原文连接The Illustrated Transformer
Google2017论文《Attention is All You Need》引入Transformer,本文将介绍Transformer的相关知识。
整体结构
首先来看一下模型的整体结构。在机器翻译应用中,Transformer的输入是一种语言的某一句话,输出是另一种语言下这句话对应的翻译。

Transformer内部由encoding和decoding两部分组成:
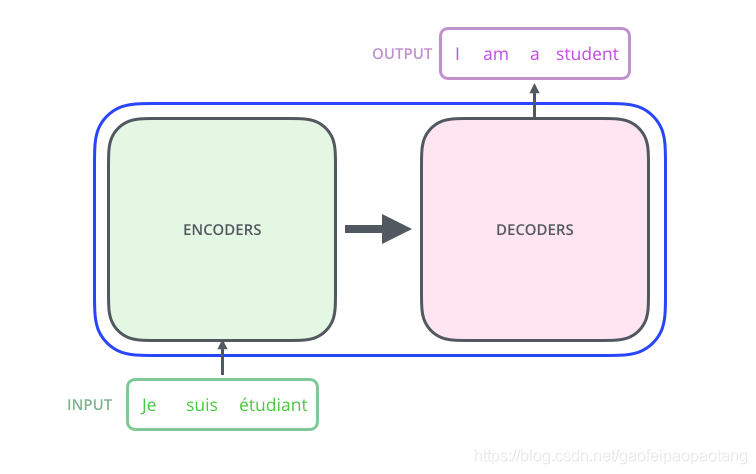
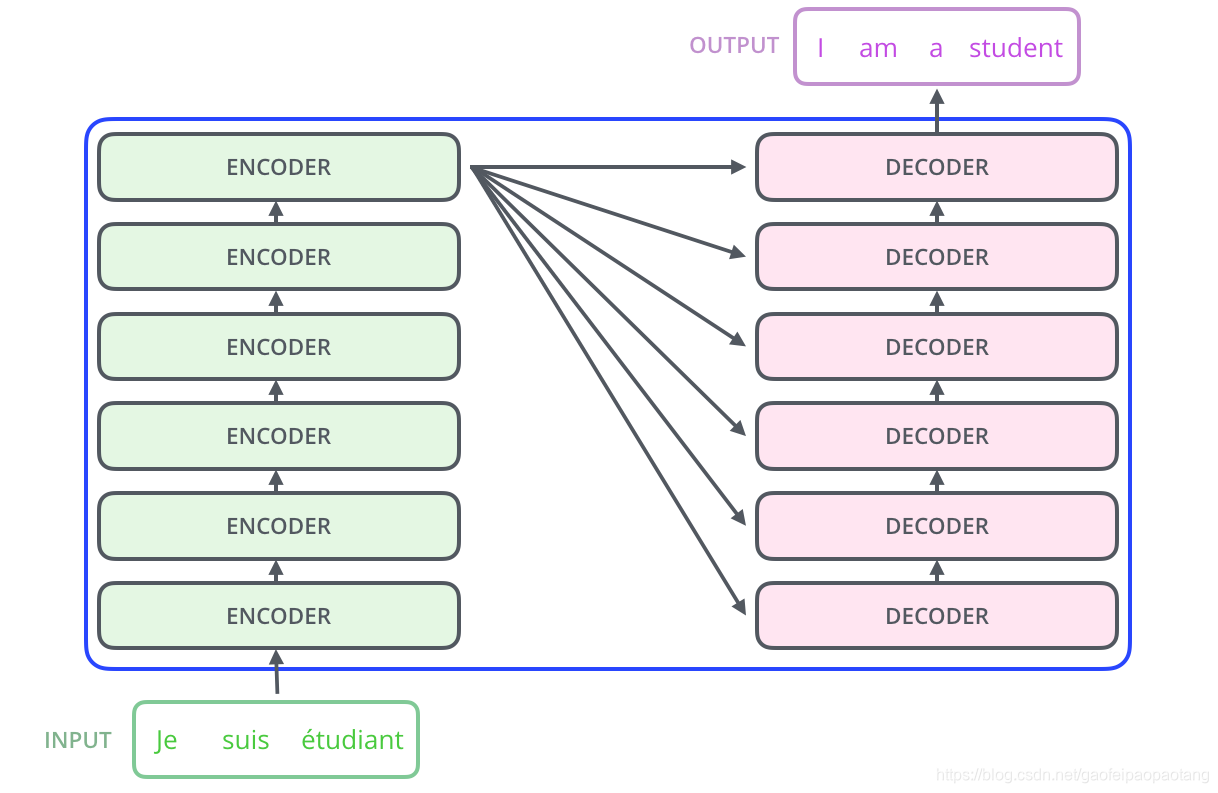
encoding部分由若干个encoder堆叠构成(论文中有6个encoder,也可以试验其他数量)。decoding部门由相同数量的decoder构成。
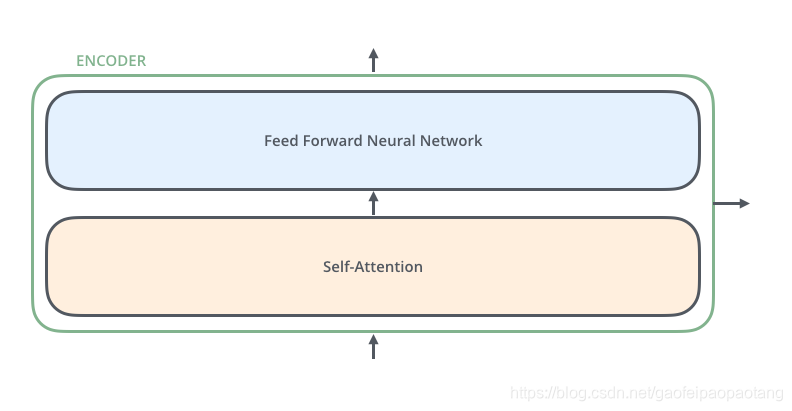
每个encoder的结构相同(但不共享参数),包含两层子网络层:自注意力层(self-attention)和前向网络层(Feed Forward).
