一: MySQL为什么要选B+数作为底层的数据结构
- MySQL的底层算法有B数、红黑树、hash、B+树,为什么就选择了B+树作为数据库的底层物理结构
- 二叉树的特点是左节点小于根节点、根节点小于右节点
- B树由于存在特殊情况,如左节点为空,节点全在右节点上,这样导致的结果会造成和没有索引一样,依次查找,效率很低,同时也会造成树的深度很深,IO次数太多导致查询效率很低。
- 红黑树由于存在树的深度问题导致查数据IO消耗很大,索引降低了性能。
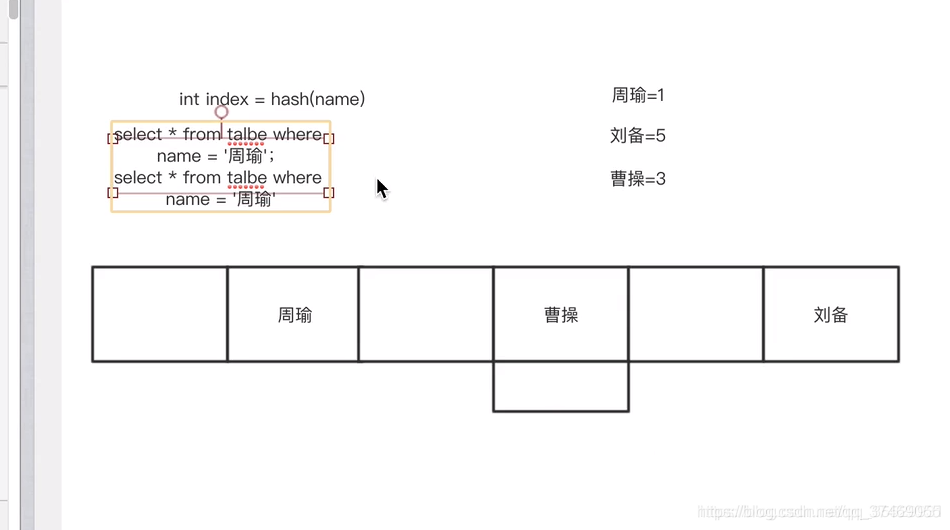
- Hash索引把数据以hash形式组织起来,因此查找某一条记录的时候,速度非常快。同时.hash算法的索引有个缺点,因为它不是按照大小排序的。所以,它无法按照范围进行查找。
- B+树结构就对这些情况进行了优化
B树的深度设定为三层,每一层的大小为16K,而每个索引和索引指针对应的大小为8kb和6kb,这样索引和索引指针加起来的大小就为14kb,一层就可以存161024/14 = 1170,第一层和第二层全部存的是索引和索引指针,第三层存的就是指针和数据,每个指针和数据所占的大小为1k,这样第二次的一个索引对应的第三层索引最多就为16个,这样索引的数量最多就为11701170*16 = 21902400,也就是两千一百多万,这也是为什么数据库的性能瓶颈为两千多万。
