Mysql中一旦数据量上到一定的数量级别就会到达性能上的瓶颈,而我们都知道解决的办法就是加索引,但是至于为什么加索引之后查询的性能就能瞬间提升上去了尼?我想很多人都知其然而不知其所以然,其实这都是与索引的数据结构有关。下面我们就逐渐深入了解下Mysql的索引加速查询的原理。
上面说到索引是和其数据结构有关的,那么是什么数据结构尼?我们就当做自己来设计这个数据结构,先从二叉树开始说起。
二叉树
我们都知道二叉树能够将我们的数据进行排序,然后加快查找我们想到的数据,因为一棵二叉树是规律的,左边的子节点必须小于等于其父节点,右边的子节点必须要大于其父节点,那么这个条件看似对于Mysql的索引实现近乎相像,如下图

每个索引列对应的值都会加入到二叉树中,而这个值的位置又是对应着相应的数据行的磁盘地址(类似于key-value对),当我们想要寻找col2=89的数据的时候(select * from t where t..col2 = 89),mysql发现我们所查询的条件列中是加上了索引的,那么就会去索引文件中寻找,也就是从上面的二叉树中去寻找,根据二叉树的规律,我们只需要查询两遍(索引也是在磁盘中,即做了两次的磁盘I/O)就可以定位查询到89,从而得到89对应的磁盘地址。
也许你会觉得这样的索引实现也很完美了,其实这远远不止,因为虽然说mysql的对索引进行排序的页数用到树这种数据结构,但是并不是二叉树,因为二叉树有一个很严重的缺点,就是当添加进来的数据是顺序的时候,它会变成线性表的结构。如下图

这样,当我们想要找col2=8的时候,就相当于把col2的索引值都查询了一遍,也就是全表查询了。所以这样的索引底层设计明显不适用。
红黑树
红黑树是平衡二叉树的一种,上面我们可以看到如果我们用二叉树去作为索引的实现的话,当插入的数据是顺序递增或递减的话,那么这棵树就会变成一个链表,此时我们可以考虑用红黑树去优化解决这个问题

可以看到上图中红黑树会进行自平衡,防止出现类似于普通二叉树的问题。但是红黑树也有一个很明显的缺点,就是高度随着数据量的增多会越来越大,假如这颗红黑树的高度达到了20,而我们所要查询的数据在叶子结点处,那么就会产生20次的磁盘I/O,这样的代价也是很大的。
B-Tree
B-Tree可能能很好地解决红黑树的高度问题,下面列出B-Tree的特点
1、定义任意非叶子结点最多只有M个儿子,且M>2;
2、根结点的儿子数为[2, M];
3、除根结点以外的非叶子结点的儿子数为[M/2, M];
4、每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
5、非叶子结点的关键字个数=指向儿子的指针个数-1;
6、非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
7、非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
8、所有叶子结点位于同一层;
具体看下面的图(取自其他博客)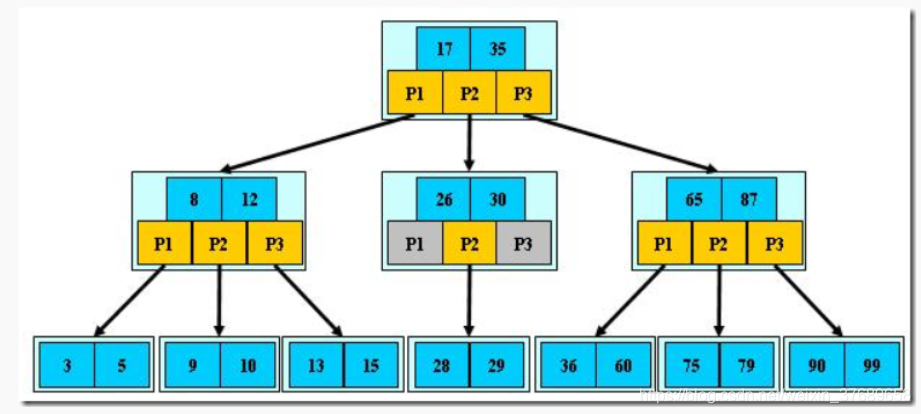
B-Tree通过在一层(一页)中存储多个key值去减少树高度并且通过把磁盘中一页的索引数据加载到内存的方法进而去减少磁盘I/O。当查找来到某个节点(也称为一页数据)的时候,mysql会把这个节点中的所有key从磁盘中load到内存中,然后在内存中去通过二分查询找到该key,若没有找到就到符合该key的范围的子节点中去寻找,继续从磁盘中load子节点的数据到内存中,重复上一步直到把key找到为止。
假若上面需要找到28,从根节点开始,17<28<35,,所以拿到指针P2,根据指针P2去找到磁盘找到对应的另一页key加载到内存中去查找28,找不到的话由于26<28<30,拿到这一页的指针P2,根据指针P2去磁盘找到另一页的key加载到内存,找到28。
但是B-Tree也有缺点,就是每个节点存储key+具体数据,而度(一页数据)涉及到IO读取,故如果度设计的很大就会影响IO读取效率。所以mysql内部控制了每一页的大小,我们可以通过SHOW GLOBAL STATUS LIKE 'Innodb_page_size'去进行查看