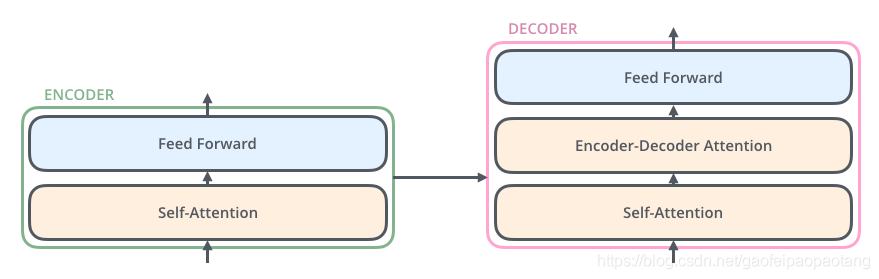
decoder结构类似于encoder,区别在与在自注意力层和前向层之间,添加了一层注意力层:

张量出场
我们已经熟悉了模型的整体结构,接下来,我们来看看各种向量/张量是如何在模型中流动(flow)的。
像所有的NLP任务一样,首先对单词做embedding:

每次输入的单词的个数属于模型的超参设置,基本设置成训练数据中最长语句的长度。
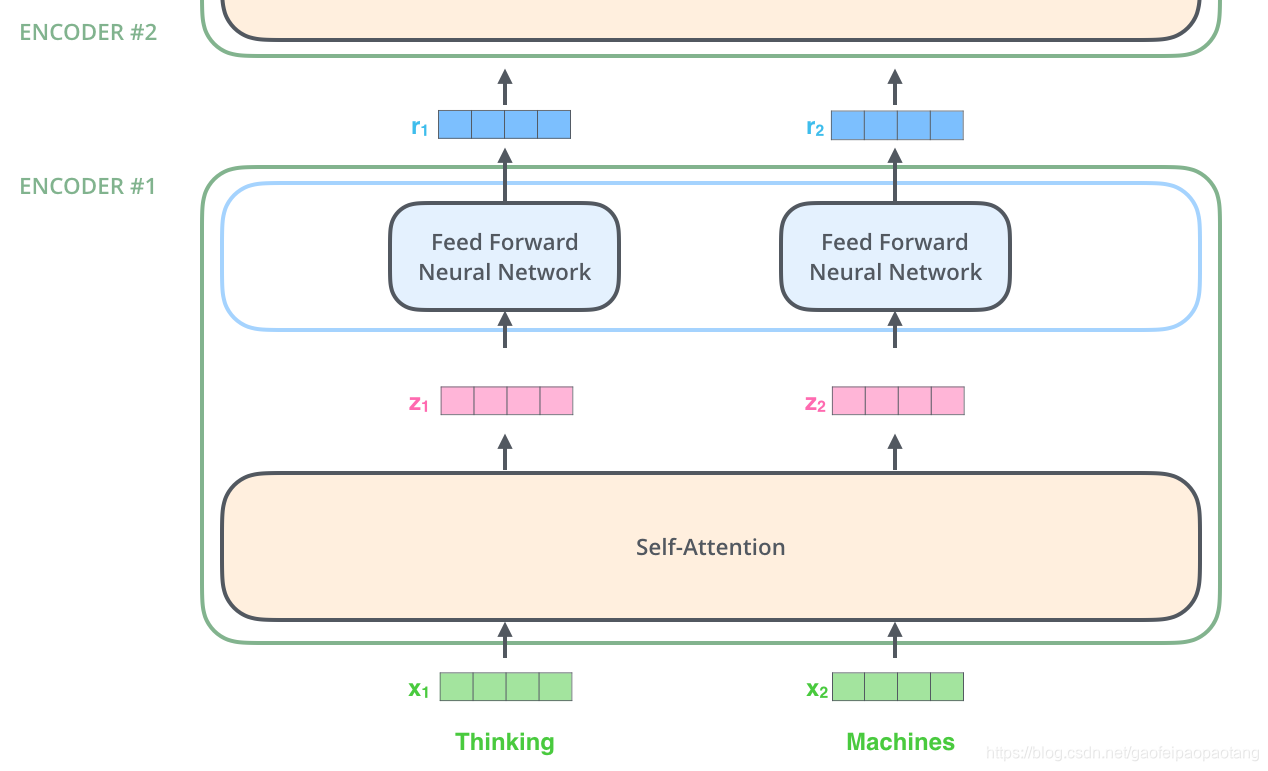
embedding之后,每个单词的embeding向量依次通过自注意力层和前向网络层:
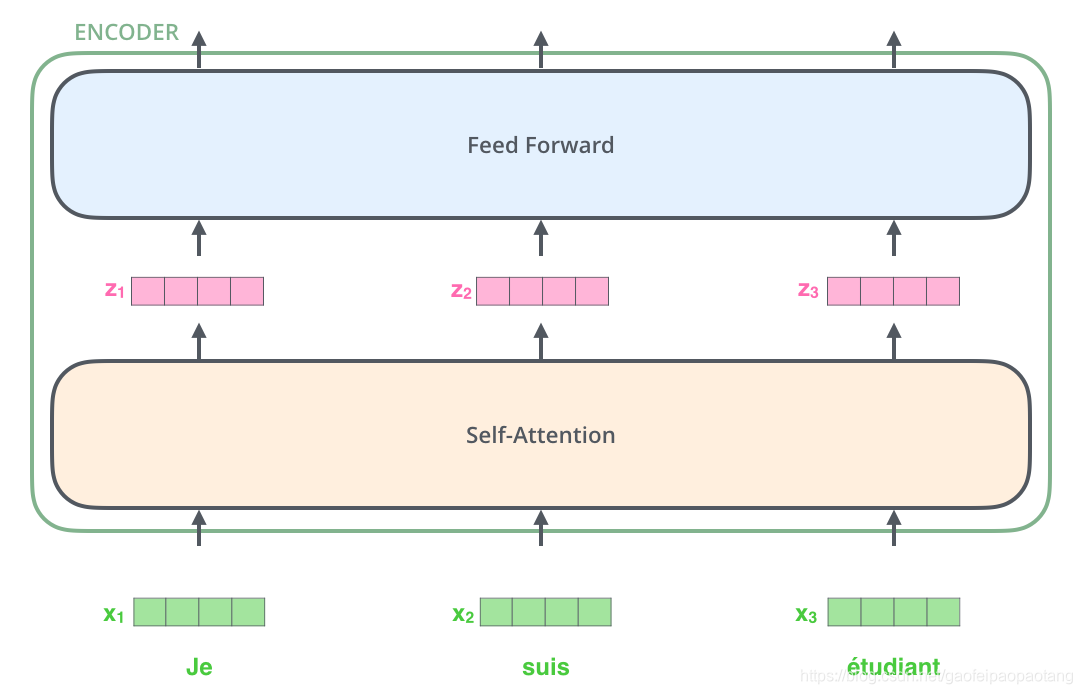
这里我们看到,每个embedding向量各自通过网络层。其实,在自注意力层,embedding层之间是有相互依赖的,但到了前向网络层,就不存在这种相互依赖了,所以可以并发运行。
Encoding整体结构
自注意力层整体结构
不要被自注意力的概念吓到。作者在阅读《Attention is All You Need》之前,也没接触过这个概念。我们来看一下它的原理。
比如我们需要翻译下面这句话:
