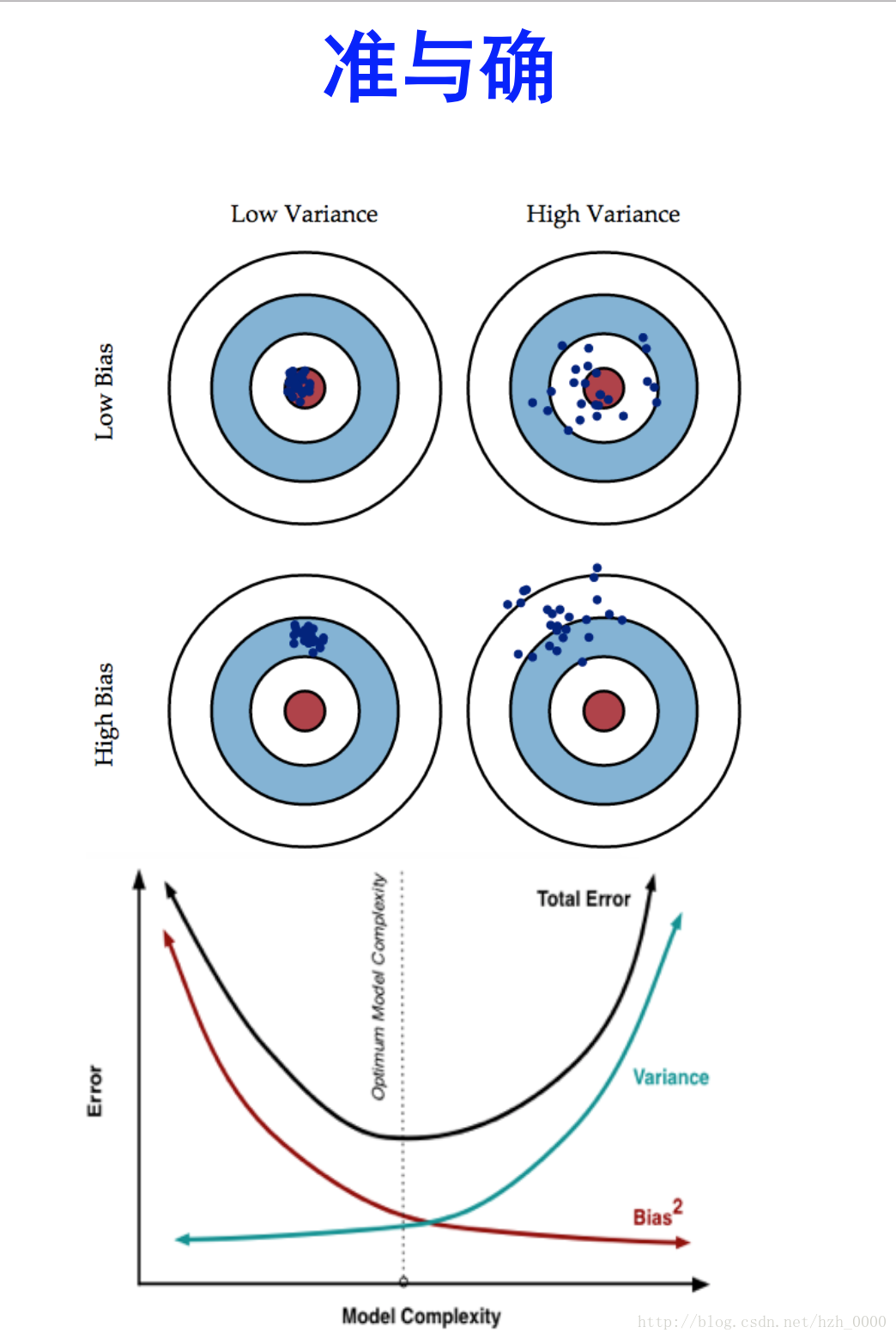
- Bias是 “用所有可能的训练数据集训练出的所有模型的输出的平均值” 与 “真实模型”的输出值之间的差异;
- Variance则是“不同的训练数据集训练出的模型”的输出值之间的差异。
bias与variance
关于cross validation中k值对bias和variance的影响
假设我们现在有一组训练数据,需要训练一个模型(基于梯度的学习,不包括最近邻等方法)。在训练过程的最初,bias很大,因为我们的模型还没有来得及开始学习,也就是与“真实模型”差距很大。然而此时variance却很小,因为训练数据集(training data)还没有来得及对模型产生影响,所以此时将模型应用于“不同的”训练数据集也不会有太大差异。而随着训练过程的进行,bias变小了,因为我们的模型变得“聪明”了,懂得了更多关于“真实模型”的信息,输出值与真实值之间更加接近了。但是如果我们训练得时间太久了,variance就会变得很大,因为我们除了学习到关于真实模型的信息,还学到了许多具体的,只针对我们使用的训练集(真实数据的子集)的信息。而不同的可能训练数据集(真实数据的子集)之间的某些特征和噪声是不一致的,这就导致了我们的模型在很多其他的数据集上就无法获得很好的效果,也就是所谓的overfitting(过学习)。
对于一系列模型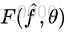
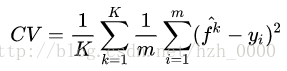
其中,m = N/K 代表每个subset的大小, N是总的训练样本量,K是subsets的数目。当K较大时,m较小,模型建立在较大的N-m上,因此CV与Testing Error的差距较小,所以说CV对Testing Error估计的Bias较小。同时每个Subsets重合的部分较大,相关性较高,如果在大量不同样本中进行模拟,CV统计量本身的变异较大,所以说Variance高。反之亦然。
过拟合
- Early stopping:对模型进行训练的过程即是对模型的参数进行学习更新的过程,这个参数学习的过程往往会用到一些迭代方法,如梯度下降(Gradient descent)学习算法。Early stopping便是一种迭代次数截断的方法来防止过拟合的方法,即在模型对训练数据集迭代收敛之前停止迭代来防止过拟合。 Early stopping方法的具体做法是,在每一个Epoch结束时(一个Epoch集为对所有的训练数据的一轮遍历)计算validation data的accuracy,当accuracy不再提高时,就停止训练。这种做法很符合直观感受,因为accurary都不再提高了,在继续训练也是无益的,只会提高训练的时间。那么该做法的一个重点便是怎样才认为validation accurary不再提高了呢?并不是说validation accuracy一降下来便认为不再提高了,因为可能经过这个Epoch后,accuracy降低了,但是随后的Epoch又让accuracy又上去了,所以不能根据一两次的连续降低就判断不再提高。一般的做法是,在训练的过程中,记录到目前为止最好的validation accuracy,当连续10次Epoch(或者更多次)没达到最佳accuracy时,则可以认为accuracy不再提高了。此时便可以停止迭代了(Early Stopping)。这种策略也称为“No-improvement-in-n”,n即Epoch的次数,可以根据实际情况取,如10、20、30……
- 正则化:L1正则,L2正则,
- Dropout:
欠拟合
- 寻找更好的特征
- 用更多的特征
参考:这里写链接内容