前言:
在章节前面的文章中我们已经讲到了hadoop的搭建过程,只不过是伪分布模式下的环境,在我们真实的生产环境上是绝对不会以这种方式来部署我们的项目的,真正的部署方式都是以高可用的模式,分布再很多的服务器上。
为什么要分别部署到不同的服务器上呢,其实很大的一个原因是要保证负载均衡,也就是要雨露均沾嘛,(只玩一人迟早会坏掉,别人也要休息的时间嘛)除了负载均衡外,还要保证数据的安全,如果将数据只存放在一台服务器上,那么如果这台服务器的磁盘坏掉了,那我们的数据岂不丢失了,这就有了分布式的环境,将所有的数据复制备份到多台服务器上,这下就好了,如果其中的一台KO了,那么我还可以从其他的服务器上读取,就保证了数据的安全,我们称其为数据的冗余。
既然是集群,那么肯定有多台机器,这么多机器那必然要有一个领导者,来指挥其他的服务器,没有领导者那显然是要乱套的,有了一个领导者我们还要保证其的健康,你看哪个领导人他什么事都自己做吗,显然没有,一些不重要的活当然可以给秘书或者小弟干啊,于是hadoop 2.x 就出现了SecondaryNamenode来减轻hadoop启动时的负担。
就完全了吗? 没有,领导人毕竟是人,他也有罢工的时候,机器毕竟是机器它也有宕机的时候,俗话说国不能一日无主,那么hadoop也一样它也不能一刻么有namenode,那怎么办呢,领导人下台了,那么民众又要新选举一位出来当任,而hadoop也一样,当当前活跃的namenode挂掉后,它就会自动从自己的备用namenode节点中选一台出来,但此大任,这就是Hadoop的HA(High availability) 高可用
好了这里大概的将了一下什么是HA,因为本文章主要还是以部署为主,这里就不详细的讲了,后面再看有时间做一个hadoop的专门讲解。
!!! 下面步入正题 !!!
首先是服务器的规划:
我这里使用虚拟机模拟的三台主机的环境
这里的用户需要自己添加就不用多说了
| HostName | Host | user | password |
|---|---|---|---|
| master | 192.168.96.66 | hadoop | 123456 |
| slave1 | 192.168.96.68 | hadoop | 123456 |