“The animal didn’t cross the street because it was too tired”
其中的代词"it"指代什么呢? 是"animal"还是"street"?对人类来说很简单的一个问题,但是对算法来说就不简单了。
模型在处理"it"的时候,自注意力层允许将"it"与"animal"关联起来。
简单来说,就是在模型处理每个单词的时候,为了更好的理解和编码当前的单词,自注意力允许当前单词查看所有其他位置的单词。
如果你熟悉循环网络,应该记得循环网络是通过网络状态值达到同样目的的。

自注意力细节
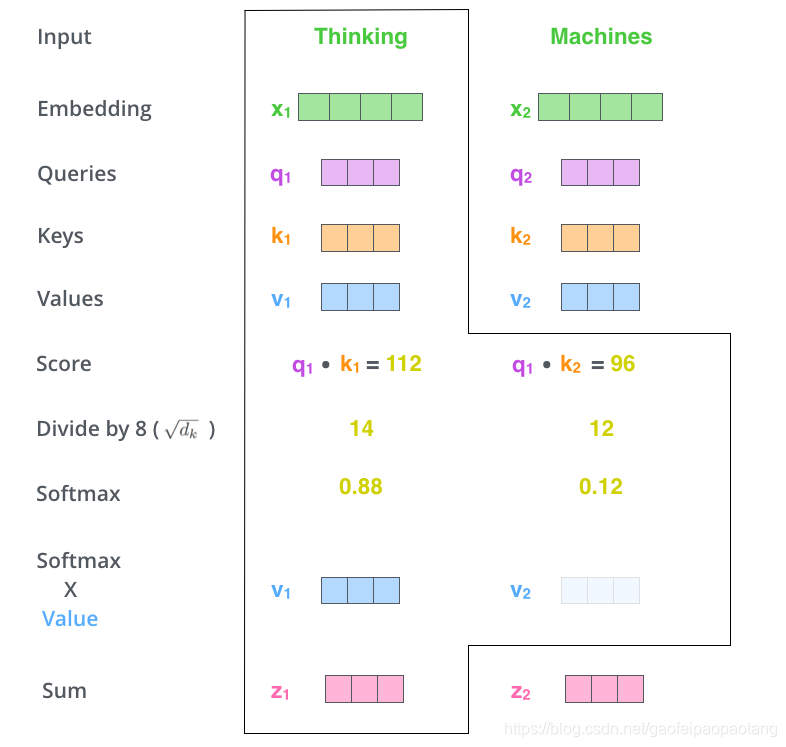
我们来看一下如何计算自注意力值。
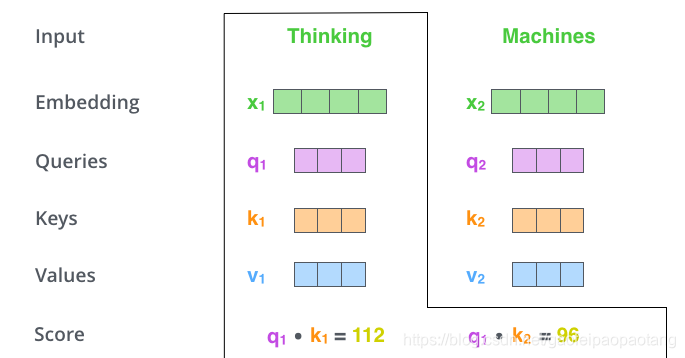
首先,引入三个矩阵 ,作为网络的可训练参数。每个单词的embedding向量与三个矩阵分别点乘,得到三个向量 ,如下:

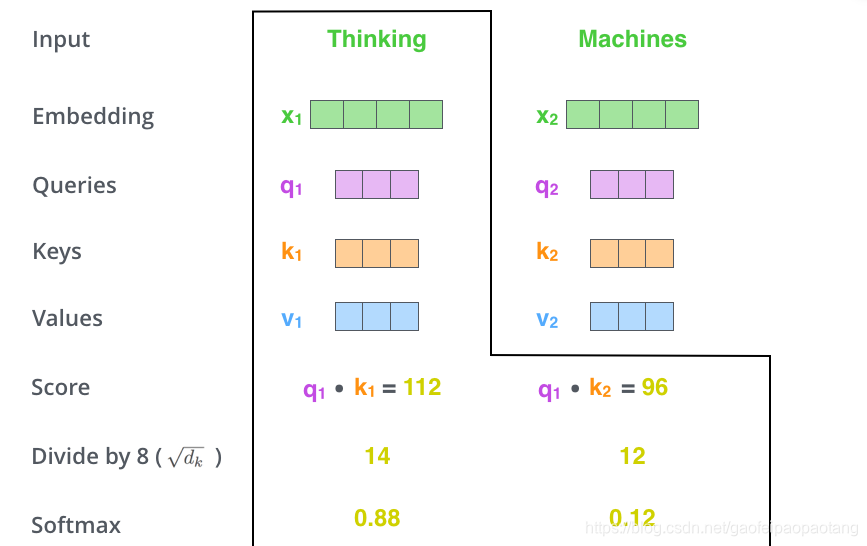
第二步,计算权重Score值:
第三、四步将score值除以8(key向量长度的平方根,这样可以使梯度更稳定),并通过softmax做归一化。
第五步,归一化之后的socre与向量 相乘
