训练集的数量。在机器学习中,我们有时无法增加训练数据的数量,因为寻找标签数据成本很高。但是假如我们现在需要处理一些图像,可以通过尝试一些做法来扩充数据集——旋转图像、剪切、缩放、变换等等。下图就是对手写字数据集进行的一些转换操作:

这种方法就是我们所说的数据增强,借助它我们通常能大幅提高模型的准确度,同时也是优化模型预测的常用技巧。
提前停止(Early Stopping)
“提前停止”(Early Stopping)是一种交叉验证策略,我们把训练集的一部分用作验证集。当我们看到模型的性能在验证集上开始糟糕时,我们就立马停止训练模型,这就是Early Stopping。
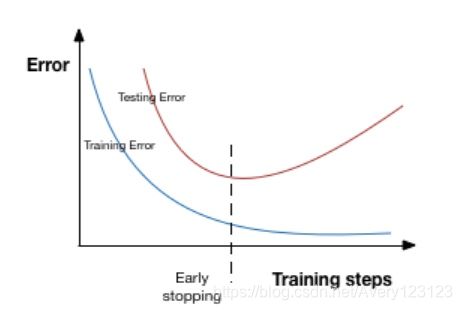
在上图中,我们会在那条虚线位置开始停止训练,因为在这之后模型就会开始对训练数据过拟合。
