
目录
1、认识索引
相信大家都上过语文课,语文老师上课说,各位同学,把书翻到木兰诗这一页,像篮球哥这种一学期读完了书还锃亮的人来说,自然不知道木兰诗在那一页,于是就会去翻一下书前面的目录,通过目录来确定木兰诗在哪一页。
索引本质上相当于书的目录,通过目录就可以快速找到某个章节对应的位置,索引的效果就是为了加快了查找的速度!
概念:索引是一种特殊的文件,包含着对数据表里所有记录的引用指针,可以对表中的一列或多列创建索引,并指定索引的类型,各类索引有各自的数据结构实现,具体后面讲解。
上面说到,索引是为了加快查找的速度,那么我们对数据库的操作无非就是增删改查,虽然索引的存在增加了我们查找速度,但反过来一想,是不是也提高了 增 删 改 的开销?
作为一本已经出版的书,如果要增加一个章节,显然要修改目录,要删掉一个章节,仍然要修改目录,如果要修改某一章节文章标题,仍然要修改目录!

放在 MySQL 中,存在索引确实加快了查的速度,但是反之如果进行增删改,就需要调整已经创建好了的索引了,也就提高了增删改的开销。
而且索引还提高了空间上的开销,上面说到索引本质是特殊文件,存着数据的引用指针,此时构造了索引,也就需要额外的硬盘空间来保存了!
既然上述索引的缺点不少,为什么还要用索引呢?这就好比一本书出版了,要过多久会进行一次改版呢?估计蛮久吧,而实际多数场景中,查找的概率是比 增 删 改 要多得多的!因此多数情况下,引入索引还是很划算的。
2、索引的使用
当创建主键约束,唯一约束,外键约束时,会自动创建对应列的索引。
● 查看索引
show index from student;
这里截图不全,但只需关注结果的 Key_name 和 Column_name 就可以了, 这条 sql 就是显示出 student 表中的带有索引的全部字段,通过上述结果可以发现,只有一个字段带有索引,id 字段(主键约束自带的索引)。
● 创建索引
create index idx_stu_name on student(name);这样就表示对 student 表中 name 字段创建了索引,查看 student 表中索引结果:

注意:创建索引,最好是在表创建之初就把索引给搞好,如果是针对一个已经有大量数据的表来创建索引,是一个危险操作!这个时候就会吃掉大量的磁盘 IO,耗时多久取决于数据量,此时这段时间里数据库是无法被正常使用的。
能随便指定字段创建索引吗?
这个是不能的,索引本质上是为了提高查找的效率,也不是所有的情况加上索引就一定快,特别是像对性别增加索引,就两个选择,男或女,这样是无法提高查找效率的! (后面讲解索引原理会理解更清楚)
● 删除索引
drop index idx_stu_name on student;删除操作和上述创建类似,对于数据量大的表进行删除索引,也是危险操作!
3、索引底层的数据结构(重点)
上面谈到索引本质就是为了加快查找的速度,那到底是用什么样的数据结构来组织索引数据的呢?
这就是面试中很常见的一个问题,当然也不能直接告诉面试官是采用的什么数据结构,而是要头头是道,层层分析,只有这样,你才有可能得到面试官的青睐。
既然是讨论索引背后的数据结构,那么回顾我们前面学过数据结构的知识,查找效率最高的是谁?
首当其冲的是哈希表,这也是数据结构中最重要的!也是工作中使用频率最高,面试出场频率也很高,回顾一下,HashMap 查找元素的时间复杂度是多少?采用的数据加链表的结构,链表的长度是一个常数,所以认为哈希表的查找元素时间复杂度是 O(1)。
既然哈希表那么快,所以索引底层使用的是哈希表吗?很遗憾并不是!
哈希表有一个致命的缺陷,他不是不关于 key 有序,也就是你无法进行范围查询,而数据库中是经常要范围查询的!比如查询学号在 10010 ~ 10200 之间的同学,哈希表是做不到的!
既然需要范围查询,那前面还介绍过一种数据结构,二叉搜索树,中序遍历这棵二叉搜索树就是有序的,它查询的时间复杂度是多少呢?O(n),因为最坏的情况可能二叉搜索树会退化成链表这样的结构,对应文章也讲述过。
二叉搜索树好像可以范围查询了,但是不够快,如果采用AVL,红黑树查询是可以达到 logN 的,但是上述 AVL,红黑树,都是二叉!二叉就意味着一个节点最多有两棵子树,当元素个数很多的时候,树的高度就会较高,树的高度就决定了查询时候元素比较的次数,对于数据库数据是存硬盘上的,数据库比较都是要读硬盘,加上数据量的庞大树的高度就越高,很遗憾,显然不适合!
既然二叉不行,那么就多搞几个叉嘛,这怎么能难到程序猿嘛!
这里就要来介绍 N叉搜索树了,每个节点上有多个值,同时有多个分支,书的高度就降低了,对于 N叉树有一种典型的实现,叫做 B 树!