第六步,对第五步的结果求和,等到当前单词对所有其他单词的Attention值
自注意力的举证形式计算
第一步:

第二步:
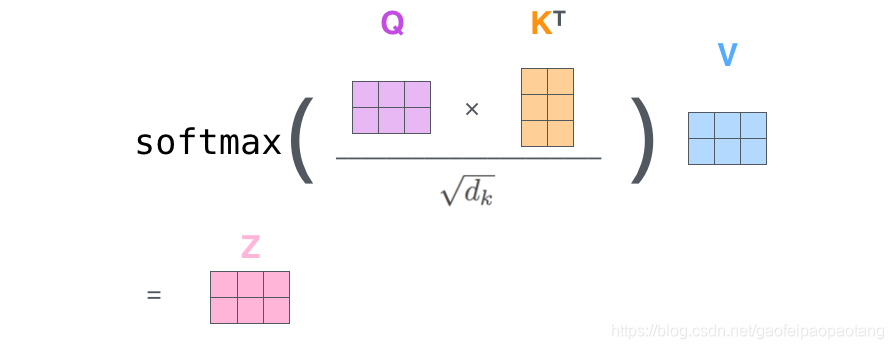
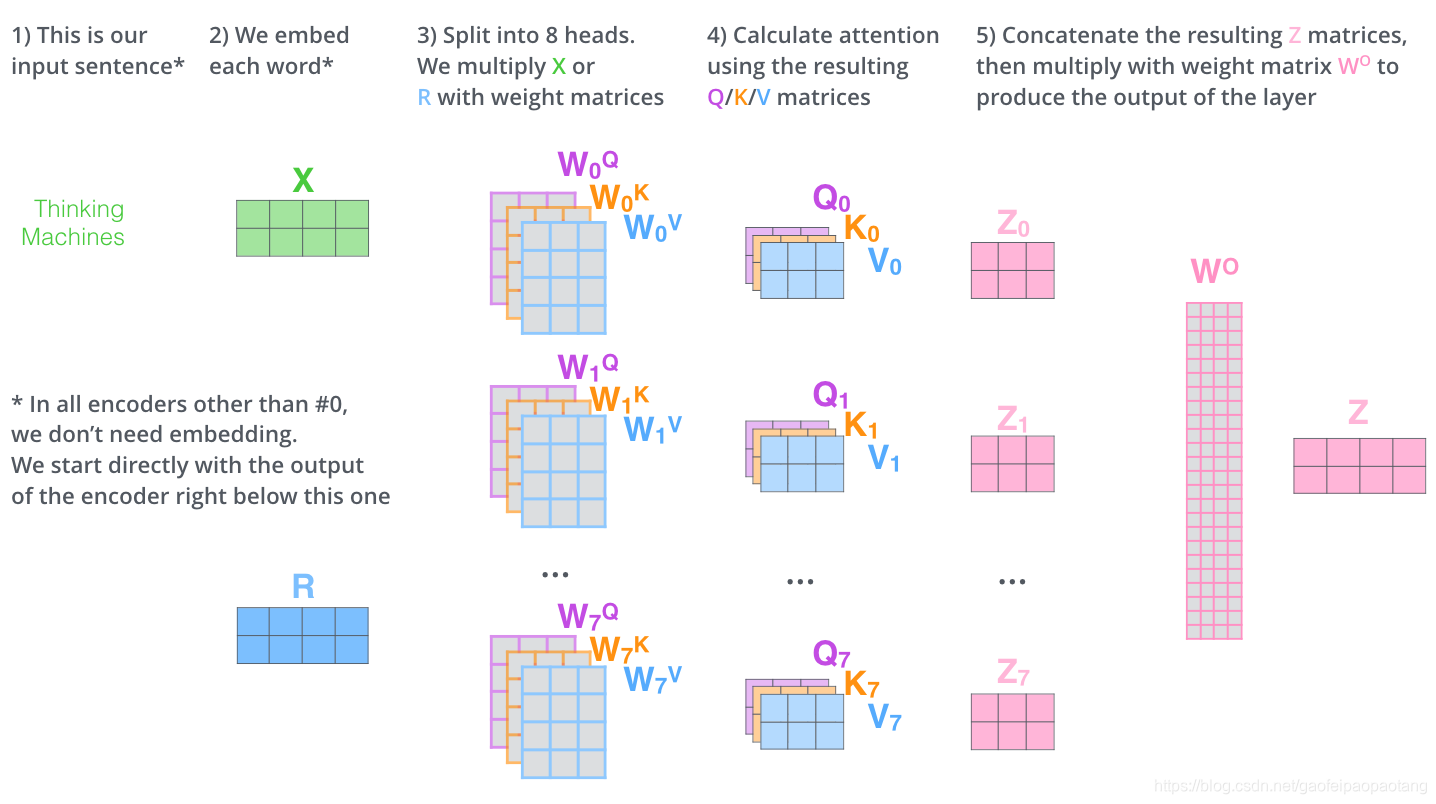
Multi-Heads Attention
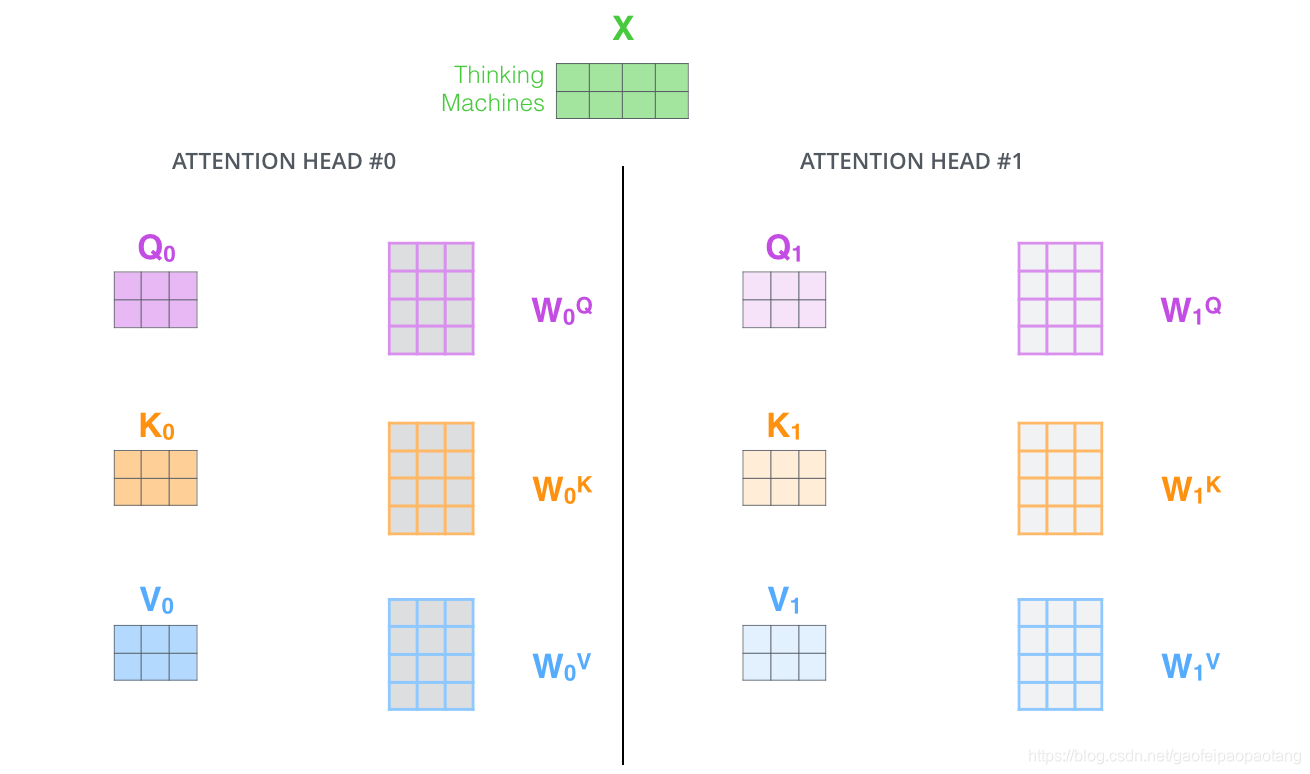
论文中引入了"multi-headed"注意力的概念,从两个方面改进了注意力层的性能:
- 扩展模型注意多个位置的能力。
- 注意力层获得多个注意力表达空间。
以2-headed注意力为例:
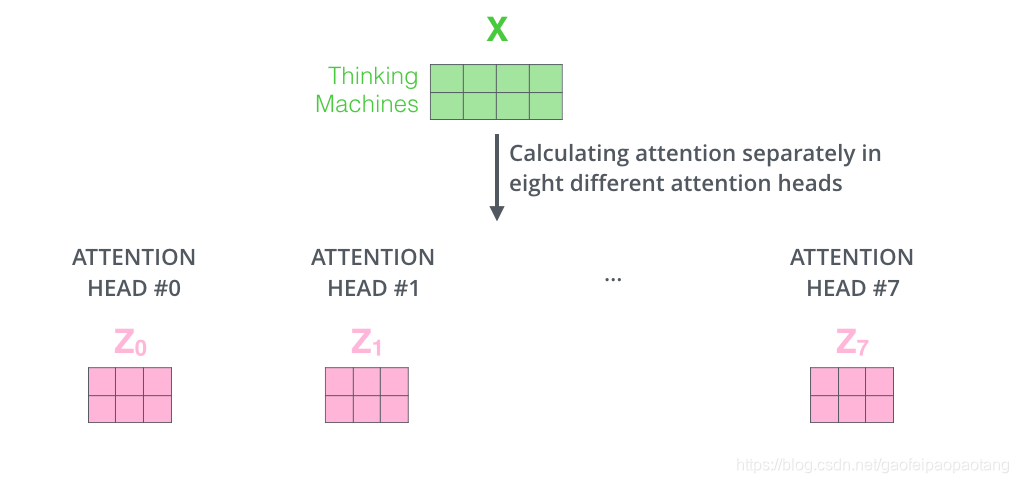
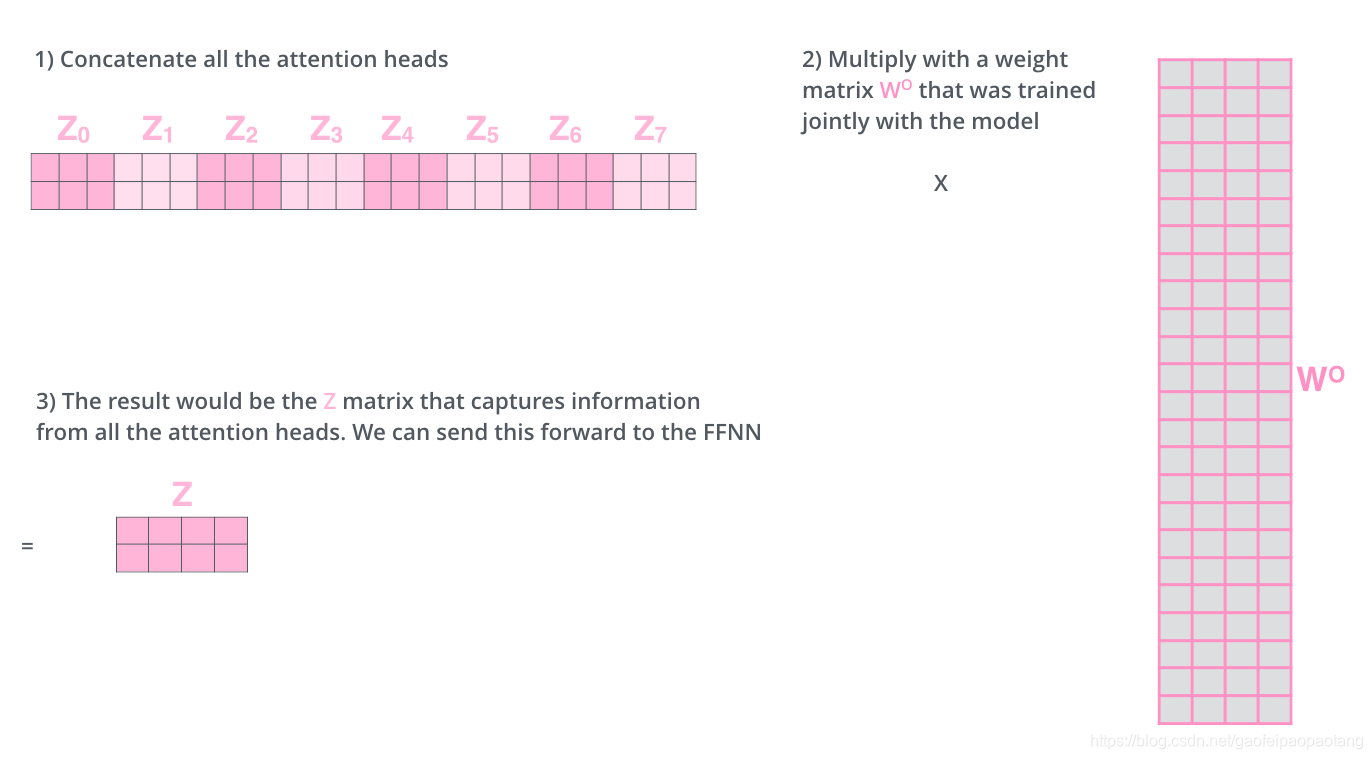
我们将以上的不走组合到一起,得到完成的过程如下:
回到上文翻译的例子中,我们看看"it"的注意力是怎么分配的
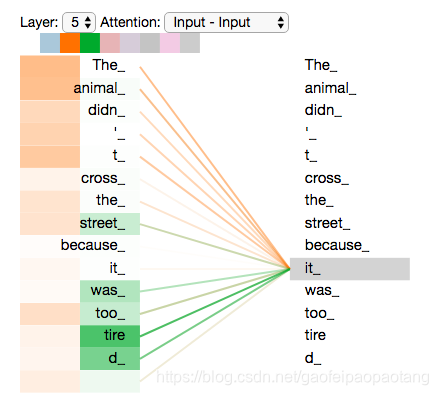
可以看到"it"一个注意力模型注意到了"the animal",另一个注意力模型注意到了"tired".