| slave2 | 192.168.96.70 | hadoop | 123456 |
| HostName | RescoeManger | Namenode | ZKFC | DataNode | NodeManger | JournalNode | Zookeeper |
|---|---|---|---|---|---|---|---|
| master | √ | √ | √ | √ | √ | √ | √ |
| slave1 | × | √ | √ | √ | √ | √ | √ |
| slave2 | √ | × | × | √ | √ | √ | √ |
- 1、首先还是安装jdk:
这个太简单了都是一样,博主前面的文章已经很详细的介绍了jdk的安装,这里就跳过了 - 2、配置免密登录
ssh-keygen -t rsa
只需一直按回车即可
cd ~/.ssh
cat id_rsa.pub >> authorized_keys
我们要分别再三台服务器做同样的操作
然后将每台authorized_keys (也就是rsa加密的公钥信息)的内容汇总到master这台服务器上 最后汇总的结果应该是这样:
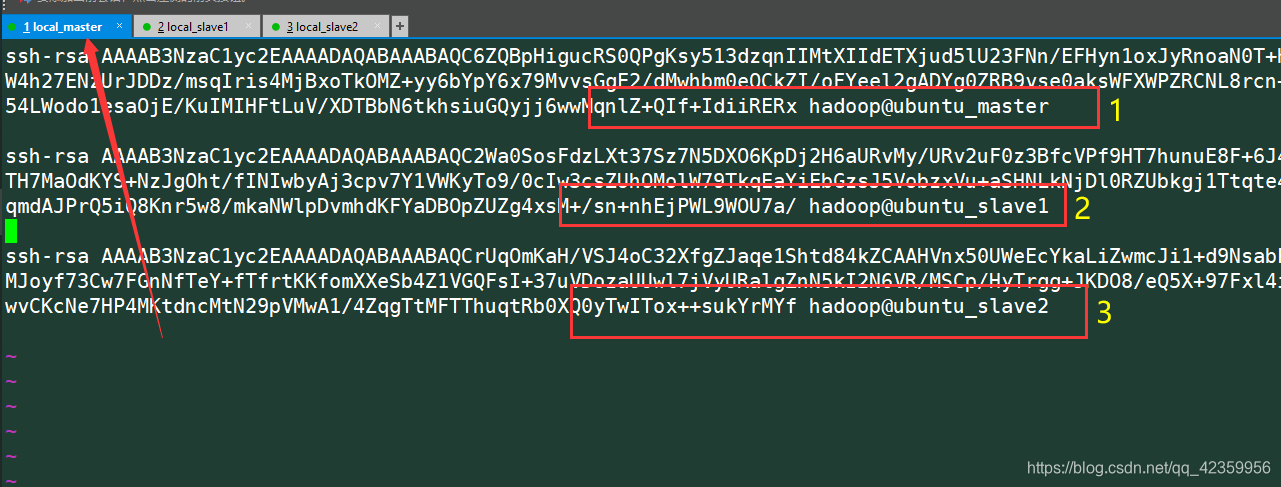
然后将每台服务器上的这个authorized_keys都改成上面汇总的这个公钥池
(我这里是图方便 其实用不了两两都互通的 新手还是照做吧)
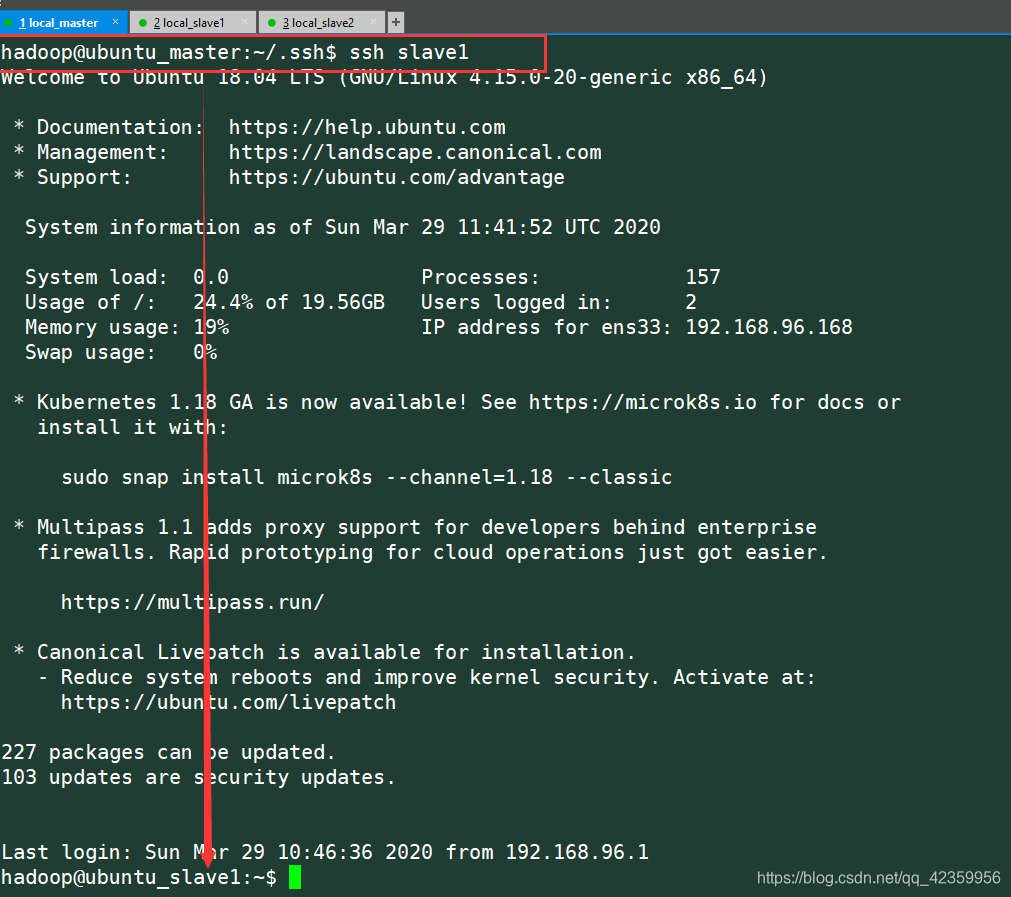
ssh slave1
然后试一下能否直接不输入密码就能连接上
第一次访问应该会弹一个Host的确认信息,输入yes就行
- 3、安装zookeeper (这里是安装分布式的所以会和前面的有所不同)
首先还是将下载好的zookeeper进行解压到指定目录下
zookeeper 清华镜像
tar -zxvf zookeeper-3.4.14.tar.gz -C ~/opt/
cd opt/
ln -s zookeepr-3.4.14 zookeeper
cd zookeeper/conf
cp zoo_sample.cfg zoo.cfg
vim cfg