优势:
1:避免了树的深度,这样就可以减少IO的消耗,可以很快的找到对应的数据
2:叶子节点的左右索引存在指针,这样对于范围查询的效率有了很大的提升
二:聚簇索引和非聚簇索引的区别
InnoDB主索引就是聚簇索引,而MyISAM主索引就是非聚簇索引
-
MyISAM数据库引擎:
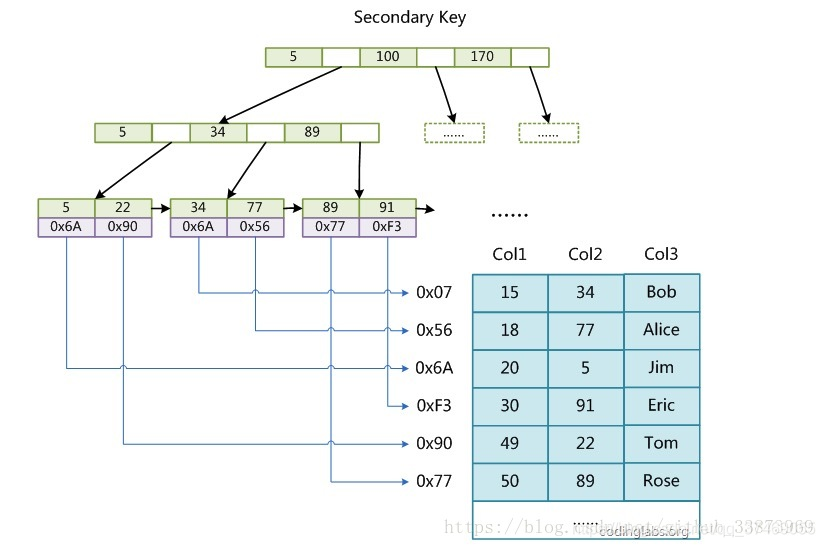
MyISAM数据库引擎的数据和索引是分开存放。
地址指向我们的数据条。这就实现了我们的索引与数据分开的非聚集索引。
这里有个特点,每个叶子结点都可以通过指针相连,这就支持我们进行顺序打印了。 -
InnoDB数据库引擎
InnoDB数据库引擎的索引和数据是存放在一起的。
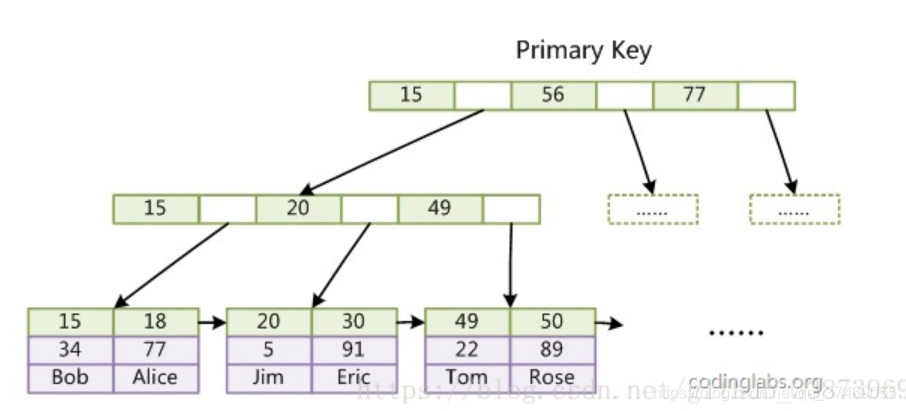
-
不同数据库存储引擎存储格式
MyISAM存储格式:

.frm文件存的是表的数据结构
.MYI文件存的是索引
.MYD文件存的是数据
InnoDB存储格式:

.frm文件存的是表的数据结构
.ibd文件存的是表的索引和数据
三:主键索引和普通索引的区别
