一.索引的基础概念
1.数据库索引是什么?
数据库索引是数据库管理系统(DBMS)中一个排序的数据结构,以协助快速查询和更新数据库中表的结构.
2.索引的类型
普通索引:是最基本的索引,它没有任何限制,
唯一索引:列值唯一(可以有null)
主键索引: 列值唯一(不可以有null)并且 表中只有一个
联合索引:多列组成一个索引
全文索引:对文本的内容进行分词,进行搜索
聚簇索引: 值的逻辑顺序和表数据行的顺序数据相同; 聚簇索引默认是主键,如果表中没有定义主键,InnoDB 会选择一个唯一的非空索引代替。如果没有这样的索引,InnoDB 会隐式定义一个主键来作为聚簇索引。
3.索引方法:
hash优点:
Hash 索引结构(key value)的特殊性,索引可以一次定位,不像B+Tree 索引需要从根节点到枝节点到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 B-Tree 索引。

hash索引缺点:
1)不能使用范围查询。
2) 不能用来做排序运算.
3) 会有hash碰撞的问题
2.b+tree优点:
1)数据都存储在叶节点,磁盘页能容纳更多节点元素,降低树的高度,较少io操作
2)数据都存储在叶节点,固定io操作(从根节点到枝节点再到叶节点)
3)叶节点以双向链表的形式连接,只要遍历叶子节点就可以实现整棵树的遍历,B树只能中序遍历所有节点,排序能力更强
二.InnoDB和MyISAM不同之处
InnoDB的索引和数据存储在一个文件中;MyISAM是存储在两个文件中,索引信息在MYI文件,数据信息在MYD文件
1.MyISAM主索引:
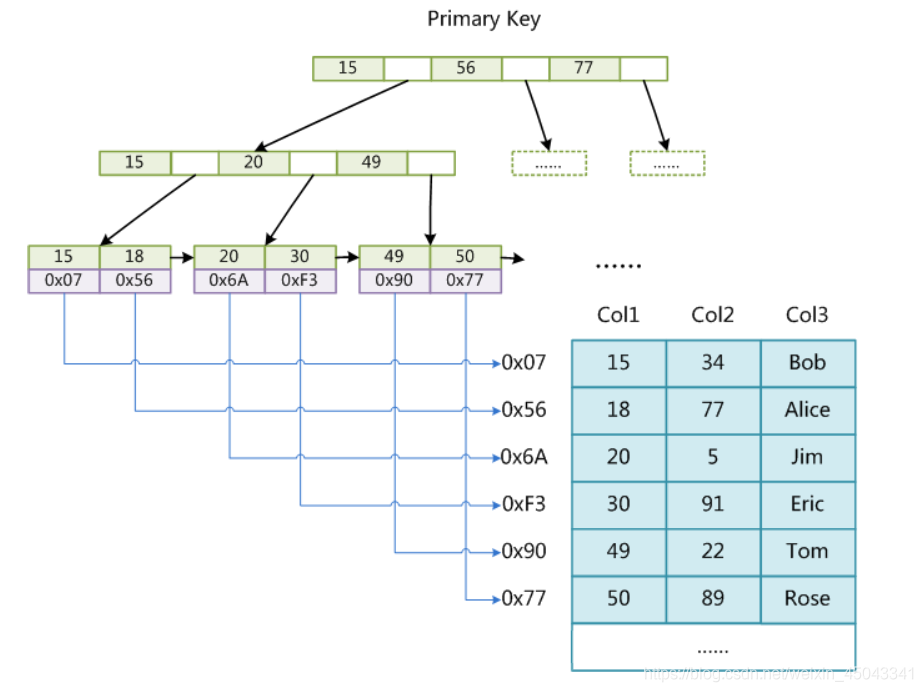
MyISAM辅助索引:

MyISAM的索引会存储数据信息的位置,MyISAM是非聚簇索引
InnoDB主索引:
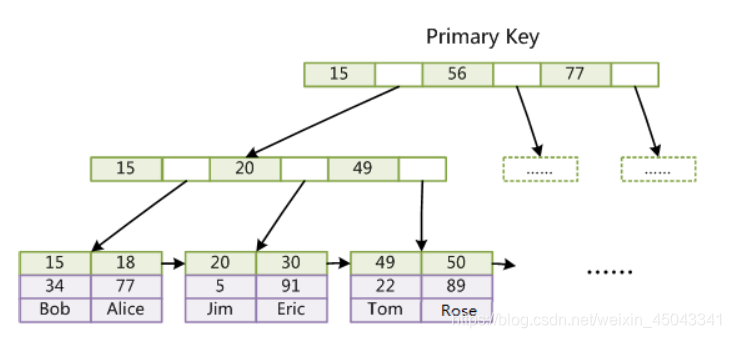
InnoDB辅助索引:
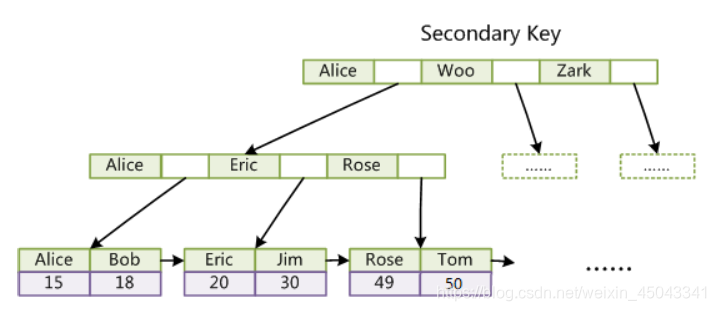
InnoDB主索引的叶节点存储的是page页,是具体的数据,辅助索引的叶节点存储的是主索引的id和索引字段的信息;把name作为普通索引,sql:select name from table where name = “小明”,是不用回表的,select age from table where name = "小明"是要回表,需要去主索引的 那棵树查询具体的信息
注意:主索引存的不是表中的一行数据,而是大小为16k的page,这是因为一个节点大小16k ,存储引擎一次加载的最小单位16384,访问一个节点就是一次io操作,要尽可能多的加载数据,只存一行数据太浪费.
相关问题
1.为什么辅助索引不存主索引的地址而是存id?
如果存的是地址,主索引树分裂或者合并后就找不到该位置了
2.为什么推荐使用自增的id作为主键索引
非自增主键的话,每次插入主键的值是不确定的,新的数据被会插到现有索引页得中间位置,为了将新记录插到合适位置而移动数据,会造成过多的也分裂和页合并的问题
3.select name from table where name = “小明” and new_name like "%liu"有没有用到索引呢?这里name和new_name是联合索引
如果不考虑优化器的话,%liu是用不到索引的,但是有优化器的存在,给我们使用了索引; 这就是索引下推ICP
先找到name索引数得到name="小明"的数据,先不回表,直接找到new_name like "%liu"的值,再进行回表