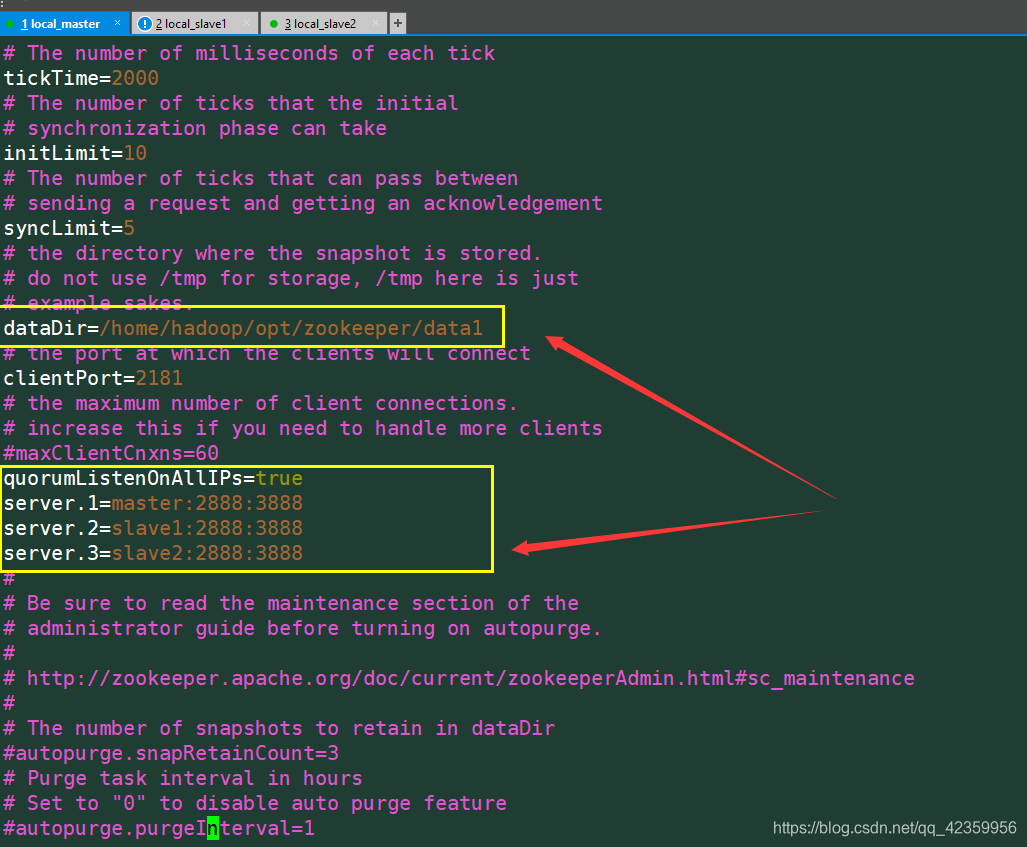
cd ~/opt/zookeeper/
mkdir data1
echo "1" >> data1/myid
注意:三台服务器都要这样配置,其中配置文件中dataDir 末尾的data1每台服务器是配置不同的
以我的来说就是
master 是 data1 那么就要再zookeeper目录下新建data1目录 然后新建一个文件写入表明自己身份的id 也就是1 配置文件中server.1 这个1就是你的id三台服务器必须不一样
slave1 就应该是新建 data2 然后新建文件myid 填入 2
slave2 就应该是新建 data3 然后新建文件myid 填入 3
- 4、配置hadoop
Hadoop清华镜像
首先还是下载然后解压
tar -zxvf hadoop2.7.7.tar.gz -C ~/opt
cd opt ln -s hadoop2.7.7 hadoop
cd opt/hadoop/etc/hadoop
这里需要配置六个文件
hadoop-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
slaves
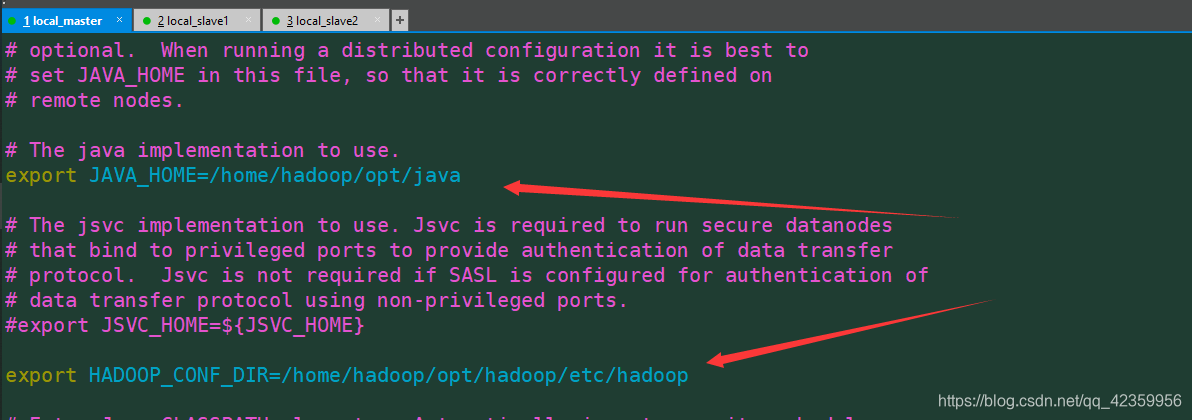
vim hadoop-env.sh
只需更改箭头所指的两个位置即可
vim core-site.xml
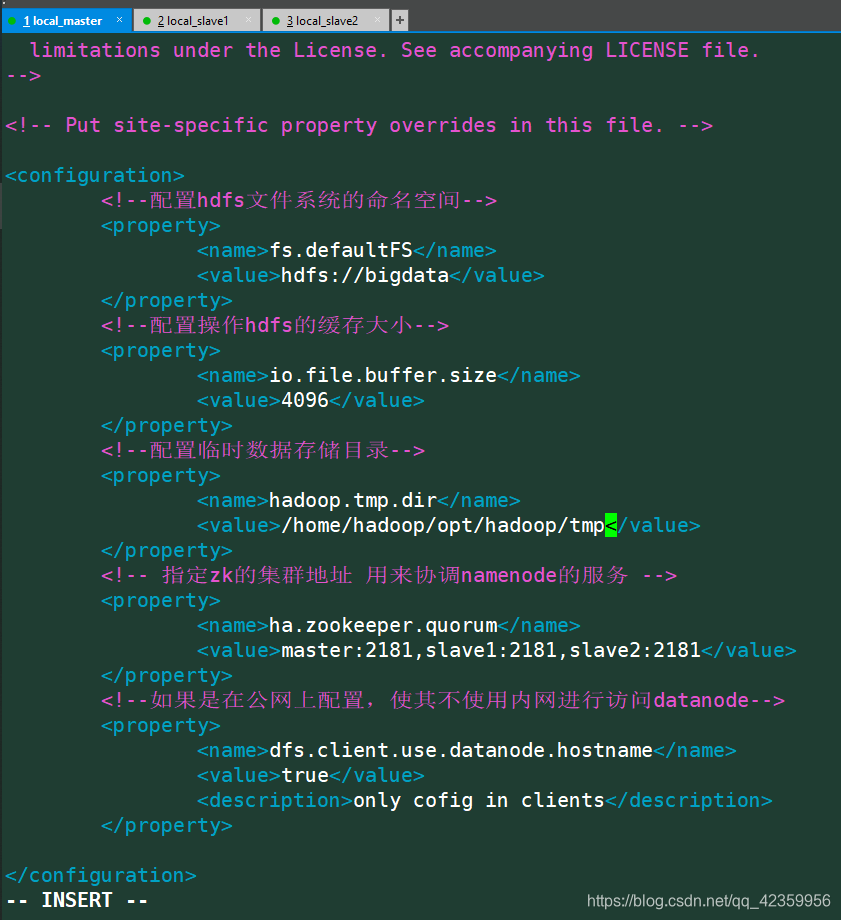
配置内容:
<configuration>
<!--配置hdfs文件系统的命名空间-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata</value>
</property>
<!--配置操作hdfs的缓存大小-->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!--配置临时数据存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/opt/hadoop/tmp</value>
</property>