在 MySQL 中, 索引是在存储引擎层实现的, 所以并没有统⼀的索引标准, 由于 InnoDB 存储引擎在 MySQL数据库中使⽤最为⼴泛, 下⾯以 InnoDB 为例来分析⼀下其中的索引模型.在 InnoDB 中, 表都是根据主键顺序以索引的形式存放的, InnoDB 使⽤了 B+ 树索引模型,所以数据都是存储在 B+ 树中的, 如图所示:
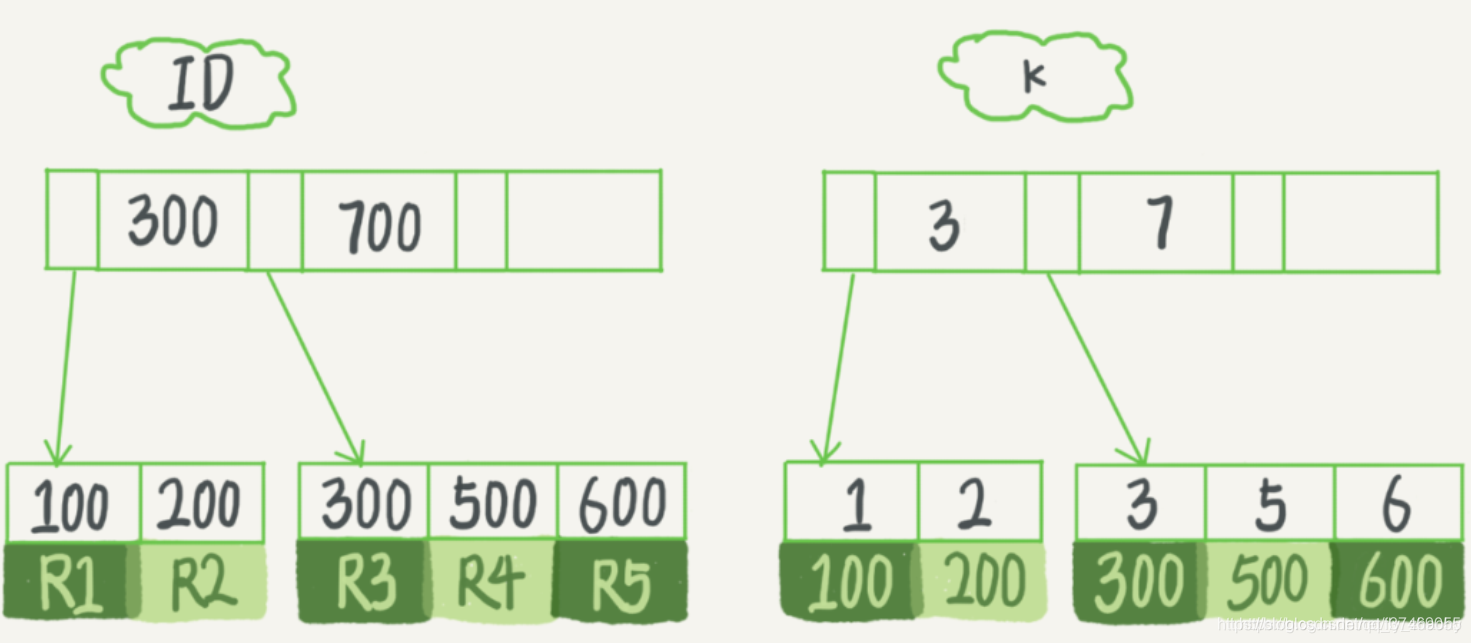
从图中可以看出, 根据叶子节点内容不同,索引类型分为主键索引和非主键索引.
主键索引也被称为聚簇索引,叶子节点存放的是整行数据; 而非主键索引被称为二级索引,叶子节点存放的是主键的值.
如果根据主键查询, 只需要搜索ID这颗B+树
而如果通过非主键索引查询, 需要先搜索k索引树, 找到对应的主键, 然后再到ID索引树搜索一次, 这个过程叫做回表.
总结, 非主键索引的查询需要多扫描一颗索引树, 效率相对更低.
四:联合索引的底层是如何实现的
- 表结构
CREATE TABLE `city` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '城市编号',
`province_id` int(10) unsigned NOT NULL COMMENT '省份编号',
`city_name` varchar(25) DEFAULT NULL COMMENT '城市名称',
