(KNN 是一种分类算法,它没有学习的过程,而是直接计算出预测结果)
-
KNN
-
算法步骤
(1) 计算 被预测点 到所有“训练样本”的距离
(2) 从中找出前 k 个距离最近的样本点
(3) 根据分类决策规则决定(预测) 被预测点 的类别
-
距离度量
使用不同的距离度量所确定的临近点可能是不同的。
两点间距离计算: ,
表示第 个样本, 为个样本第 个特征。
时, 为曼哈顿距离;
时, 为欧氏距离。 -
K 的选取
值可以用来描述 被预测点 的邻域的大小,其值的选取对结果影响很大。
(1) 越小,近似误差越小,预测误差越大,对噪声越敏感,越容易过拟合;(只受周围少数样本影响,加入附近有噪声点,那就有可能被分为噪声点的类别,所以容易过拟合)
扫描二维码关注公众号,回复: 4736109 查看本文章
(2) 越大,近似误差越大,预测误差越小,对噪声越不敏感,容易欠拟合。(受周围更多的样本点影响,因为噪声点较少所以不容易过拟合,但样本点多时容易欠拟合,可理解为“人多嘴杂”。假设 k=9,其中 5 个样本指向类别 1,4个样本指向类别 2,可能这个被分类样本的真实标签是 2,但此时因为 K 值变大,将离得稍远的但个数较多的类别 1 也包括进来,此时被分类样本就被错误分类。)
-
多数表决规则
在距离 被预测点 最近的 k 个样本中,哪一类别的个数最多,则 被预测点属于哪一类。
-
KNN 特点
(1) 基于样本实例计算,而非训练;
(2) 分类时开销大,属于消极学习方法;
(3) 基于局部信息预测,对噪声敏感;
(4) 可产生任意形状的决策边界,非简单线性;
(5) 受值域较大的属性影响较大,应统一量纲,归一化。
-
-
偏差与方差
我们经常用过拟合、欠拟合来定性地描述模型是否很好的解决了特定的问题。从定量的角度来说,可以用模型的偏差(Bias)与方差(Variance)来描述模型的性能。
-
偏差
偏差是指由所有采样得到的大小为 m 的训练数据集训练出所有模型的输出的 平均值(中心) 和真实标记之间的偏差。描述所有预测结果 整体 对真实标记的“偏离程度”,即所有预测分布的中心对真实标记分布的 偏离程度。可以衡量模型对数据集的学习程度。
偏差通常是由于我们对学习算法做出了错误的假设所导致的。由偏差带来的误差通常在训练误差上就能体现出来。
偏差越大,对数据集的拟合程度越差;偏差越小,拟合程度越好。
-
方差
方差是指由所有采样得到的大小为 m 的训练数据集训练出的所有模型的输出的方差。描述所有预测结果对预测结果中心的 离散程度(聚集密度),可以衡量数据扰动对模型的影响程度。
方差通常是由于模型的复杂度相对于训练样本数 m 过高导致的。由方差带来的误差通常体现在测试误差相对于训练误差的增量上。
方差越大,对噪声越敏感,越容易过拟合;方差越小,与不容易过拟合。
-
图解
我们使用射击的例子来进一步解释。假设一次射击就是一个模型对一个样本进行预测。射中靶心代表预测准确,越偏离靶心代表预测误差越大。
我们通过 n 次采样得到 n 个大小为 m 的训练样本集合,训练处 n 个模型,对同一个样本进行预测,相当于我们进行了 n 次射击。
具体对偏差与方差的理解可看图。
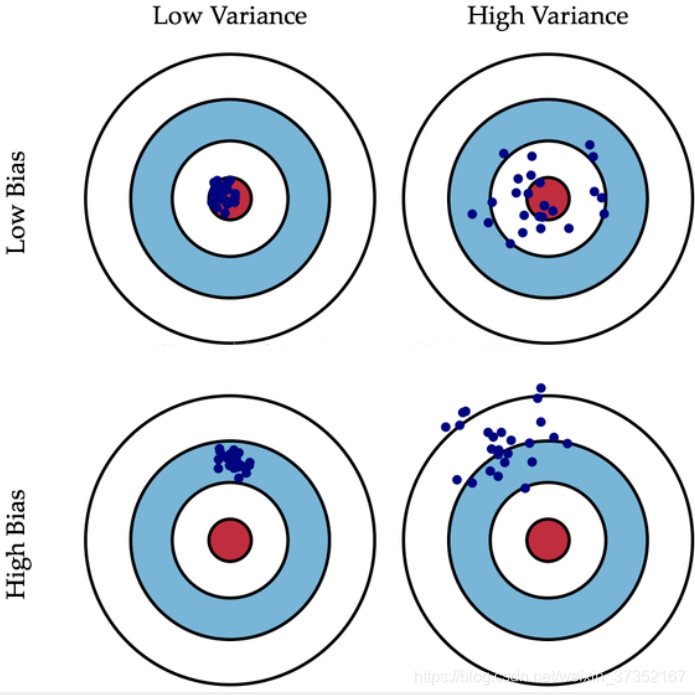
(图片来自网络)

(图片来自网络)
-