<!-- 指定zk的集群地址 用来协调namenode的服务 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
<!--如果是在公网上配置,使其不使用内网进行访问datanode-->
<property>
<name>dfs.client.use.datanode.hostname</name>
<value>true</value>
<description>only cofig in clients</description>
</property>
</configuration>
vim hdfs-site.xml
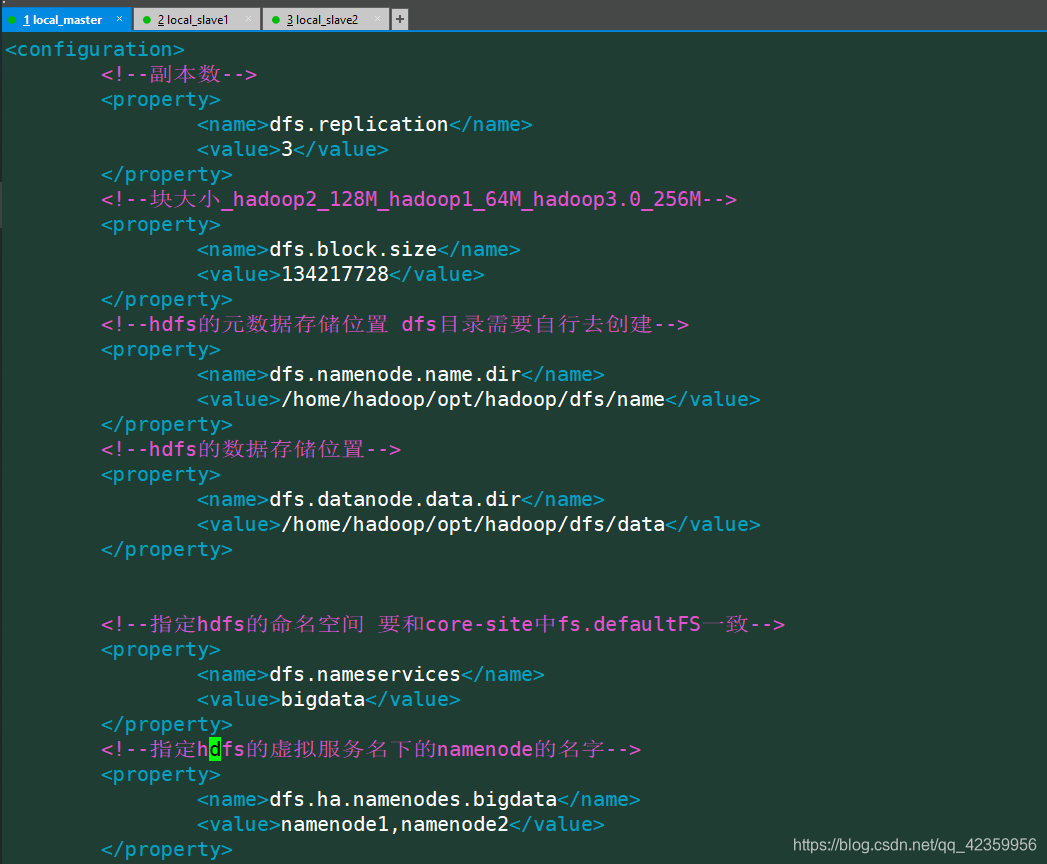
! ! ! 这个文件配置有点多一定要仔细 ! ! !
配置内容
<configuration>
<!--副本数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--块大小_hadoop2_128M_hadoop1_64M_hadoop3.0_256M-->
<property>
<name>dfs.block.size</name>
<value>134217728</value>
</property>
<!--hdfs的元数据存储位置 dfs目录需要自行去创建-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/opt/hadoop/dfs/name</value>
</property>
<!--hdfs的数据存储位置-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/opt/hadoop/dfs/data</value>
</property>
<!--指定hdfs的命名空间 要和core-site中fs.defaultFS一致-->
<property>
<name>dfs.nameservices</name>
<value>bigdata</value>
</property>
<!--指定hdfs的虚拟服务名下的namenode的名字-->
<property>
<name>dfs.ha.namenodes.bigdata</name>
