在机器学习特别是深度学习中,我们通过大量数据集希望训练得到精确、泛化能力强的模型,对于生活中的对象越简洁、抽象就越容易描述和分别,相反,对象越具体、复杂、明显就越不容易描述区分,描述区分的泛化能力就越不好。
比如,描述一个物体是“方的”,那我们会想到大概这个物体的投影应该是四条边,两两平行且垂直,描述此物体忽略了材质、质量、颜色等等的性状,描述的物体的多,相反,描述的内容越丰富详实则约束越多,识别的泛化性就差,代表的事物就少,比如“一条彩色的白色绣花丝质手帕”。
我们可以利用正则化找到更为简洁的描述方式的量化过程,我们将损失函数改造为:
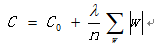
这就是改造后带有正则化项的损失函数。那么为什么加上了正则化项能在一定程度上避免过拟合呢?以前讨论的损失函数只有C0这个部分,在学术上称为“经验风险”,后半部分的损失函数(加入的正则化项的部分)叫做“结构风险”。所谓的“经验风险”就是指由于拟合结果和样本标签之间的残差总和所产生的经验性差距所带来的风险----毕竟差距越大,拟合失效的可能性就越大,这当然是风险,是欠拟合的风险;“结构风险”就是刚才提到的模型不够“简洁”带来的风险。为使模型简洁泛化性能好,我们加入:
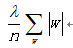
含义就是把整个模型中的所有权重w的绝对值加起来除以样本数量,其中是一个惩罚的权重,可以称为正则化系数或者惩罚系数,表示对惩罚的重视程度。如果很重视结构风险,即不希望结构风险太大,我们就加大,迫使整个损失函数向着权值w减小的方向移动,换句话说,w的值越多、越大,整个因子的值就越大,也就是越不简洁,刚才这种正则化因子叫做L1正则化项,常用的还有一种叫带有L2正则化项的
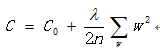
将w做了平方后取加和。L1正则化项的导数为
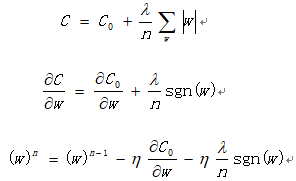
整个导数除了有前面经验风险对w求导贡献的部分,还有后面结构风险对w求导贡献的部分。sgn(w)表示取w的符号,大于0为1,小于0为-1。
带有L2的正则项导数为
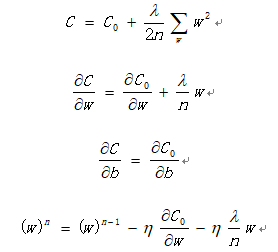
L2正则项中的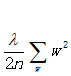
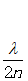
以最简单的线性分类为例,假设样本特征为X=[1,1,1,1],模型1的权重W1=[1,0,0,0],模型二权重W2=[0.25,0.25,0.25,0.25],虽然W1X=W2X=1;但是权重W1只关注一个特征(像素点),其余特征点都无效,模型具体、复杂、明显,能识别“正方形棉布材质的彩色手帕”,在训练集上训练完后容易导致过拟合,因为测试数据只要在这个像素点发生些许变化,分类结果就相差很大,而模型2的权重W2关注所有特征(像素点),模型更加简洁均匀、抽象,能识别“方形”,泛化能力强。通过L2正则化惩罚之后,模型1的损失函数会增加(λ/(2*4))*(12)=λ/8,模型2的损失函数会增加(λ/(2*4))*(4*(1/4)2)=λ/32,显然,模型2的更加趋向让损失函数值更小。
最后从示意图的可视化角度直观理解下正则化的实现过程。
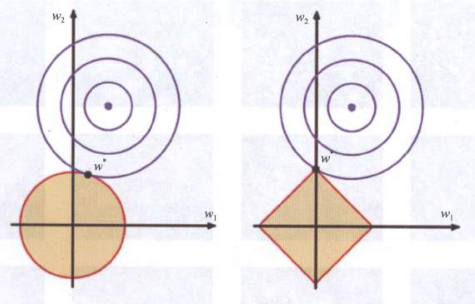
假设在一个模型中只有两个维度w1和w2作为待定系数,最终的理想解在圆心的位置,当然这里画出来的是在第一象限,但是实际上也可能出现在别的位置。由于初始化的时候w1和w2可能会在别的位置,当然也会在二、三、四象限中,在训练的过程中会逐渐从这个初始化的位置向圆心靠拢。
圆心周围的一圈一圈的线其实是损失函数等高线,也就是说当w1和w2所组成的坐标点(w1,w2)在这一圈上的任意位置都会产生相同大小的损失函数,而由于初始化位置不确定,所以可能会出现在一圈的任意位置,那么显然远离坐标系原点(0,0)的(w1,w2)点会产生更大的结构风险,因为其拥有风大的w1和w2值,更为不简洁。
下面花色的圆圈和正方形分别代表由L2和L1所产生的损失值,左侧是L2,右侧是L1的,边缘的圆圈线和直线分别表示它们各自的损失函数值等高线。在加入这一项之后,损失由两部分产生,所以损失函数在收敛的时候要兼顾“小”和“精确”两个特性。经验损失可以认为是“精确”这个特性,会让解朝向圆圈的重心收敛,而结构损失是“小”这个特性,会让解向着原点收敛,最后兼顾两者都在比较小的位置上,图中的图形交点w。就是正则化后权重值w的解。由于多维空间无法画出,大家可以想象一下几百万维空间中w被正则化项拉向圆点的过程。
一般在一次模型搭建过程中,通常先不加入正则化项,先只用带有经验风险项的损失函数来训练模型,当模型训练结束后,再尝试加入正则化项进行改进。惩罚系数λ一般可以设置为1、5、10、15、20……这样的值进行尝试,也可以用1、100、50、25(75)这种二分法的方法尝试,去观察当前的λ是不是有效的提高了准确率Accuracy。
下面再来看下正则化项在神经网络中的重要作用。
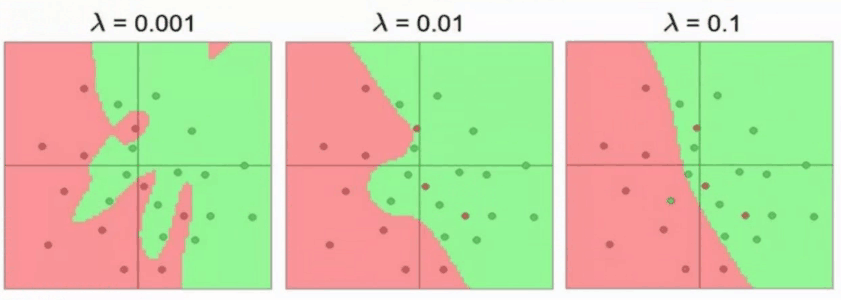
惩罚系数λ=0.001伸出的爪子本质就是过拟合了(由于惩罚的程度不够),λ=0.1泛化能力强。
参考高扬《白话深度学习与Tensorflow》,转载须经同意。