虽然比较的次数没有减少,但是由于一个节点有多个数据(每个节点都是在硬盘上),这样一来,读写硬盘的次数是减少了的!此时 B 树已经比二叉搜索树更适合作于数据库的索引了。
但是有一个问题,如果要查找的数据是32,那么则会非常快,如果要查的数据是3呢?其实就比查 32 要慢一点,这样一来,可能查询的数据不同,比较的次数也会不同,效率也不一样,而编程中更讲究效率平衡,虽然B树已经可以比二叉树更适合做数据库的索引了,但是还不够,于是又引入 B+ 树,是对 B 树进一步的改进。
B+树的结构:

对于上述的B树来看,B+树也是一个N叉搜索树,每个节点可能包含N个key,N个Key 划分出N个区间,B+树的父元素的key,会在子元素中重复出现,而且还是以最大值的姿态出现的!
这样的重复出现,导致了叶子节点,就包含了所有的数据全集!也就是非叶子节点中的所有值都会在叶子节点中体现出来,这样有什么好处呢?别急,往下看:
而且B+树还做了优化,会把叶子节点,用类似于链表的方式进行首尾巴相连,如果我们要查找 id > 17 and n < 40 这样的数据,只需要遍历到指定的位置,往后遍历对应的叶子节点即可!
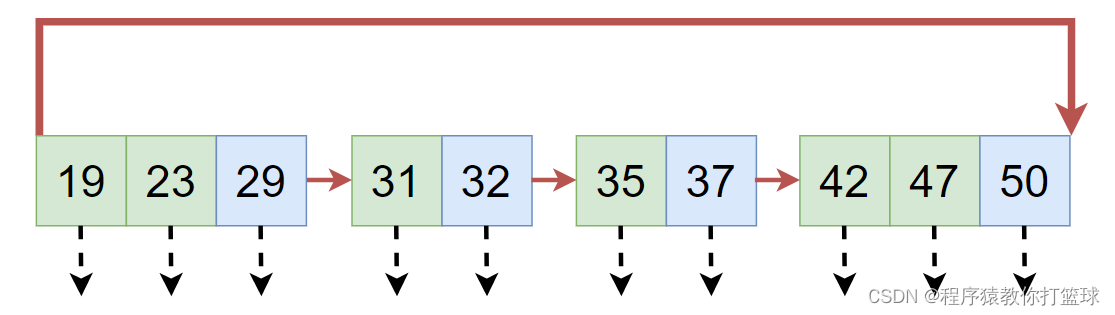
上述说到的非叶子节点的值都会在叶子节点中体现出来,那是不是就意味着占用的存储空间就大大增加了?
其实真正存储了硬盘数据的只有叶子节点!看上面画的图,虚线部分,叶子节点中才是硬盘上的数据(完整的一条数据),而非叶子节点可以理解为只是存了个id (主键),这样一来就意味着非叶子节点占用的空间是大大的降低了,是可能在内存中可以放进去缓存,更进一步的降低了硬盘IO。
所以B树查找不同的值效率可能不同,而B+树由于只有叶子节点存储了完整数据,所以都要走到叶子节点来,相当于查任何数据效率都比较均衡!
如果有的表除了有主键索引,还有别的非主键列也设置了索引,那么这个情况下,就会构造另一个 B+ 树,这个B+树非叶子节点里存的都是这一列里面的key(比如学生姓名),到了叶子节点这一层,不是存之前完整的一条数据了,而是存 id(主键)。
那么就能得出,如果走主键列索引查询,只需要查一次 B+ 树就可以,如果是使用非主键列索引来查询,则需要先查一遍 非主键索引列 的 B+ 树,通过得到的主键,拿着主键在查一遍主键列的 B+ 树,这种操作我们称为回表!
总结:
基于上述分析,B+ 树是作为索引的最好选择,当然也有一些应付特殊场景的数据库也会采用不同的数据结构, 相较于 B 树,B+树做了更多的优化,比如:非叶子节点只存储了索引列的key,并未存储完整数据,以至于有可能将非叶子节点放入内存中缓存,减少读取硬盘IO次数,只有叶子节点存储了完整数据,意味着查找任意数据时间更均衡了,另外会把叶子节点连接起来,这样进行区间查询的效率就更快了,相当于查找指定区间的链表。
注意:上述我们讲解的B+树这个结构,只是针对 MySQL 的 InnoDB 这个数据库引擎,里面典型使用的数据结构,不同的数据库,不同的引擎,里面存储数据的结构可能存在差异!
下期预告:【MySQL】事务