<value>namenode1,namenode2</value>
</property>
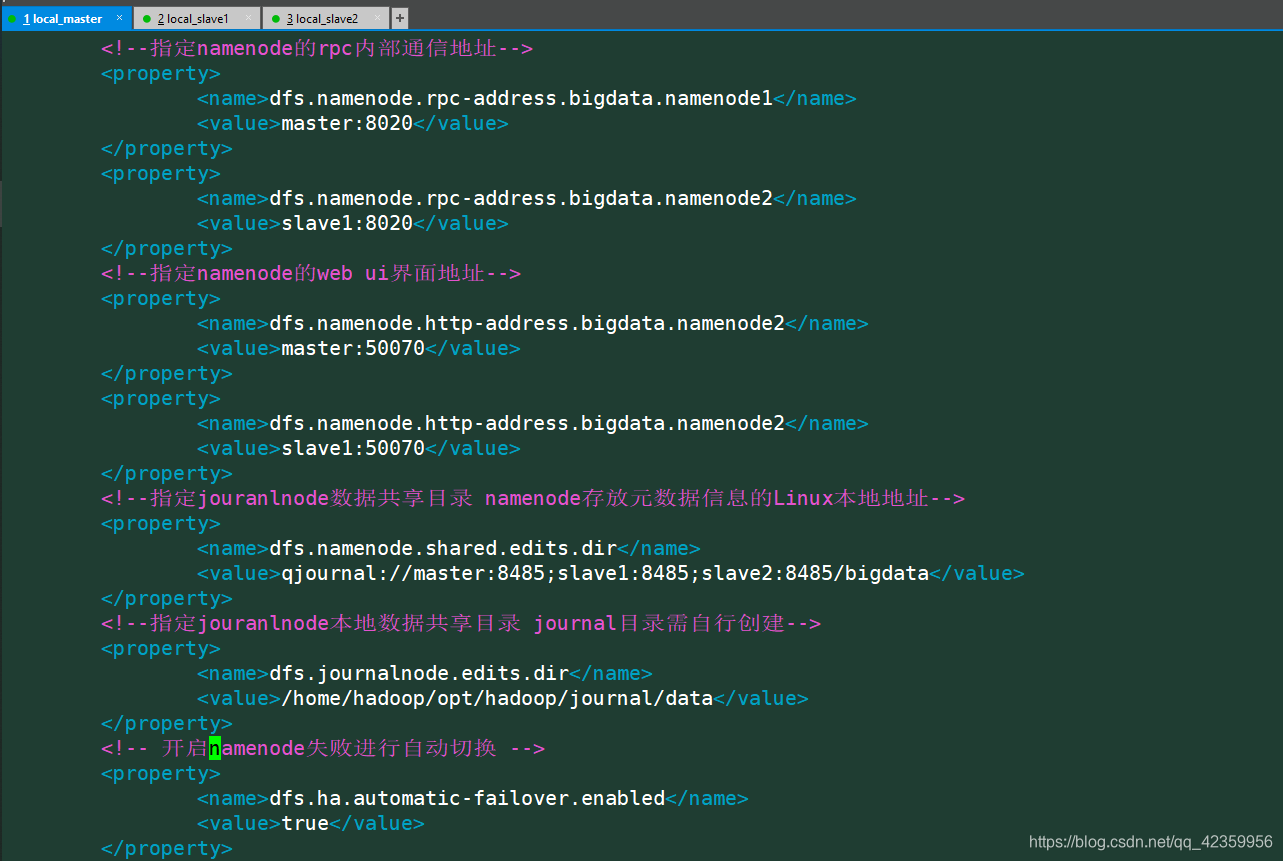
<!--指定namenode的rpc内部通信地址-->
<property>
<name>dfs.namenode.rpc-address.bigdata.namenode1</name>
<value>master:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.bigdata.namenode2</name>
<value>slave1:8020</value>
</property>
<!--指定namenode的web ui界面地址-->
<property>
<name>dfs.namenode.http-address.bigdata.namenode2</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.bigdata.namenode2</name>
<value>slave1:50070</value>
</property>
<!--指定jouranlnode数据共享目录 namenode存放元数据信息的Linux本地地址-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;slave1:8485;slave2:8485/bigdata</value>
</property>
<!--指定jouranlnode本地数据共享目录 journal目录需自行创建-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/opt/hadoop/journal/data</value>
</property>
<!-- 开启namenode失败进行自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
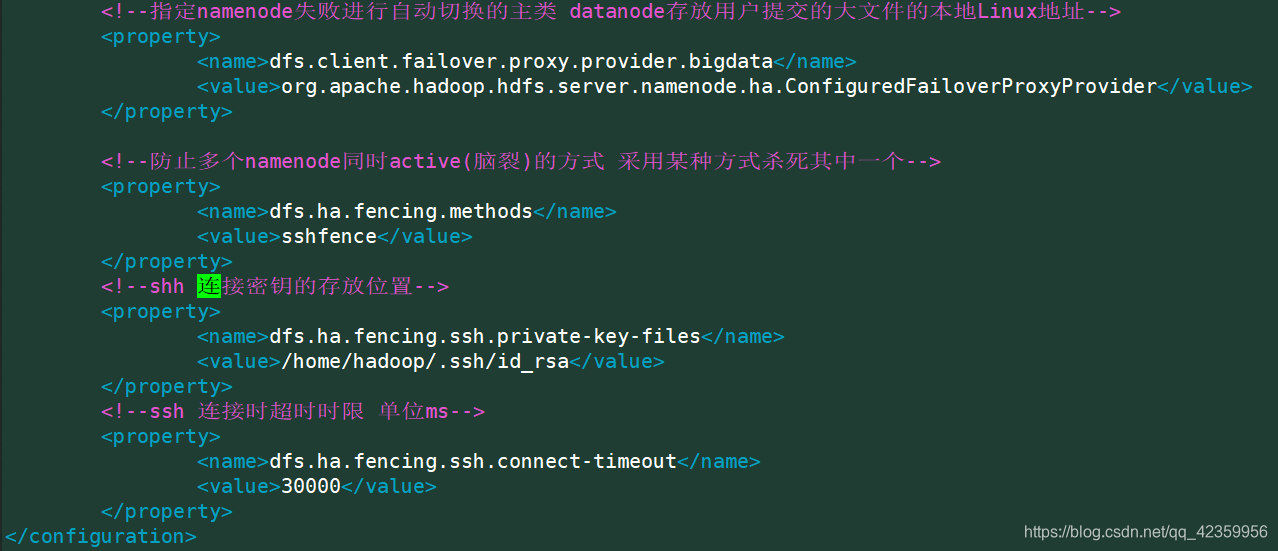
