这是我很久之前看的一篇文章,论文地址【入口】,知乎上也有人讲这个【实例分割:PolarMask】,文章开源GitHub上自行搜索;最开始在【 PolarMask: 一阶段实例分割新思路 】上面看到
PolarMask: Single Shot Instance Segmentation with Polar Representation
PolarMask:单镜头实例分割与极坐标表示
https://mp.weixin.qq.com/s/EAB3lYemplztFByOvyh0Wg
1、提出问题
我们的PolarMask提出了一种新的instance segmentation建模方式(把分割物体切割),通过寻找物体的contour建模,提供了一种新的方法供大家选择。
①摘要介绍了一种新的实例分割方法——PolarMask,该方法将实例分割转换为两个并行任务:实例中心分类和稠密距离回归。PolarMask的主要优点是简单和有效。我们第一次证明了实例分割的复杂度,无论是从设计复杂度还是计算复杂度上,都可以与bbox对象检测一样。
②我们提出了极点IoU损失和极点中心,适合我们的框架。结果表明,与 损失等标准损失相比,所提出的极点IoU损失能在很大程度上简化优化过程,并能在一定程度上提高精度。与此同时,极坐标中心改进了FCOS中“centreness”的原始概念,从而进一步提高了性能。
③第一次,我们展示了一个更简单和灵活的实例分割框架,实现了与更复杂的单阶段方法,通常涉及多尺度训练和更长的训练时间的竞争性能。我们希望PolarMask能够作为单镜头实例分割的基础。
与像素级建模相比,极坐标系建模轮廓使问题简单化,且计算量更小;
与直角坐标系建模轮廓相比,极坐标系建模轮廓可以利用固定角度先验信息,进一步简化问题;

图1 -具有不同mask表示的实例分割。(a)为原始图像。(b)为像素级掩模表示。©和(d)分别以笛卡尔坐标和极坐标表示掩模的轮廓。极坐标法,用角度和距离作为坐标进行定位点
2、解决算法

整个网络和FCOS一样简单,首先是标准的backbone + fpn模型,其次是head部分,我们把fcos的bbox分支替换为mask分支,仅仅是把channel=4替换为channel=n, 这里n=36,相当于36根射线的长度。同时我们提出了一种新的Polar Centerness 用来替换FCOS的bbox centerness。
可以看到,在网络复杂度上,PolarMask和FCOS并无明显差别。

图2 - PolarMask的总体流程。左侧包含主干和特征金字塔,提取不同层次的特征。中间部分是分类和极坐标掩模回归的两个头。H、W、C分别为特征图的高度、宽度、通道,k为类别数(如COCO数据集上的k = 80), n为射线数(如n = 36)
PolarMask是一个简单、统一的网络,由一个骨干网络[13]、一个特征金字塔网络[17]和两个或三个特定于任务的heads(取决于是否预测边界框)组成。该模型获取一个输入图像,并预测从采样的正位置(实例中心候选位置)到实例轮廓的每个角度的距离,装配后输出最终的mask。
3、具体方案
本文所用的骨干网络和金字塔网络均和FCOS相同,引用的成熟网络体系。
极坐标中建模实例
(1)Polar Representation
给定一个实例mask,我们首先对实例的候选中心(xc,yc)和位于轮廓上的点(xi,yi)进行采样,i = 1,2,…,N。然后,从中心开始,n射线发射均匀角度间隔相同的∆θ(如n = 36,∆θ= 10◦),其长度是决定从中心到轮廓。
因此,我们在极坐标系中以中心和n射线为例对实例mask进行建模(轮廓)。由于角度区间是预先定义的,所以只需要预测射线的长度。
(2)Center Samples
如果位置(x,y)落在任何实例质心周围的区域,则将其视为中心样本。否则就是负样本。我们将正像素采样区域定义为特征图从质心到左、上、右、下的1.5×大步[25]。因此,每个实例的质心附近大约有9∼16像素作为中心示例。它有两个优点:(1)将阳性样本的数量从1 ~ 9∼16可以在很大程度上避免阳性和阴性样本的不平衡。然而,训练分类分支时仍需要局灶性损失[18]。质心可能不是一个实例的最佳中心样本。
给定一个集合{d1, d2,…,dn}表示一个实例的n条射线的长度,其中d-max和d-min分别为集合的最大值和最小值。
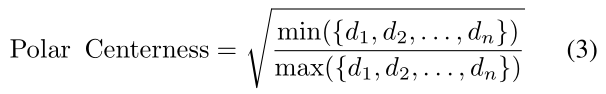
具体来说,我们添加一个单层分支,与分类分支并行,以预测一个位置的极坐标中心,如图2所示。这是一个简单而有效的策略来重新分配点的权重,使d-min和d-max越接近,分配的点的权重就越高。在推理过程中,将网络预测的极值中心与分类分数相乘,从而降低了低质量掩码的权重。