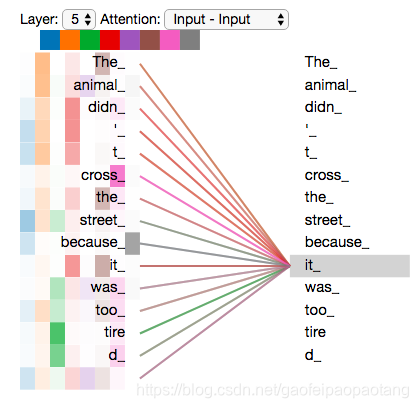
如果在增加head,结果变得不太好直观解释了:
用位置编码表示序列的顺序
目前为止模型并没有考虑到句子中单词的顺序。
为了解决这个问题,transformer为每个embedding向量添加一个单独的向量。这些向量符合某种模式,可以帮助模型定位单词的位置以及相互间的距离。
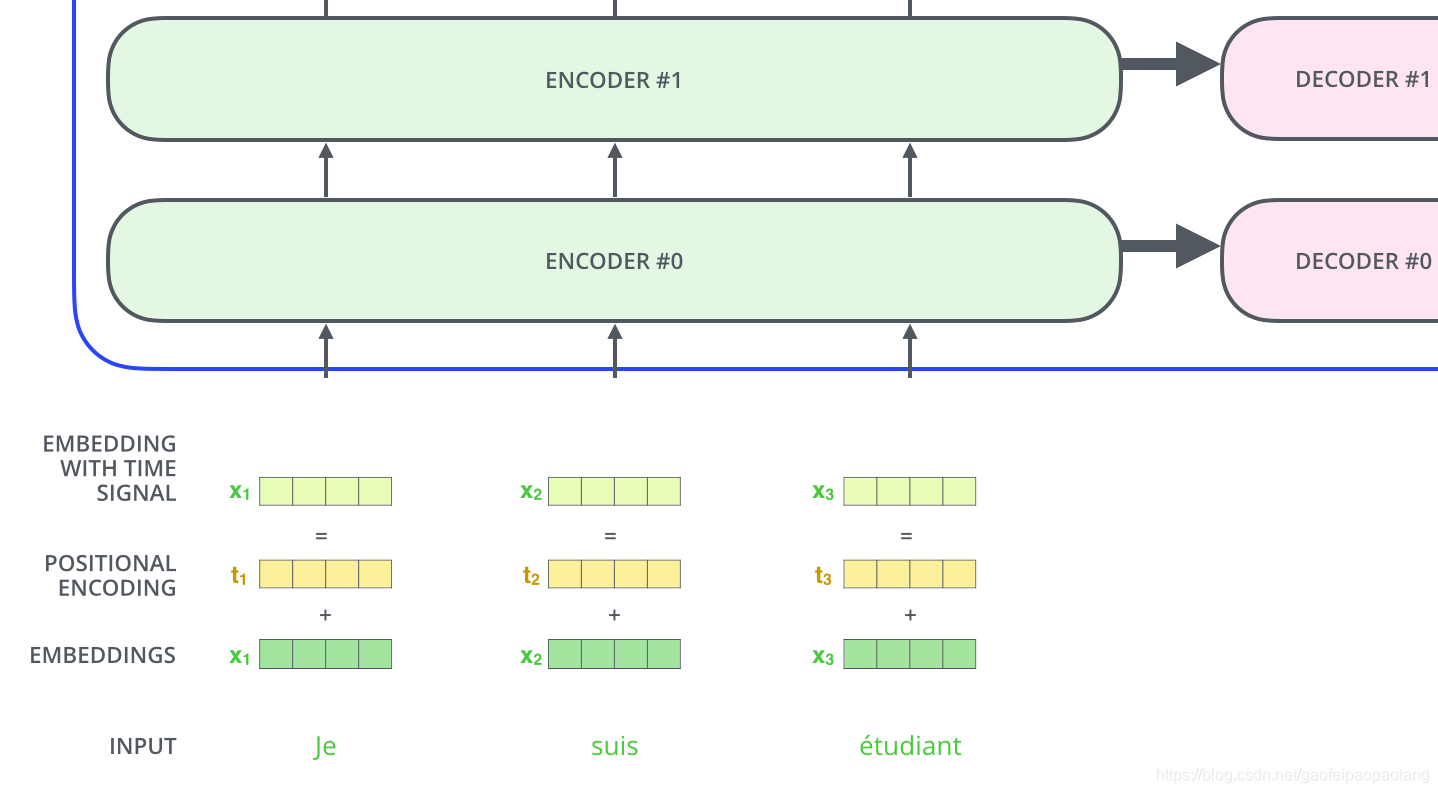
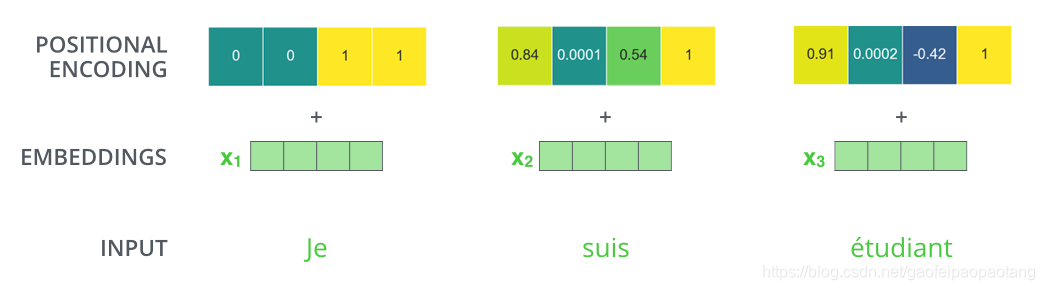
比如我们embedding纬度为4,则实际上的位置编码可能如下:
残差网络
encoder的另一个细节还没有讨论,那就是残差层和Normalize层,如下:
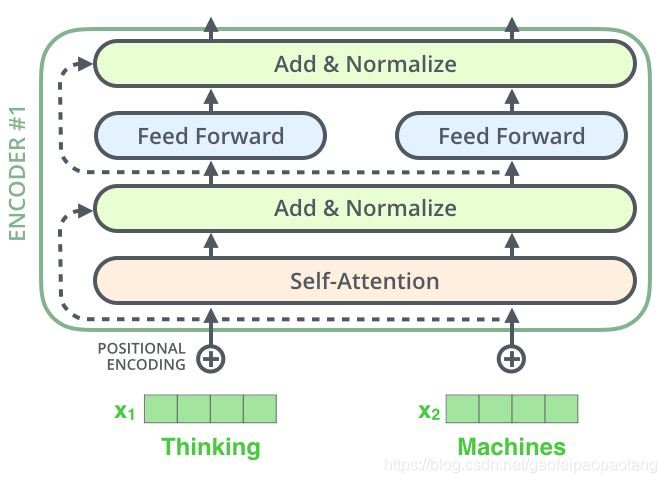