<!--指定namenode失败进行自动切换的主类 datanode存放用户提交的大文件的本地Linux地址-->
<property>
<name>dfs.client.failover.proxy.provider.bigdata</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--防止多个namenode同时active(脑裂)的方式 采用某种方式杀死其中一个-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!--shh 连接密钥的存放位置-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!--ssh 连接时超时时限 单位ms-->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
vim mapred-site.xml
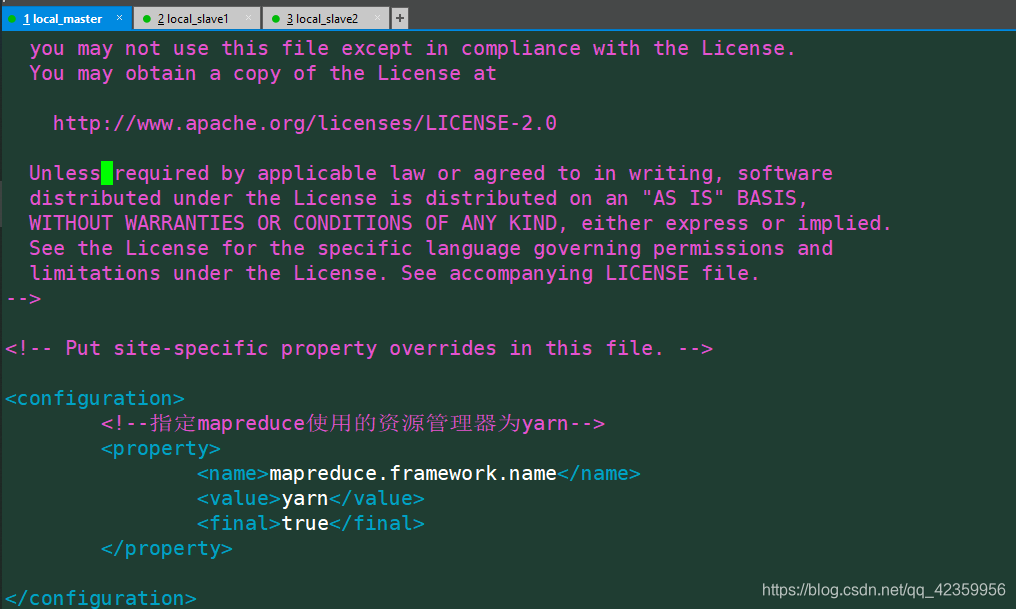
配置内容:
<configuration>
<!--指定mapreduce使用的资源管理器为yarn-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
</property>
</configuration>
vim yarn-site.xml
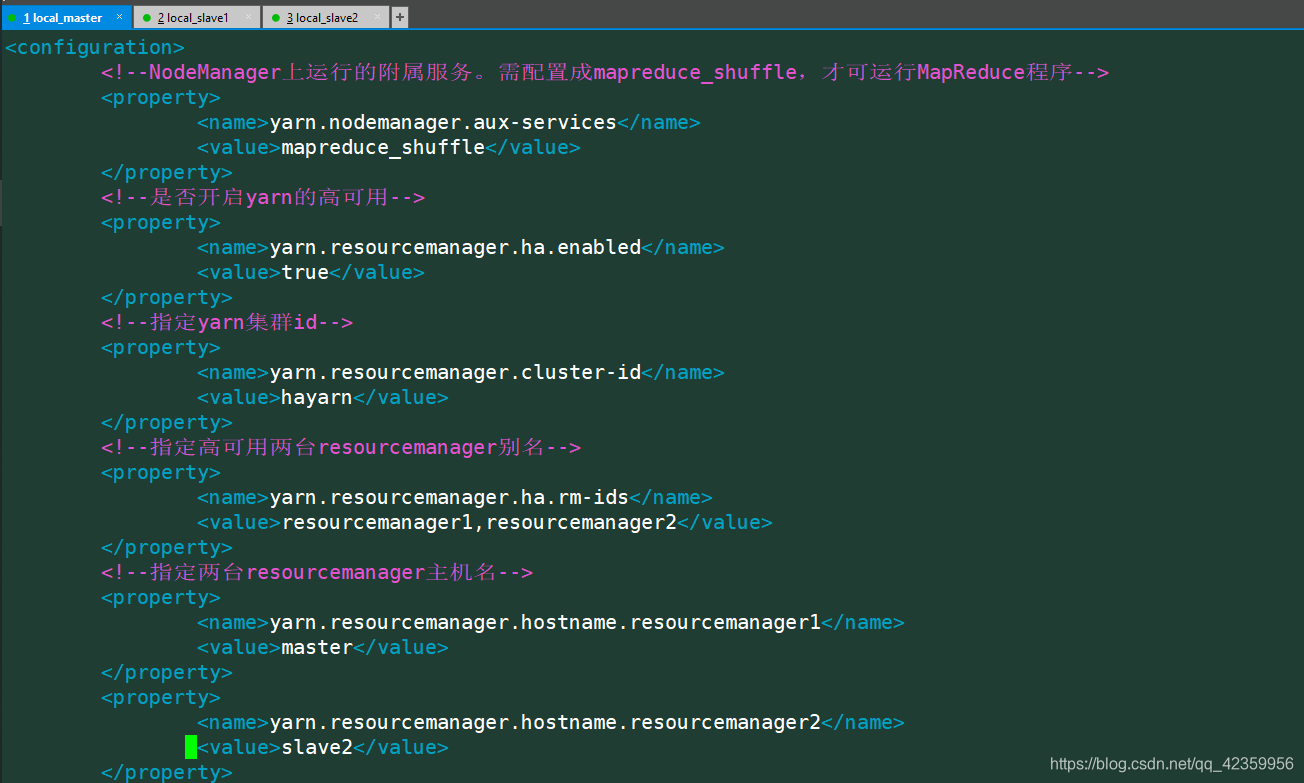
配置内容:
<configuration>
<!--NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--是否开启yarn的高可用-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--指定yarn集群id-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>hayarn</value>
</property>
<!--指定高可用两台resourcemanager别名-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>resourcemanager1,resourcemanager2</value>