(3)Distance Regression
*如果一条射线有多个具有实例轮廓的截面点,我们直接选择长度最大的那一个。
*如果一条射线从mask外的中心开始,在一定角度上与实例的轮廓没有交点,我们将其回归目标设为最小值ε(例如,ε =10e-6)。
*如果射线与轮廓的交点恰好是亚像素(即,像素坐标不是整数),我们总是可以使用插值方法,如线性插值,来估计其回归目标。
(4)Mask Assembling
在推理过程中,网络输出分类和中心度,将中心度与分类相乘,得到最终的置信度分数。在将置信值设置为0.05之后,我们只根据每个FPN级别最高得分1k的预测值来组装掩码。将所有级别的最高预测进行合并,并应用阈值为0.5的非最大抑制(non-maximum suppression, NMS)来生成最终结果。
给定中心样本(xc,yc)和射线长度di,i = 1,2,…, n,我们可以用以下公式计算每个对应的等高线点的位置:
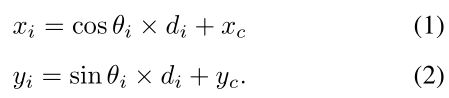
在0◦开始,等高线点一个接一个,如图3所示,最后组装整个轮廓和the mask。

4、实验结果
AP是指average precision,平均精确率,即多类预测的时候每一类的precision取平均,类似地还有AR,平均召回率。以Cascade R-CNN的一张图为例,AP50,AP60,AP70……等等指的是取detector的IoU阈值大于0.5,大于0.6,大于0.7……等等。可以看到数值越高,精确率越低,表明越难。

