本文转自公众号《数据科学家联盟》,作者:饼干
一、偏差方差
1、偏差和方差的定义如下:
-
偏差(bias):偏差衡量了模型的预测值与实际值之间的偏离关系。例如某模型的准确度为96%,则说明是低偏差;反之,如果准确度只有70%,则说明是高偏差。
-
方差(variance):方差描述的是训练数据在不同迭代阶段的训练模型中,预测值的变化波动情况(或称之为离散情况)。从数学角度看,可以理解为每个预测值与预测均值差的平方和的再求平均数。通常在模型训练中,初始阶段模型复杂度不高,为低方差;随着训练量加大,模型逐步拟合训练数据,复杂度开始变高,此时方差会逐渐变高。
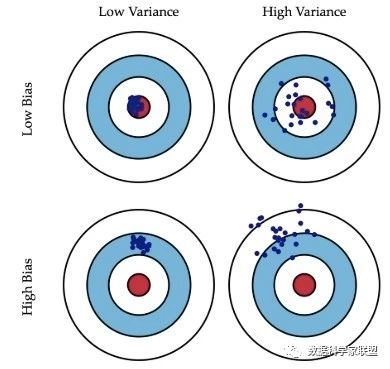
- 如左下角的“打靶图”,假设我们的目标是中心的红点,所有的预测值都偏离了目标位置,这就是偏差;
- 在右上角的“打靶图”中,预测值围绕着红色中心周围,没有大的偏差,但是整体太分散了,不集中,这就是方差。
以上四种情况:
- 低偏差,低方差:这是训练的理想模型,此时蓝色点集基本落在靶心范围内,且数据离散程度小,基本在靶心范围内;
- 低偏差,高方差:这是深度学习面临的最大问题,过拟合了。也就是模型太贴合训练数据了,导致其泛化(或通用)能力差,若遇到测试集,则准确度下降的厉害;
- 高偏差,低方差:这往往是训练的初始阶段;
- 高偏差,高方差:这是训练最糟糕的情况,准确度差,数据的离散程度也差。
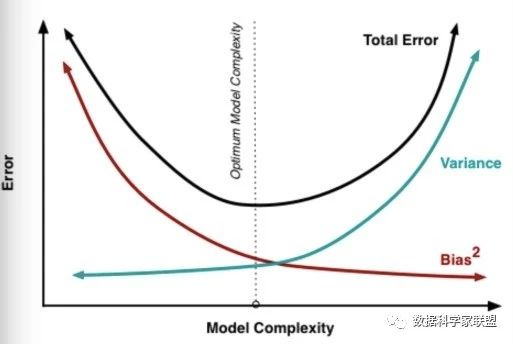
2、模型误差 = 偏差 + 方差 + 不可避免的误差(噪音)。一般来说,随着模型复杂度的增加,方差会逐渐增大,偏差会逐渐减小,见下图:
3、原因:
一个模型有偏差,主要的原因可能是对问题本身的假设是不正确的,或者欠拟合。如:针对非线性的问题使用线性回归;或者采用的特征和问题完全没有关系,如用学生姓名预测考试成绩,就会导致高偏差。
方差表现为数据的一点点扰动就会较大地影响模型。即模型没有完全学习到问题的本质,而学习到很多噪音。通常原因可能是使用的模型太复杂,如:使用高阶多项式回归,也就是过拟合。
有一些算法天生就是高方差的算法,如kNN算法。非参数学习算法通常都是高方差,因为不对数据进行任何假设。
有一些算法天生就是高偏差算法,如线性回归。参数学习算法通常都是高偏差算法,因为对数据有迹象。
4、权衡:
偏差和方差通常是矛盾的。降低偏差,会提高方差;降低方差,会提高偏差。
这就需要在偏差和方差之间保持一个平衡。
以多项式回归模型为例,我们可以选择不同的多项式的次数,来观察多项式次数对模型偏差&方差的影响:
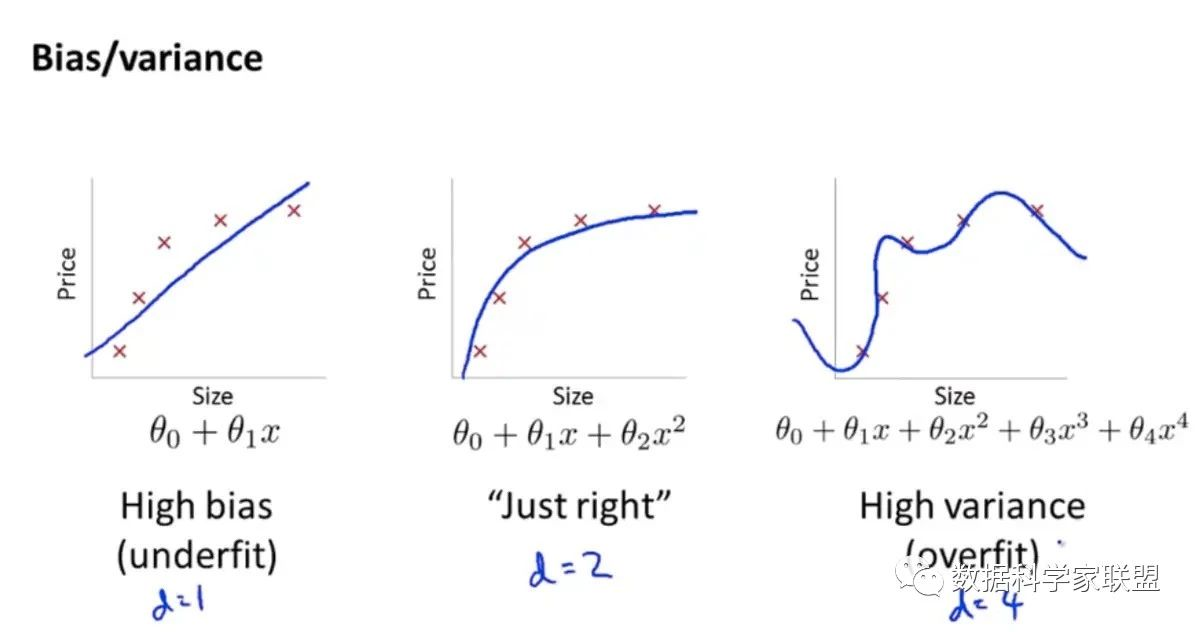
我们要知道偏差和方差是无法完全避免的,只能尽量减少其影响。
- 在避免偏差时,需尽量选择正确的模型,一个非线性问题而我们一直用线性模型去解决,那无论如何,高偏差是无法避免的。
- 有了正确的模型,我们还要慎重选择数据集的大小,通常数据集越大越好,但大到数据集已经对整体所有数据有了一定的代表性后,再多的数据已经不能提升模型了,反而会带来计算量的增加。而训练数据太小一定是不好的,这会带来过拟合,模型复杂度太高,方差很大,不同数据集训练出来的模型变化非常大。
- 最后,要选择合适的模型复杂度,复杂度高的模型通常对训练数据有很好的拟合能力。
其实在机器学习领域,主要的挑战来自方差。处理高方差的手段有:
- 降低模型复杂度
- 减少数据维度;降噪
- 增加样本数
- 使用验证集
待补充。。。。