</property>
<!--指定两台resourcemanager主机名-->
<property>
<name>yarn.resourcemanager.hostname.resourcemanager1</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.resourcemanager2</name>
<value>slave2</value>
</property>
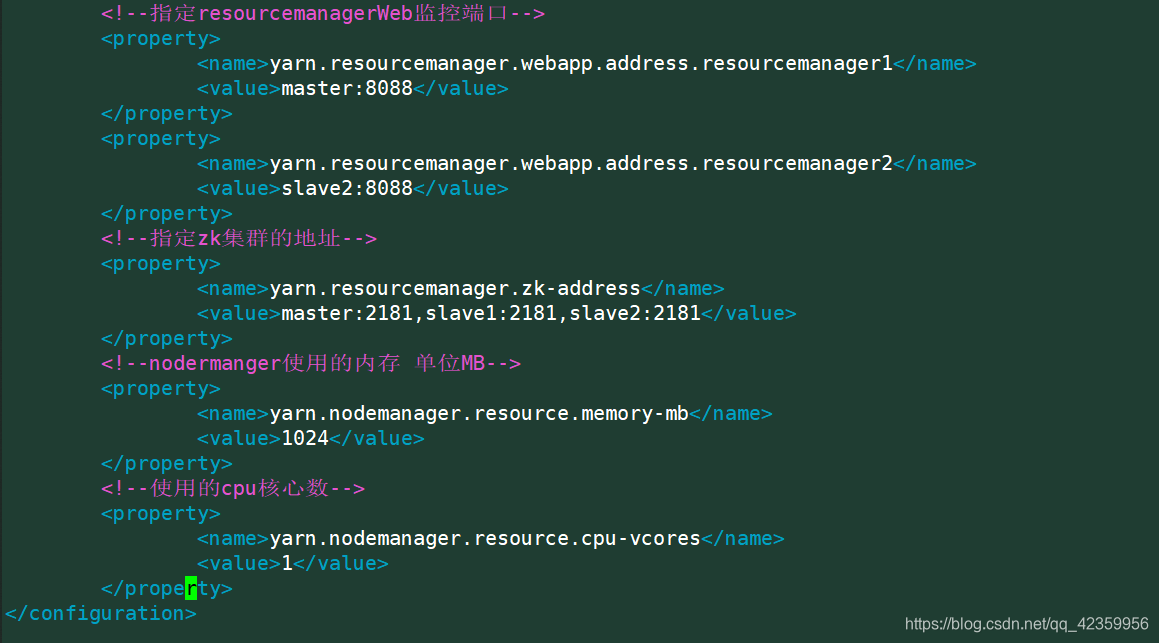
<!--指定resourcemanagerWeb监控端口-->
<property>
<name>yarn.resourcemanager.webapp.address.resourcemanager1</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.resourcemanager2</name>
<value>slave2:8088</value>
</property>
<!--指定zk集群的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
<!--nodermanger使用的内存 单位MB-->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
<!--使用的cpu核心数-->
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
</configuration>
vim salves
然后再hadoop目录下将刚才配置的信息中没有建的目录建一下
cd ~/opt/hadoop
mkdir journal
mkdir dfs
mkdir tmp
最后配置环境变量
vim ~/.bashrc
source ~/.bashrc

三台服务器均要一样的配置
- 5、启动测试
注意初次启动一定要按照下面的顺序进行
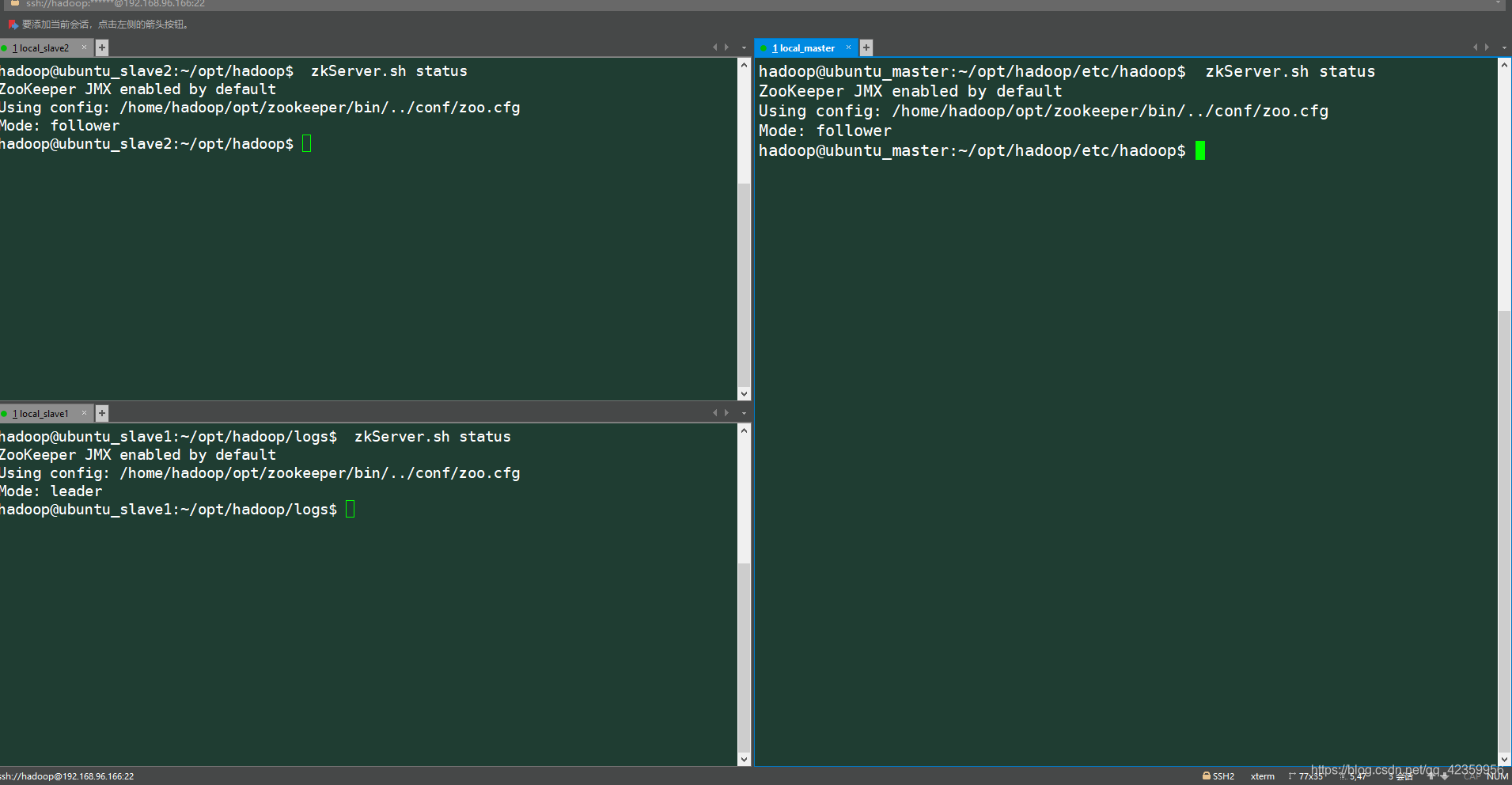