5、提出新问题
之前和老板汇报这篇文章,不受重视。在word上转移过来的,有点麻烦。
以下为全文翻译
摘要:在本文中,我们介绍了一种无anchor-box单镜头实例分割方法,该方法概念简单,完全卷积,可以作为mask预测模块用于实例分割,易于嵌入到大多数现成的检测方法中。我们的方法,称为PolarMask,将实例分割问题表述为在极坐标下的实例中心分类和稠密距离回归。此外,我们还提出了两种有效的方法来处理高质量中心样本的抽样和稠密距离回归的优化,这两种方法可以显著地提高性能和简化训练过程。在没有任何附加功能的情况下,PolarMask实现了32.9%的mask映射(mask mAP)。第一次,我们展示了一个更简单和灵活的实例分割框架实现竞争的准确性。我们希望所提出的PolarMask框架能够作为单镜头实例分割任务的基础和强基线。
Conclusion
PolarMask是一种具有两个并行分支的单镜头无锚实例分割方法:对实例质心进行分类,并在质心周围的采样点和轮廓线之间回归射线的密集长度。与以往将掩模预测作为空间布局的二分类来解决的工作不同,PolarMask提出了极坐标表示,并将掩模预测转化为稠密距离回归。PolarMask的设计几乎和单镜头对象探测器一样简单和干净,引入了微不足道的计算开销。我们希望所提出的PolarMask框架能够作为单镜头实例分割任务的基础和强基线。
图1-具有不同mask表示的实例分割。(a)为原始图像。(b)为像素级掩模表示。©和(d)分别以笛卡尔坐标和极坐标表示掩模的轮廓。
- Introduction
实例分割是计算机视觉的基本任务之一,它使大量的下游视觉应用成为可能。这是一个挑战,因为它需要预测一个图像中每个实例的位置和语义掩码。因此,直观的实例分割可以通过边界框检测来解决,然后在每个框内进行语义分割,采用两阶段方法,如Mask R-CNN[12]。最近在视觉领域的趋势是花更多的精力来设计边界盒检测器[14,18,25,26,28]的更简单的管道,以及随后的实例识别任务,包括实例分段[2,4,29],这也是我们这里工作的主要重点。因此,我们的目标是设计一个概念简单的mask预测模块,它可以很容易地插入许多现成的检测器,从而实现实例分割。
实例分割通常在包围着边界框的空间布局中通过二进制分类来解决,如图1(b)所示。这种像素对像素的对应预测是奢侈的,特别是在单镜头方法中。相反,我们指出,如果获得了轮廓,掩模可以成功而有效地恢复。图1©给出了一种直观的等高线定位方法,预测构成等高线的点的笛卡尔坐标。这里我们称之为笛卡尔表示法。第二种方法是极坐标法,用角度和距离作为坐标进行定位点,如图1(d)所示。
在本工作中,我们设计了基于极坐标表示的实例分割方法,因为其固有的优点是:(1)极坐标的原点可以看作对象的中心。(2)从原点出发,轮廓中的点由距离和角度决定。(3)角度具有天然的方向性,便于将点连接成一个整体轮廓。我们声称笛卡尔表示法可以同样地表现出前两个性质。但是,它缺乏第三种属性的优势。
图2-PolarMask的总体流程。左侧包含主干和特征金字塔,提取不同层次的特征。中间部分是分类和极坐标mask回归的两个头。H、W、C分别为特征图的高度、宽度、通道,k为类别数(如COCO数据集上的k = 80), n为射线数(如n = 36)
我们使用最新的对象检测器FCOS[25]来实例化这种实例分割方法,主要是为了简单。请注意,它可以使用其他探测器,如RetinaNet [18], YOLO[23]与最小的修改我们的框架。具体来说,我们建议使用PolarMask,将实例分割作为实例中心分类和极坐标下的密集距离回归,如图2所示。该模型获取一个输入图像,并预测从采样的正位置(实例中心候选位置)到实例轮廓的每个角度的距离,装配后输出最终的mask。PolarMask的整体流程几乎和FCOS一样简单和干净。它引入了微不足道的计算开销。简单性和效率是单镜头实例分割的两个关键因素,PolarMask成功地实现了这两个关键因素。
此外,PolarMask可以看作是FCOS的一个推广,或者FCOS是PolarMask的一个特例,因为边界框可以看作是只有4个方向的最简单的掩码。因此,建议在FCOS上使用PolarMask进行实例识别,只要有mask annotation可用[5,19]。
为了使极坐标表示的优点最大化,我们分别提出了极坐标中心和极坐标IoU损失来处理高质量中心样本的抽样和稠密距离回归的优化。它们相对提高了约15%的掩模精度,在更严格的定位指标下表现出可观的收益。在没有附加功能的情况下,PolarMask在具有挑战性的COCO数据集[19]上使用单模型和单尺度的训练/测试实现了掩模映射的32.9%。
The main contributions of this work are three-fold:
1、摘要介绍了一种新的实例分割方法——PolarMask,该方法将实例分割转换为两个并行任务:实例中心分类和稠密距离回归。PolarMask的主要优点是简单和有效。我们第一次证明了实例分割的复杂度,无论是从设计复杂度还是计算复杂度上,都可以与边界盒对象检测一样。
2、我们提出了极点IoU损失和极点中心,适合我们的框架。结果表明,与 损失等标准损失相比,所提出的极点IoU损失能在很大程度上简化优化过程,并能在一定程度上提高精度。与此同时,极坐标中心改进了FCOS中“centreness”的原始概念,从而进一步提高了性能。
3、第一次,我们展示了一个更简单和灵活的实例分割框架,实现了与更复杂的单阶段方法,通常涉及多尺度训练和更长的训练时间的竞争性能。我们希望PolarMask能够作为单镜头实例分割的基础和强有力的基线。
- Related Work
Two-Stage Instance Segmentation.mask R-CNN
One Stage Instance Segmentation.SSD
-
Our Method
在本节中,我们首先简要介绍所提议的PolarMask的总体架构。然后,我们用提出的极坐标表示法重新构造实例分割。接下来,我们引入一个新的极坐标中心概念来简化高质量中心样本的选择过程。最后,我们引入一个新的极值IoU损失来优化稠密回归问题。
3.1. Architecture
PolarMask是一个简单、统一的网络,由一个骨干网络[13]、一个特征金字塔网络[17]和两个或三个特定于任务的heads(取决于是否预测边界框)组成。骨干网和特征金字塔网的设置与FCOS [25]相同。虽然这些组件有许多更强大的候选组件,但我们将这些设置与FCOS对齐,以展示我们的实例建模方法的简单性和有效性。
3.2. Polar Mask Segmentation
在本节中,我们将详细描述如何在极坐标中建模实例。