更加具体的细节如下:

放到整体结构图上,结构如下:

解码侧结构
目前为止encoder侧的概念已经介绍完成,我们已经知道encoder内部每种网络层的工作原理。我们将编码和解码结合到一起看一下整体的工作流程:
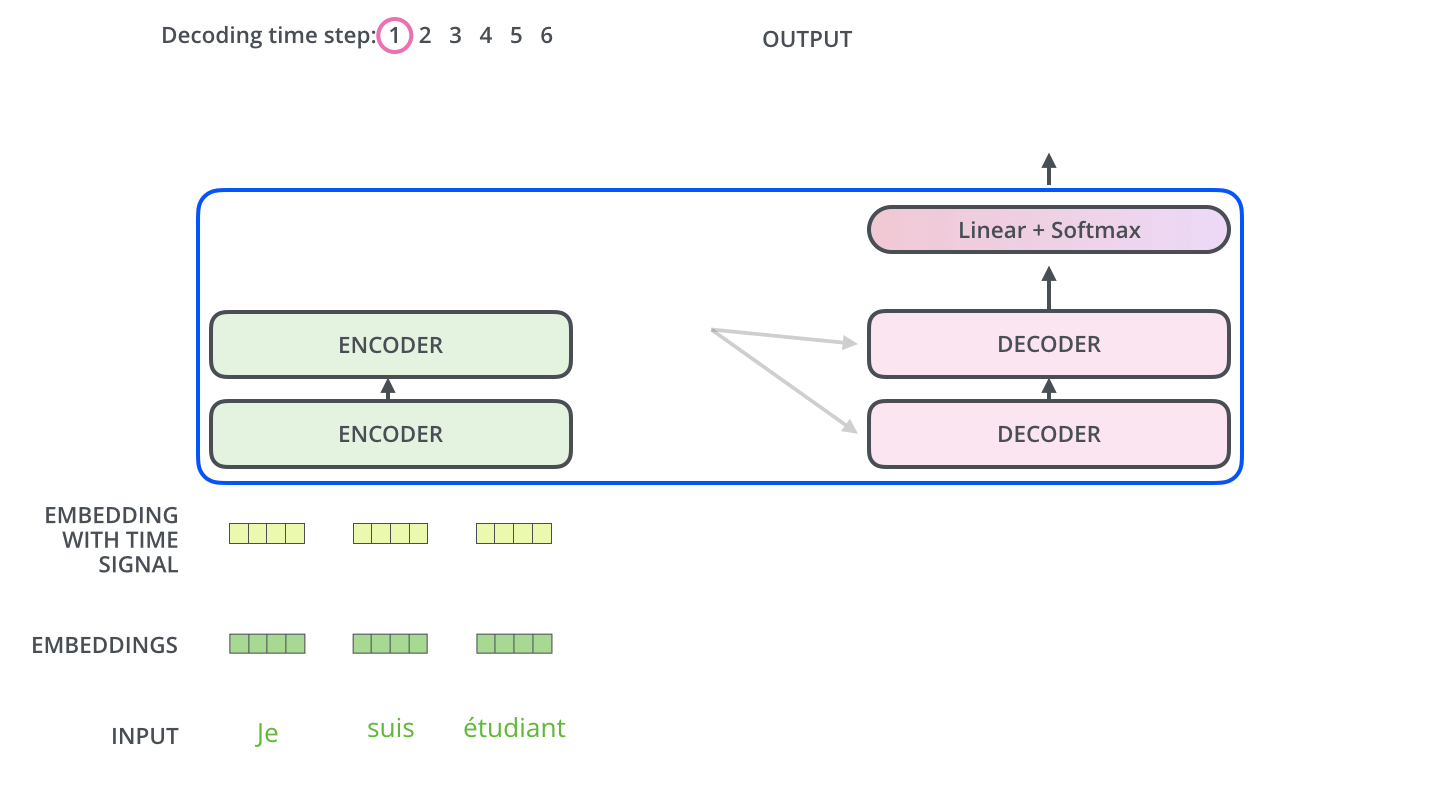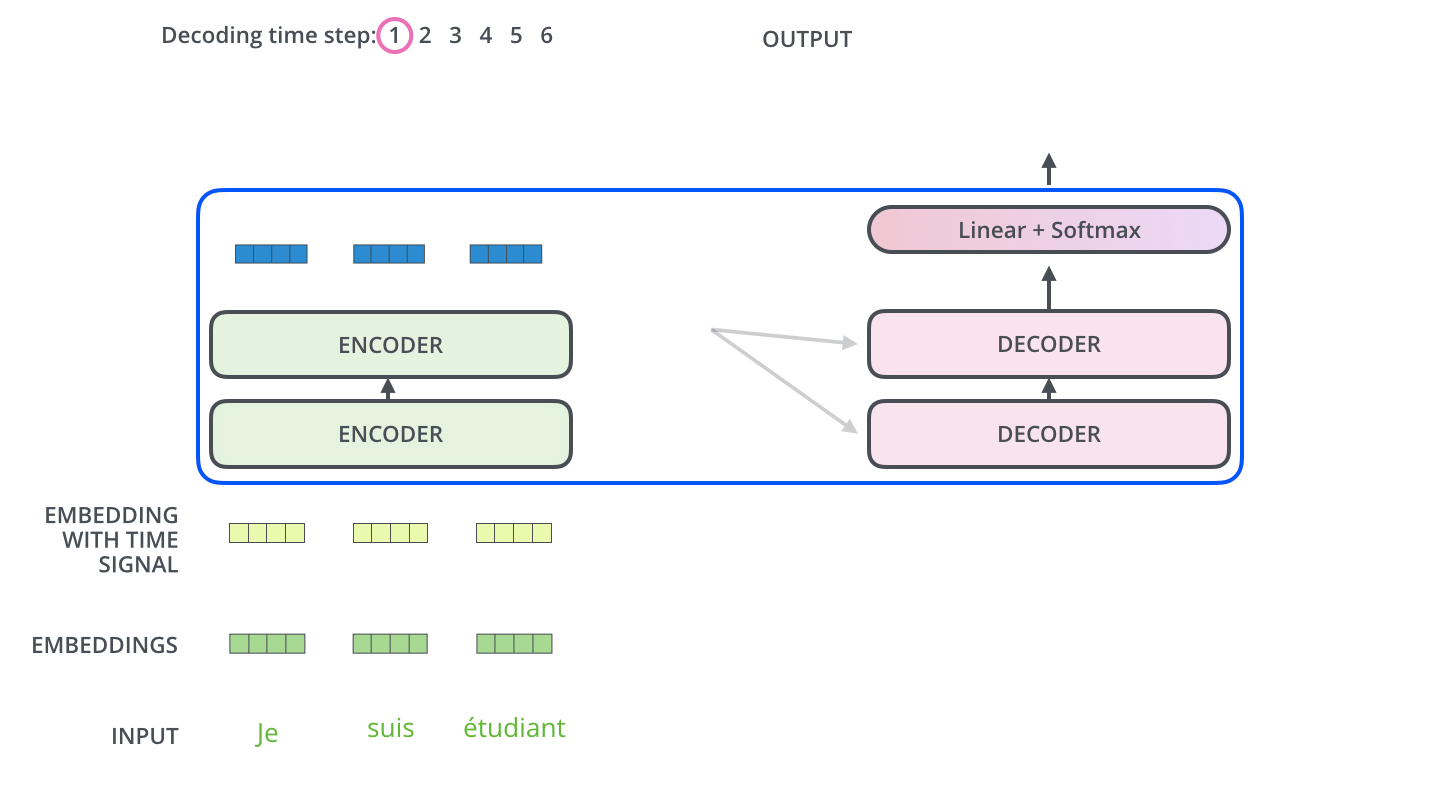