我们可以看到mysql给我们设置的每一页的大小是16384b=16kb,也就是说每次从磁盘中load索引值最大只能load
16kb,由于该限制加上B-Tree的每一页都存储key+data,如果data较大,那么每一页存储的key就会变少,最后也会使得深度无法控制。所以mysql就对B-Tree进行了改良。
B+Tree
mysql索引底层就是使用的B+Tree去维护的。B+Tree与B-Tree最大的不同在于,B+Tree的data全都放在叶子结点,非叶子节点不负责存放data,也就是说叶子结点上面存放着我们整张表的数据或者对应的磁盘地址(MyISAM存储索引值对应行的磁盘地址,InnoDB直接存储表数据,下面详细讲到),我们可以遍历叶子结点就能找到所有的数据。我们上面说到由于度(一页)的大小限制,所以度中存储data会造成key存储数量的减少,而B+Tree将data全部放在叶子结点上就是来解决这个问题的,这样可以增加度上存放key的数量减少树的高度。

MyISAM与InnoDB引擎中索引存储结构的区别
我们上面已经分析了Mysql中采用B+Tree如何去处理索引,那么对于不同的存储引擎,Mysql的索引存储结构也是有所差别的,我们具体来讲讲索引在MyISAM与InnoDB中这两种常用的存储引擎下的存储结构是怎样的。
首先来说说MyISAM,我们来看下一张MyISAM存储引擎的表在磁盘中是怎样的形式存储的。

对于一张MyISAM存储引擎的表来说,它的构成主要由三种文件格式组成,分别是frm,MYD,MYI。frm是存放表的结构信息的,MYD是存放表数据的,MYI是存放表索引的。
那么,对于MyISAM的表来说,我们查询数据的过程类似于下图:

假如我们select * from t t.Col1 = 15,当我们执行这条语句的时候,Mysql会发现Col是加了索引的,那么就会去对应表的MYI文件去找到维护该索引值的B+Tree,然后通过我们上面说的方式在B+Tree里面去查找出对应的key值,拿到对应的value值再去表对应的MYD文件中去查处某一行的数据。所以说MyISAM索引文件和数据文件是分离的,也正是由于这样,所以MyISAM存储引擎的表所创建的索引都是非聚集索引。
再来看InnoDB,由InnoDB存储引擎创建的表主要由两种文件类型来组成,分别是frm,ibd,frm存储表的结构信息,ibd存储的是索引+表数据。明显与MyISAM最大不同的就是索引和表数据放在了同一个文件中了,如下图所示(由主索引组织成数据):

可以发现InnoDB的表通过索引找到的就是该索引值所在行的其他字段的所有值。一般情况下InnoDB下的表的主键会默认创建聚集索引(也称为主索引),而且一张表只能允许一个聚集索引的存在,因为一旦数据存储了,顺序只能有一种。(对于InnoDB来说,下面说到的主索引,主键,聚集索引都是用一种说法)InnoDB的表的数据是由主索引去组织起来的,创建主键也就默认创建了主索引,但是InnoDB也不是强制一定要有主键,那么这里就有个疑问,不是说数据是由主索引去组织起来的吗?如果没有主键那么数据怎么组织?其实如果我们没有在InnoDB的表下面创建主键,mysql会选择第一个不包含有NULL值的唯一索引作为主键索引,如果也没有这个唯一索引,那么mysql会选择内置6字节长的ROWID作为隐含的聚集索引,这样,有了聚集索引,就能组织起表的数据了。
上面也说了一张表只能有一个聚集索引而且数据存储顺序只能有一种,那么这里又有一个疑问,上面的B+Tree是根据聚集索引组织的,那么设置其他二级索引(次索引和二级索引是同一种说法)的话怎么去组织起该索引的B+Tree去快速找到数据尼?首先,InnoDB和MyISAM都有主索引和次索引之分,就InnoDB来说,它的主索引的B+Tree如上图所示地去组织数据,而次索引的话就有所不同了,它的叶子结点存放的并不是数据了,而是存放的key字段+主键值,也就是说根据次索引走的话最终走到B+Tree的叶子结点拿到主键的值然后再去主索引的B+Tree去找到对应的数据,如下图:

小结:MyISAM无论主索引还是二级索引的B+Tree的叶子结点都是指向该数据在磁盘的指针,所以可以看出MyISAM中的主索引与二级索引并无不同,主索引只是去保证该字段唯一非空的,MyISAM中可以不设置主键,这与设置了主键后的B+Tree并无不同;InnoDB通过主索引的B+Tree能直接找到数据,因为数据是挂在主索引的B+Tree的叶子结点下面的,而二级索引的B+Tree的叶子结点是存储着索引字段+key值,拿到key值再去走主索引的B+Tree最终拿到对应的数据。
面试题:为什么InnoDB表必须要有主键,并且推荐使用整型的自增主键?
这个问题有三个小问:
1.为什么必须要有主键?
这个问题答案如上。
2.推荐使用整型的主键?
B+Tree寻找数据的规则上面也已经说了,不断地通过判断缩短寻找的数据的范围直到找到数据为止,因为B+Tree每一页都是有序的,每到一页就要进行值大小的判断进而找到下一页,而如果这个主键是整型的话,直接数字之间的大小比较会比字符串之间的大小比较快的,这样就能缩短每一页的大小判断的时间。
3.自增的主键?
B+Tree的每个叶子结点之间都有一个双向指针指向对方,而且叶子结点的每个值从左到右都是递增的,那么如果主键是自增的话,每个值就会自动地添加到最右边的节点或者新创建一个节点,而如果主键不是自增的,就会出现值会添加到中间的叶子结点中,这回产生其他值的位移,这样的效率对比直接添加显然要低得多。