Polar Representation给定一个实例掩码,我们首先对实例的候选中心(xc,yc)和位于轮廓上的点(xi,yi)进行采样,i = 1,2,…,N。然后,从中心开始,n射线发射均匀角度间隔相同的∆θ(如n = 36,∆θ= 10◦),其长度是决定从中心到轮廓。
因此,我们在极坐标系中以中心和n射线为例对实例掩模进行建模。由于角度区间是预先定义的,所以只需要预测射线的长度。通过这种方法,我们将实例分割描述为实例中心分类和极坐标下的稠密距离回归。
Mass Center 实例的中心有许多选择,例如box center或mass-center。如何选择更好的中心取决于它对掩模预测性能的影响。对box-center和mass-center的上界进行了讨论,得出mass-center更有利的结论。细节如图7所示。我们解释说,与box-center相比,mass-center有更大的概率在箱形中心的一侧剥落。尽管在一些极端的情况下,例如一个甜甜圈,mass-center和box-center都不在实例中。我们把它留作进一步研究。Center Samples 如果位置(x,y)落在任何实例质心周围的区域,则将其视为中心样本。否则就是负样本。我们将正像素采样区域定义为特征图从质心到左、上、右、下的1.5×大步[25]。因此,每个实例的质心附近大约有9∼16像素作为中心示例。它有两个优点:(1)将阳性样本的数量从1 ~ 9∼16可以在很大程度上避免阳性和阴性样本的不平衡。然而,训练分类分支时仍需要局灶性损失[18]。质心可能不是一个实例的最佳中心样本。更多的候选点使得自动找到一个实例的最佳中心成为可能。我们将在3.3节中详细讨论。
Distance Regression 给定一个中心点(xc,yc)和位于轮廓上的切点(xi,yi), i=1,2,…,N,角θ和中心点之间的距离d我每个轮廓点可以很容易地计算,需要N的射线可以在大多数情况下。然而,也有一些特例:
*如果一条射线有多个具有实例轮廓的截面点,我们直接选择长度最大的那一个。
*如果一条射线从mask外的中心开始,在一定角度上与实例的轮廓没有交点,我们将其回归目标设为最小值ε(例如,ε =10e-6)。
*如果射线与轮廓的交点恰好是亚像素(即,像素坐标不是整数),我们总是可以使用插值方法,如线性插值,来估计其回归目标。
我们认为,这些极端情况是限制极坐标表示法的上界达到100%AP的主要障碍。然而,它不应该被视为极坐标表示法不如非参数像素级表示法。证据是双重的。首先,在实际应用中,即使是像素级 的表示也远远达不到100% AP的上限,因为一些操作,比如向下采样,是必不可少的。第二,当前无论是像素表示还是极坐标表示,性能都远远超出了上限。因此,建议将研究工作更好地用于提高模型的实际性能,而不是理论上限。
回归分支的训练是非平凡的。首先,PolarMask中的掩模分支实际上是一个密集的距离回归任务,因为每个训练实例都有n条射线(例如n=36)。这可能导致回归损失与分类损失之间的不平衡。其次,例如,它的n条射线是相关的,应该作为一个整体进行训练,而不是作为一组独立的回归例子。因此,我们提出了极性欠条损失,在3.4节中详细讨论。
Mask Assembling 在推理过程中,网络输出分类和中心度,将中心度与分类相乘,得到最终的置信度分数。在将置信值设置为0.05之后,我们只根据每个FPN级别最高得分1k的预测值来组装掩码。将所有级别的最高预测进行合并,并应用阈值为0.5的非最大抑制(non-maximum suppression, NMS)来生成最终结果。这里我们介绍了掩模的装配过程和一种快速的NMS过程。
给定中心样本(xc,yc)和射线长度di,i = 1,2,…, n,我们可以用以下公式计算每个对应的等高线点的位置:在0◦开始,等高线点一个接一个,如图3所示,最后组装整个轮廓和the mask。
图3 -mask组装。极坐标表示提供了一个方向角。轮廓点一个接一个从0◦(粗体线)开始,组装整个轮廓和口罩。
我们应用NMS来删除冗余的mask。为了加快这个过程,我们计算了mask的最小边界盒,然后根据盒的IoU应用NMS。我们验证了这种简化的后处理不会对最终的掩模性能产生负面影响。
3.3. Polar Centerness
在不引入超参数的情况下,引入中心度[25]来抑制这些低质量的被检测对象,并证明了其在物体边界盒检测中的有效性。然而,直接将它传输到我们的系统可能是次优的,因为它的中心是为包围盒设计的,而我们关心mask预测。
给定一个集合{d1, d2,…,dn}表示一个实例的n条射线的长度,其中d-max和d-min分别为集合的最大值和最小值。
具体来说,我们添加一个单层分支,与分类分支并行,以预测一个位置的极坐标中心,如图2所示。这是一个简单而有效的策略来重新分配点的权重,使d-min和d-max越接近,分配的点的权重就越高。实验表明,极坐标中心可以提高定位精度,特别是在严格的定位条件下,如 。
Figure 4 – Polar Centerness. 用极坐标中心来降低回归任务的权重,例如中间图中红线所示的高度多样性的射线长度。这些例子总是很难优化和生产低质量的口罩。在推理过程中,将网络预测的极值中心与分类分数相乘,从而降低了低质量掩码的权重。
3.4. Polar IoU Loss
如前所述,极坐标分割方法将实例分割的任务转化为一组回归问题。在大多数情况下,在对象领域检测和分割、 [10]和IoU loss[27]是监督回归问题的两种有效方法。但是,smooth-l - 1 loss忽略了相同对象的样本之间的相关性,导致定位精度下降。然而,IoU损失的训练过程将优化作为一个整体来考虑,并直接优化兴趣度量。然而,计算所预测mask的IoU和它的地面真值是非常棘手的,并且很难实现并行计算。在这项工作中,我们推导出一个简单而有效的算法来计算基于极坐标向量表示的mask-IoU,并获得具有竞争力的性能,如图5所示。
我们从IoU的定义开始引入极点IoU损失,即预测mask与ground-truth之间的相互作用面积比联合面积的比值。以极坐标系统为例,mask-IoU计算如下:
在回归预测目标d和d∗射线长度,角度θ。然后把它转换成离散形式
当N趋于无穷时,离散形式等于连续形式。我们假设射线是统一发出,所以 ,进一步简化了的表情。我们从经验上观察到,将power form丢弃并简化为以下形式,对性能影响不大:
极坐标IoU损失是极坐标IoU的二元交叉熵损失。因为最优的IoU总是1,所以损失实际上是负对数的极值IoU :
我们提出的极性IoU损失具有两个优点:(1)它是可微的,可以反向传播;并且很容易实现并行计算,从而促进了快速的训练过程。(2)整体预测回归目标。我们的实验表明,与 损耗相比,它大大提高了整体性能。(3)另外,Polar IoU Loss能够自动保持稠密距离预测的分类损失与回归损失之间的平衡。我们将在实验中详细讨论它。