(1)分别再三台服务器上启动zookeeper
zkServer.sh start # 启动zookeeper
zkServer.sh status # 查看当前身份
(2)启动JournalNode
hadoop-daemons.sh start journalnode

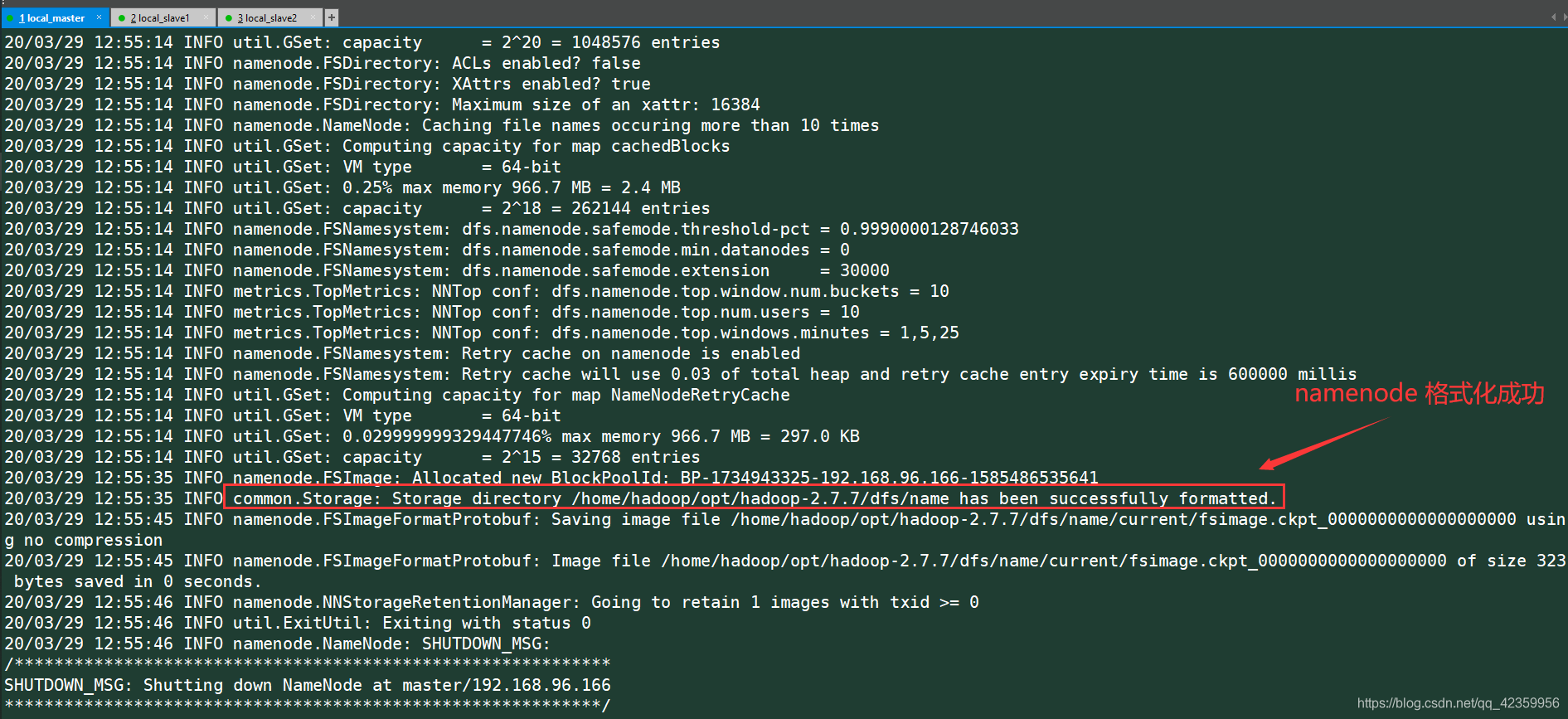
(3) 格式化namenode(要在配置的两个namenode中选一个执行)
hdfs namenode -format
(4) 在另外一台namenode机器上拉取前面格式化的namenode 信息
hdfs namenode -bootstrapStandby
(5)格式化zkfc
hdfs zkfc -formatZK
(6)启动整个集群
start-all.sh
# 中间有stop first 提示不用管是因为我们前面已经启动了
(7)查看与测试集群
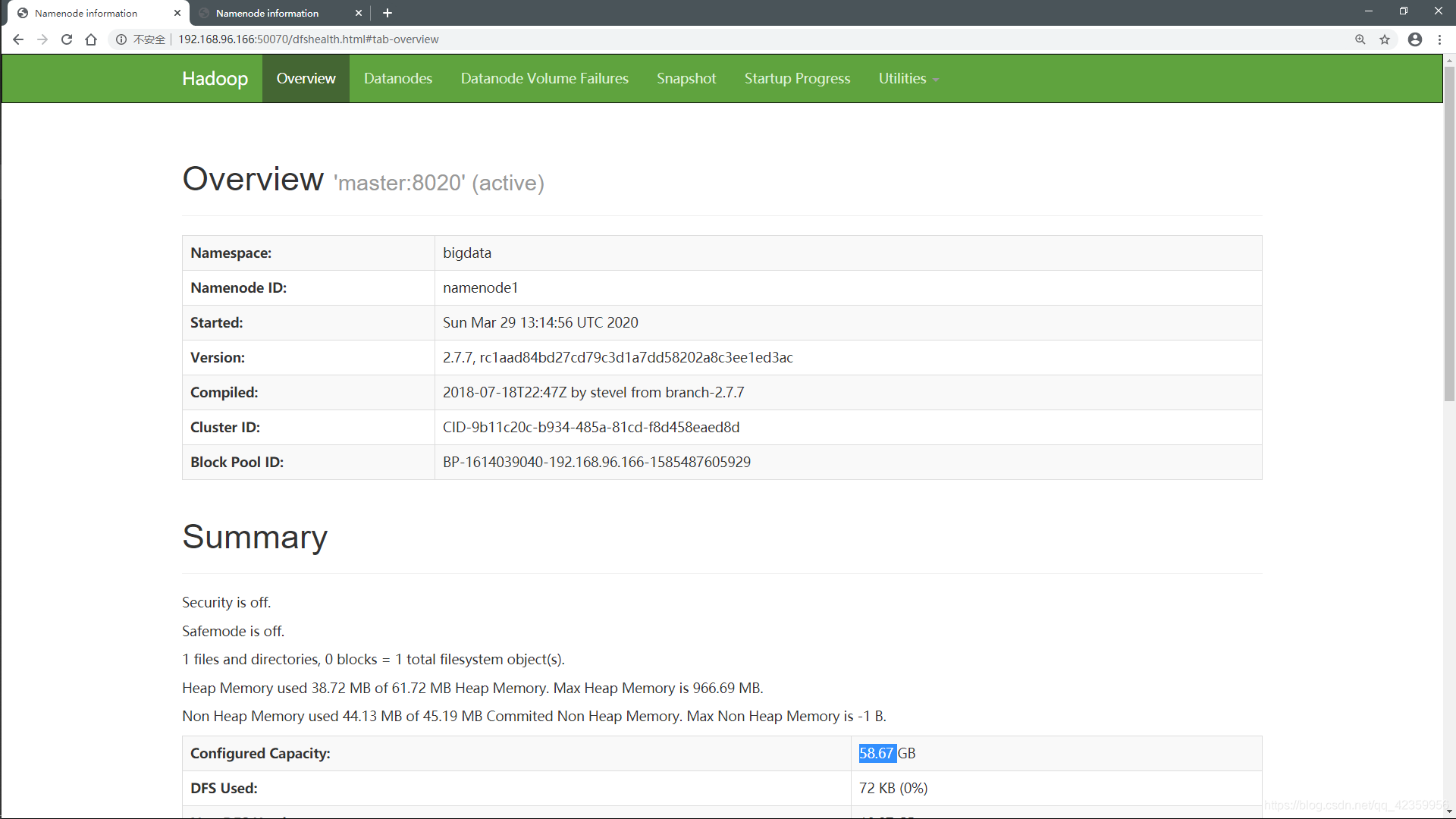
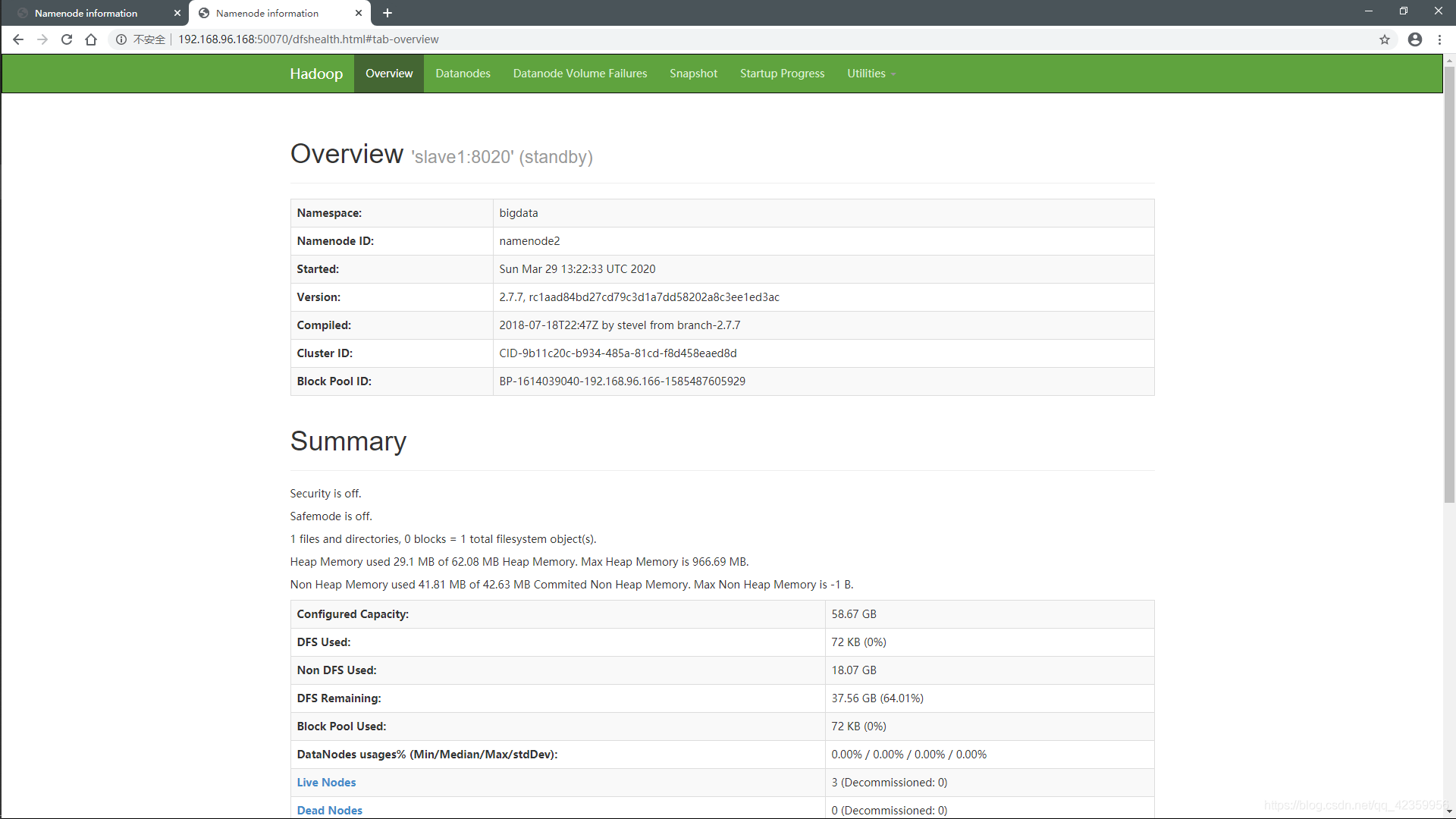
从web端看我们发现两个namenode一个处于活跃状态,一个处于待命状态,
我们来做个测试将master这个namenode节点停掉看看
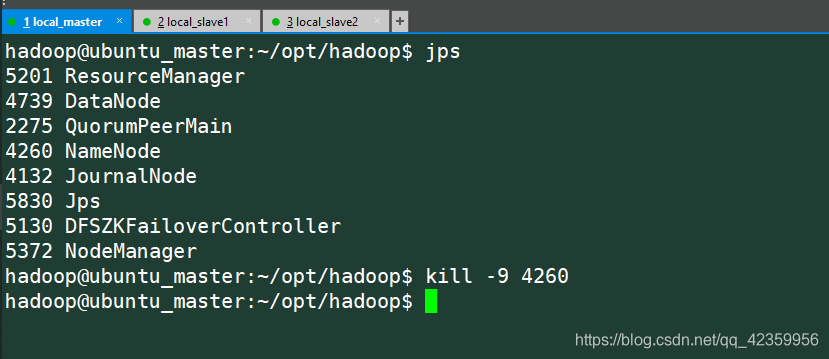
我们再来看web端的信息:
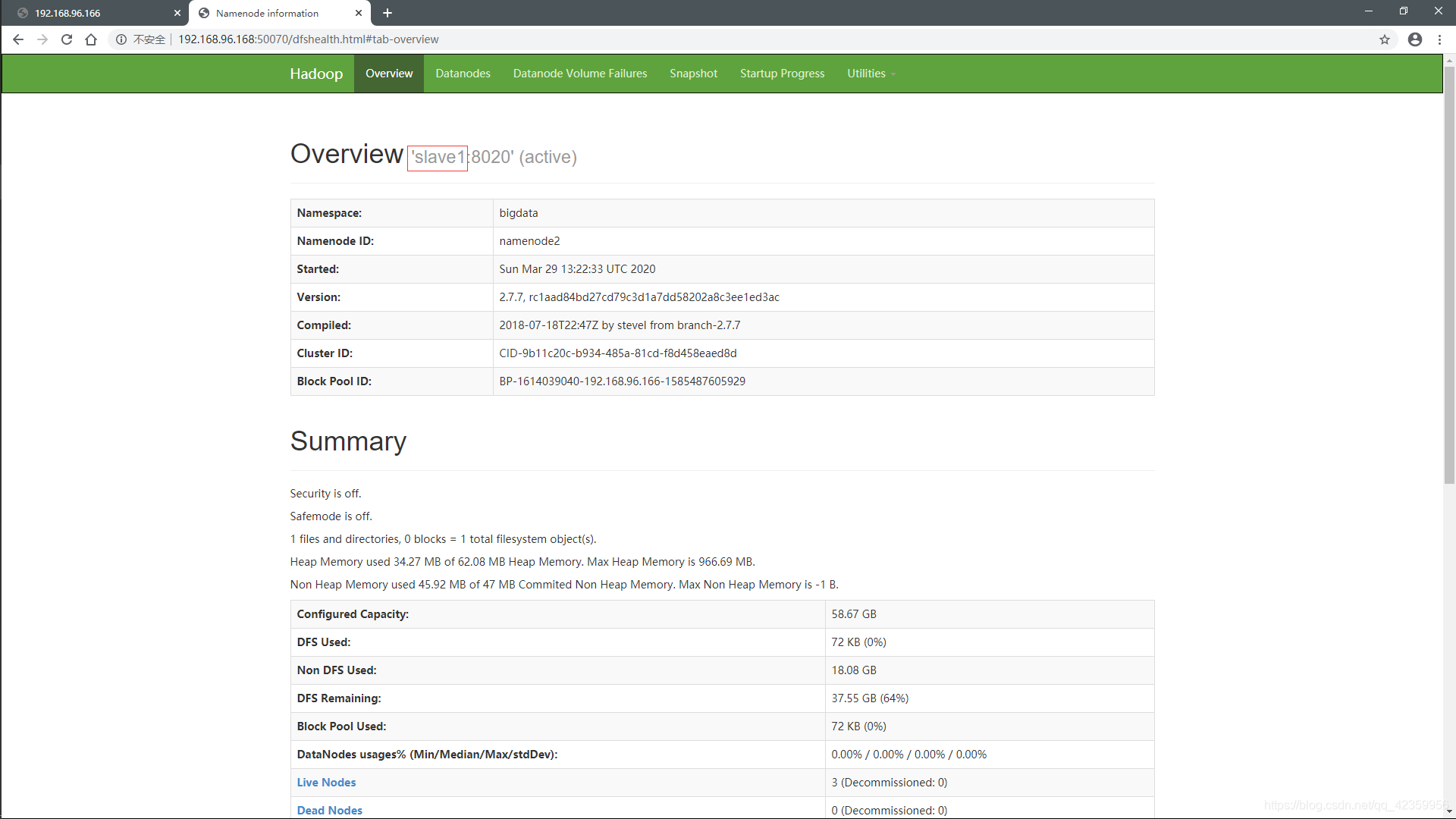
以前处于待命状态的namenode开始工作了变成活跃的了,
我们再来hdfs做一次查询,发现也是正常的(就算有一个namenode挂掉还是额能够工作):

我们再把刚刚挂掉的namenode 启动起来:
hadoop-daemon.sh start namnode
查看网页端反馈:
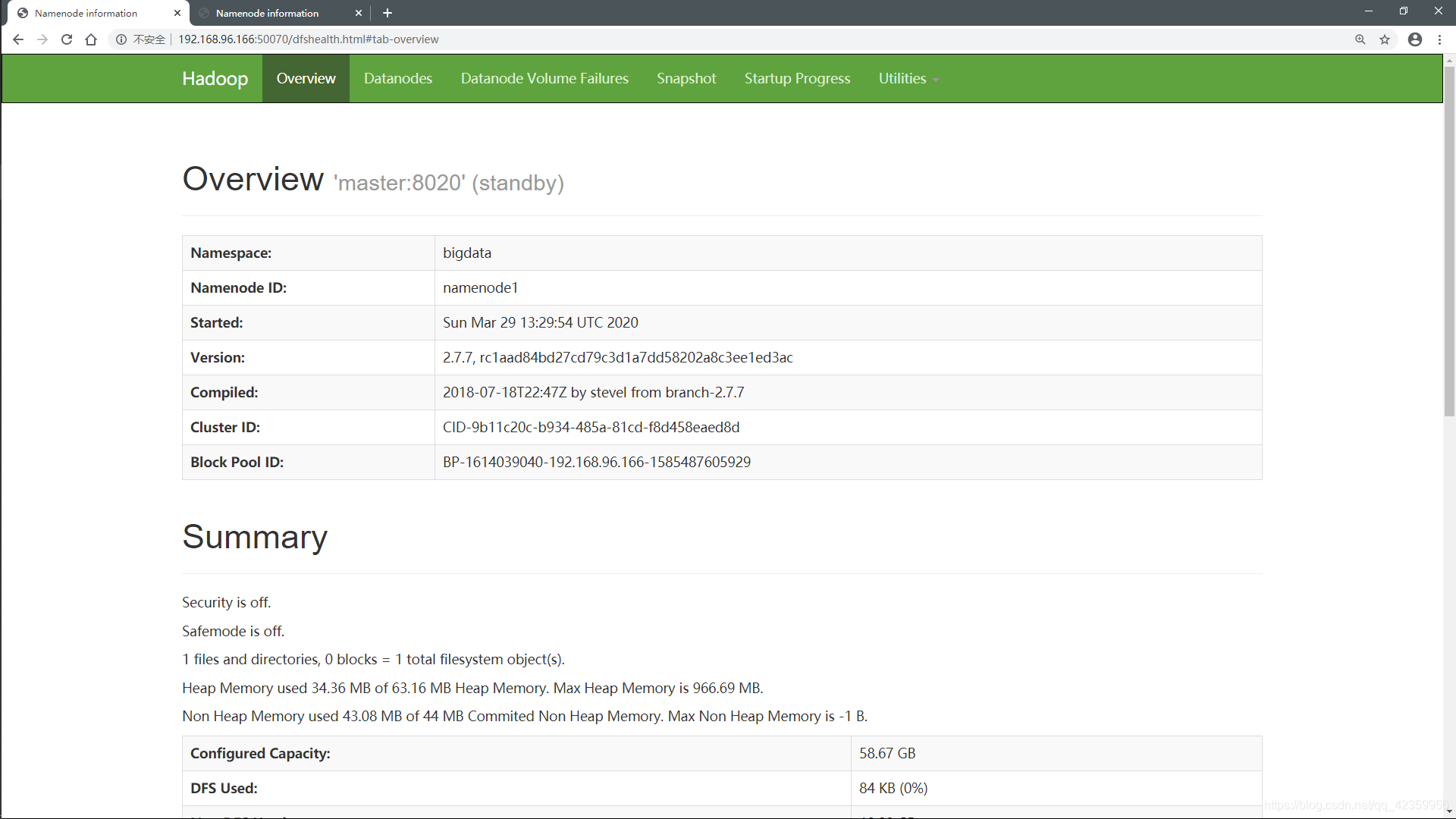
因为当前有namenode处于活跃状态,所以新启动的这个namenode就进入了待命状态。
好了hadoop的高可用已经搭建完成,时间也不早了,该去休息了,熬夜肝博客啊,如果你喜欢就点个赞在走呗! 有问题可以私聊博主,或者评论区留言也行,大家一同进步!!