`description` varchar(25) DEFAULT NULL COMMENT '描述',
PRIMARY KEY (`id`),
KEY `index_pro_ci_de` (`province_id`,`city_name`,`description`) USING BTREE COMMENT '联合索引'
) ENGINE=InnoDB AUTO_INCREMENT=1850386 DEFAULT CHARSET=utf8;
联合索引是存在索引顺序的
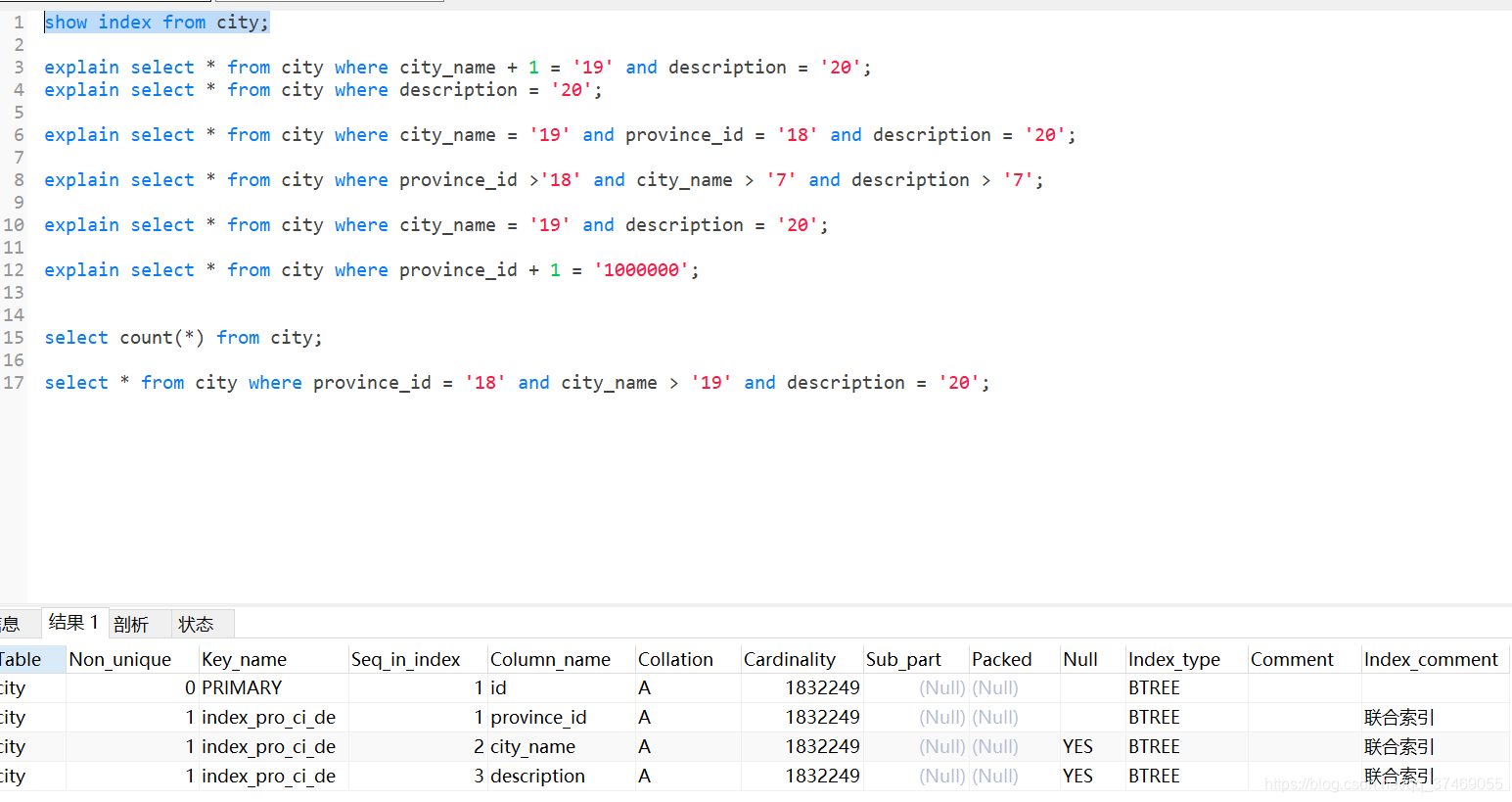
联合索引的顺序绝对了索引的优先级,如姓和名,都是先根据姓去找到对应的姓,然后根据名去找到对应的人,这样联合索引才有效,如果只有名而没有性,这样就无法利用索引从而导致联合索引失效,这也是为什么联合索引构建的时候一定要注意顺序性。
五:MySQL的主键为什么建议为整型而且要自增
- MySQL的主键为什么建议为整型
主键作为整型的好处有:
1:整型所占用的内存少,所以可以存放的索引数量更多。
2:整型比较起大小来比UUID的效率更快。
主键整型自增的好处:
如果用UUID作为主键,那么就存在B+树的分裂重整。
用整型自增就不存在这个问题,直接每次在B+树的末尾添加即可。