图5 –Mask IoU的极坐标表示。极坐标下的掩模IoU(相互作用面积除以并集面积)可以通过微分IoU面积对微分角度积分来计算。
4. Experiments
给出了具有挑战性的COCO基准[19]上实例分割的结果。按照惯例[12,4],我们使用80K的火车图像和35K的val图像子集(trainval35k)的联合进行训练,并报告其余5K的valv .图像(minival)的烧蚀情况。我们还比较了测试-开发的结果。除非另有说明,我们采用1×训练策略[11,3],对图像短边进行单尺度训练和测试。
Training Details
4.1. Ablation Study
Verification of Upper Bound
Number of Rays

Figure 6 –PolarMask与 的可视化。极性IoU丢失实现了对实例轮廓的更精确的回归,而 则表现出了系统的伪影。
Polar Centerness vs. Cartesian Centerness
Box Branch
Backbone Architecture
Speed vs. Accuracy
4.2. Comparison to state-of-the-art
我们在COCO数据集上评估PolarMask,并将测试-开发结果与最先进的方法(包括单阶段和两阶段模型)进行比较,如表2所示。PolarMask输出如图8所示。
没有任何附加功能,PolarMask能够使用更复杂的onestage方法来实现具有竞争力的性能。由于我们的目标是设计一个概念简单、灵活的掩模预测模块,因此多尺度训练、长时间训练等许多改进方法[24,22]超出了本工作的范围。我们认为YOLACT[2]和PolarMask的差距来自于更多的训练时间和数据扩充。如果将这些方法应用于PolarMask,则可以很容易地提高性能。张量掩模[4]和PolarMask的间隙是由张量双金字塔和对齐表示引起的。考虑到这些方法是时间成本法和内存成本法,我们不会将它们插入PolarMask。

Figure 8 –使用ResNet-101-FPN对COCO test-dev图像进行PolarMask,结果得到30.4% mask AP
