所需环境:
关闭所有防火墙
3台centos7(建议配置静态ip)
master 192.168.200.128
slave1 192.168.200.129
slave2 192.168.200.130
1. 配置ssh免密登录
2. 配置jdk
3. 配置hadoop
修改配置文件
需要配置的文件的位置为/home/hadoop-2.7.7/etc/hadoop,需要修改的有以下几个文件:
hadoop-env.sh
yarn-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
slaves
其中hadoop-env.sh和yarn-env.sh里面都要添加jdk的环境变量
(1) 修改hadoop-env.sh,添加:
export JAVA_HOME=/home/jdk1.8(自己的jdk安装路径)

(2)修改yarn-env.sh , 添加:
export JAVA_HOME=/home/jdk1.8(自己的jdk安装路径)

(3) 修改core-site.xml, 添加:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/zran/hadoopdata</value>
</property>
</configuration>
(4)修改hdfs-site.xml, 添加:
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
(5)修改mapred-site.xml
(注意要将mapred-site.xml.template重命名为 .xml的文件)
命令:
mv mred-site.xml.template mapred-site.xml
添加:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(6)修改yarn-site.xml, 添加:
<configuration>
<property>
<name>yarn.resourcemanger.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
(7)修改slaves,vi slaves ,
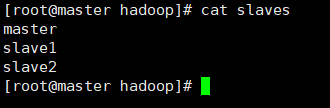
*如果有workers文件的话内容修改为:
mster
slave1
slave2
4. 复制master上的 /home/hadoop-2.7.7/ 到另外两台服务器上。
主节点上执行:(可以使用xshell或vmwaretool)
scp -r /home/hadoop-2.7.7root@slave1:/etc
scp -r /home/hadoop-2.7.7 root@slave2:/etc
5. 复制 主节点 /etc/profile 到子节点的 /etc
配置hadoop环境变量:
#配置Hadoop的安装目录
export HADOOP_HOME=/root/software/hadoop-2.7.7
#在原PATH的基础上加入Hadoop的bin和sbin目录
export PATH=
HADOOP_HOME/bin:$HADOOP_HOME/sbin
scp /etc/profile root@slave1:/etc
scp /etc/profile root@slave2:/etc
在子节点上分别执行:source /etc/profile, 使环境变量生效
6. 格式化主节点的namenode文件

successfully formatted表示格式化成功
7. 启动hadoop
#start-all.sh
主节点上jps进程如下:
NameNode
SecondaryNameNode
ResourceManager
每个子节点上的jps进程如下:
DataNode
NodeManager
如果这样表示hadoop集群配置成功
可以登录主节点的50070端口查看