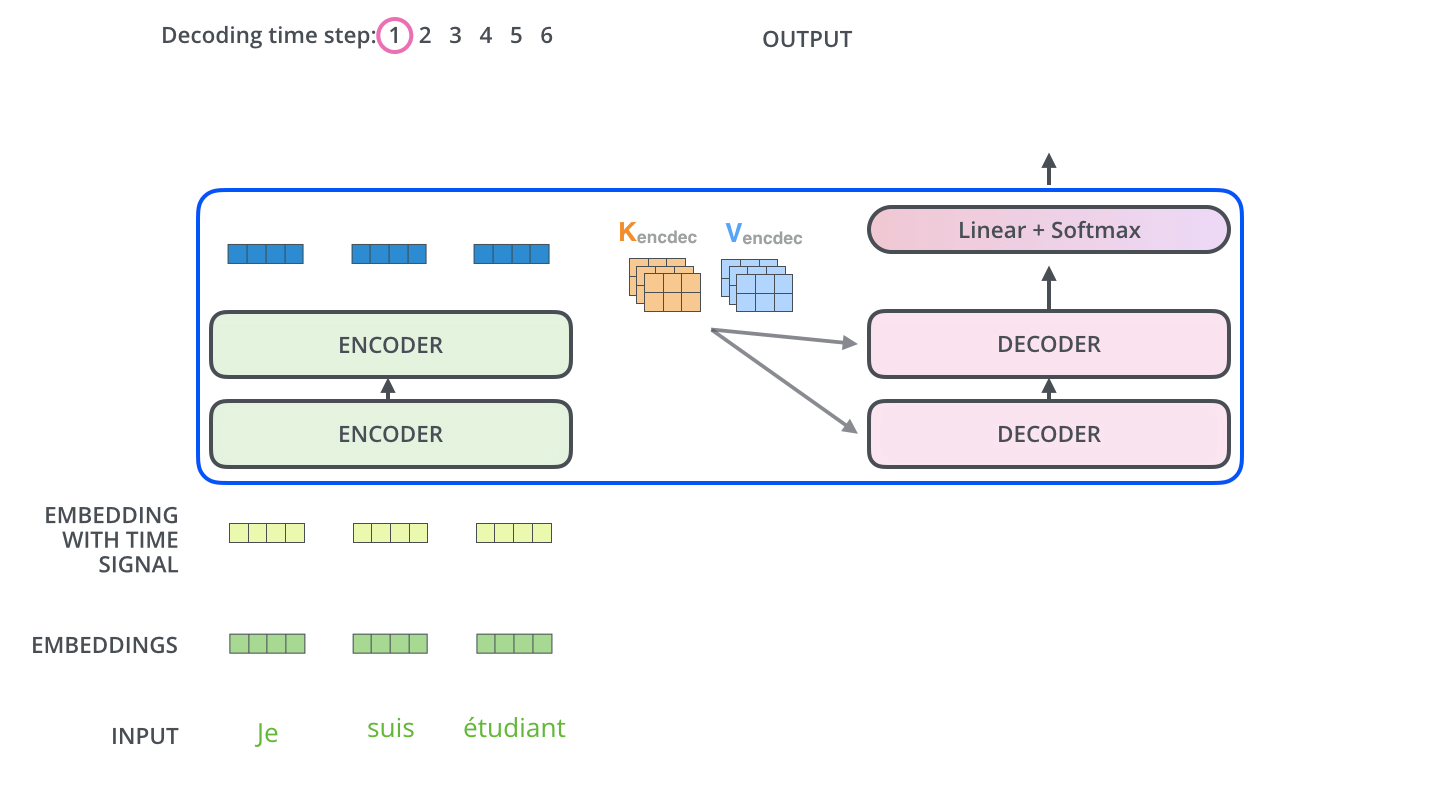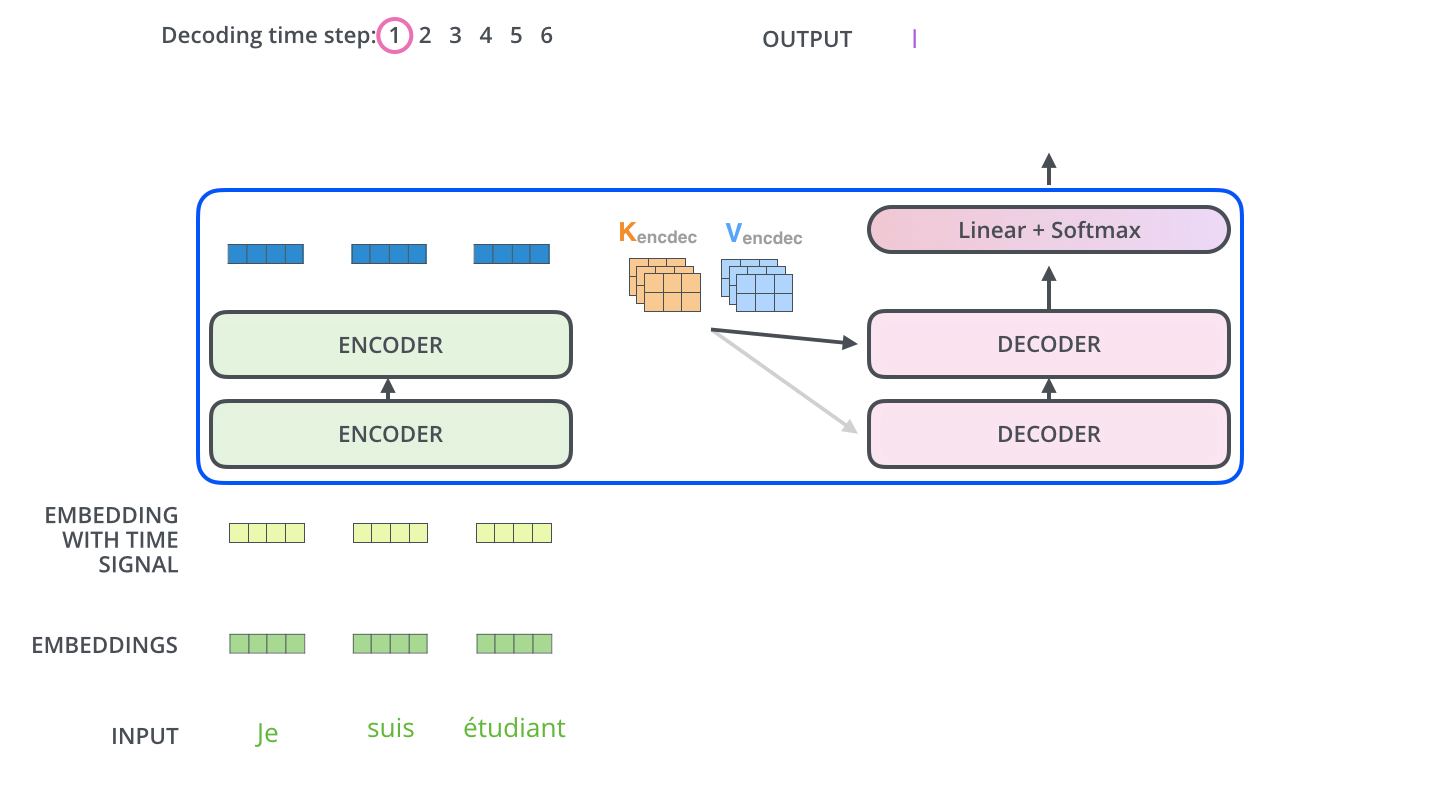
模型每次输出一个单词,直到输出终止符为止。
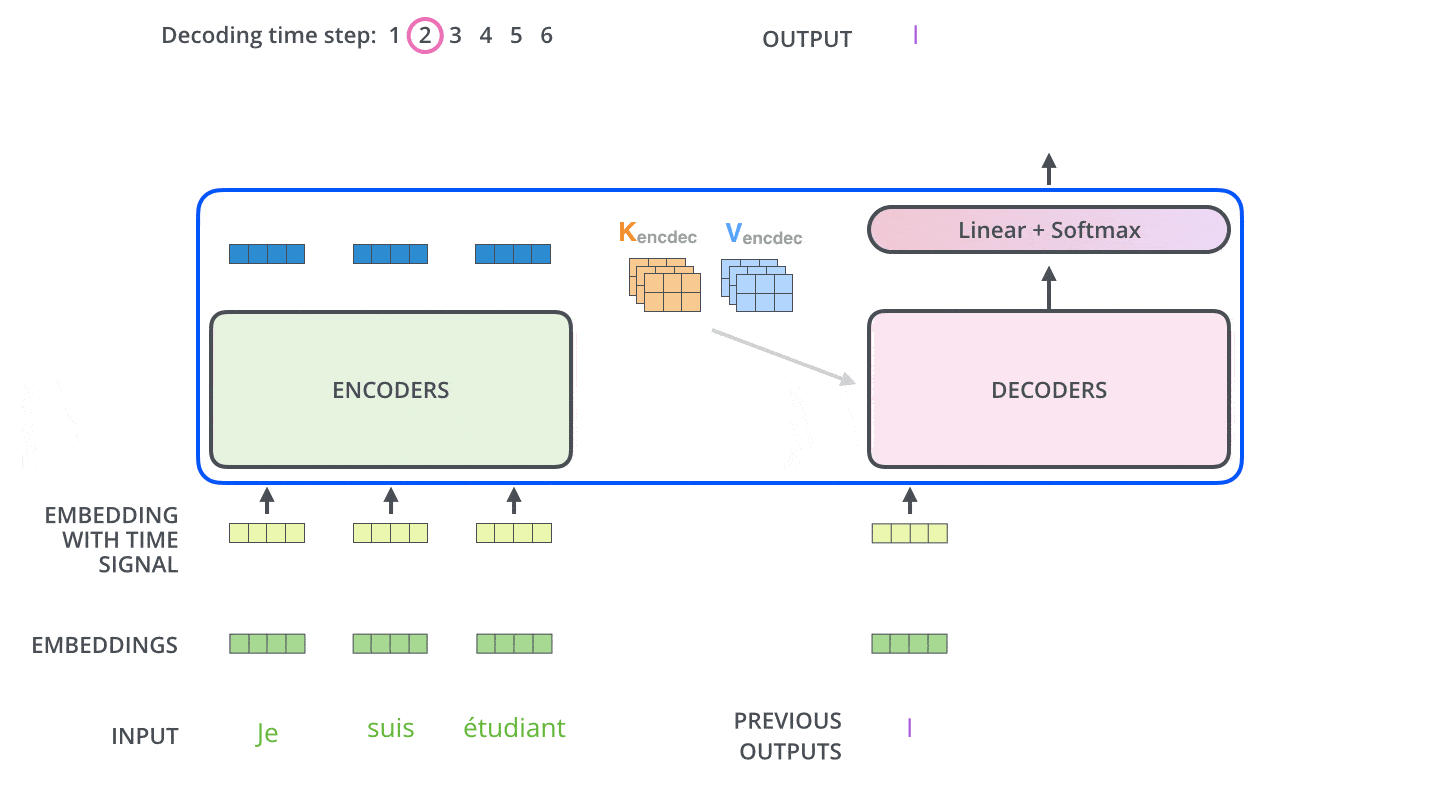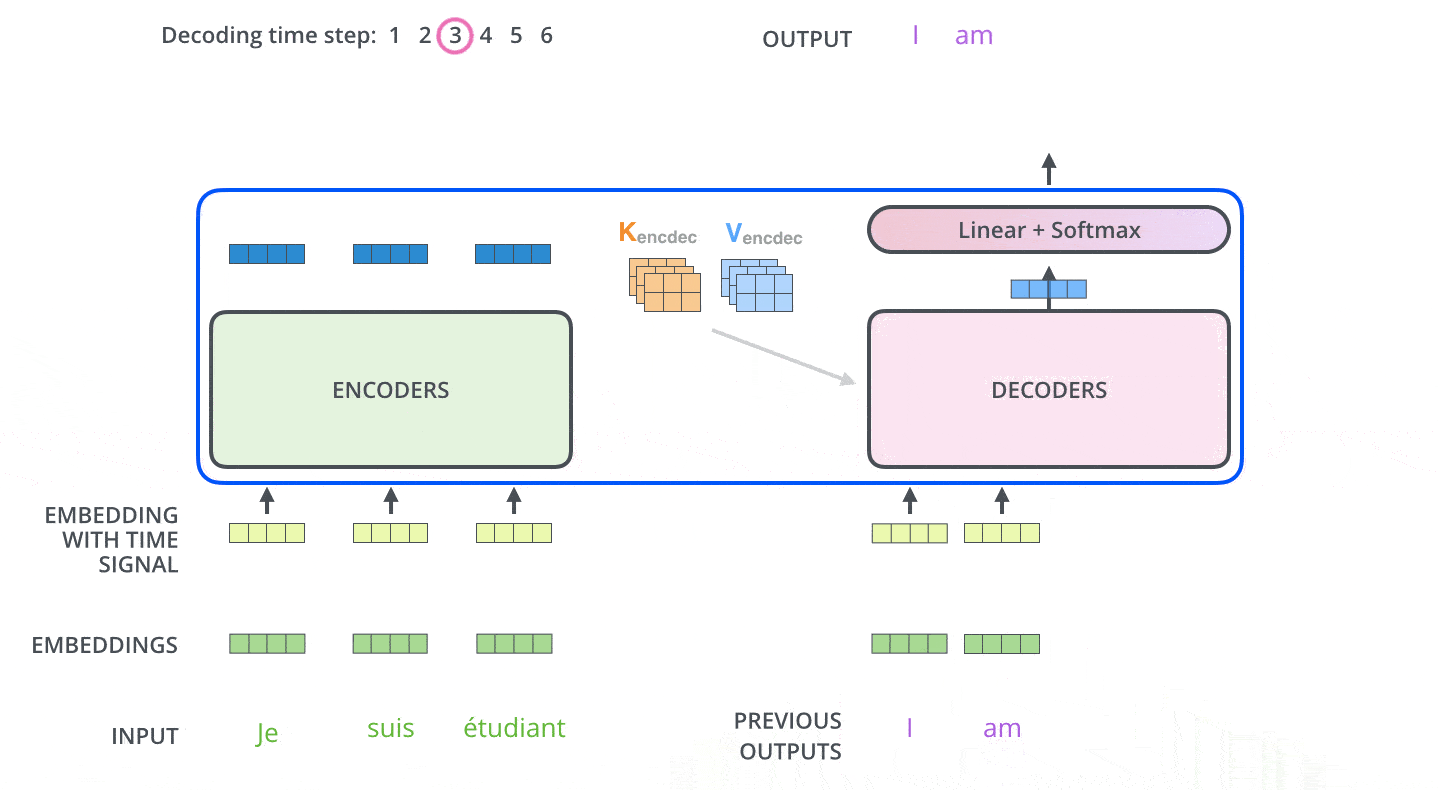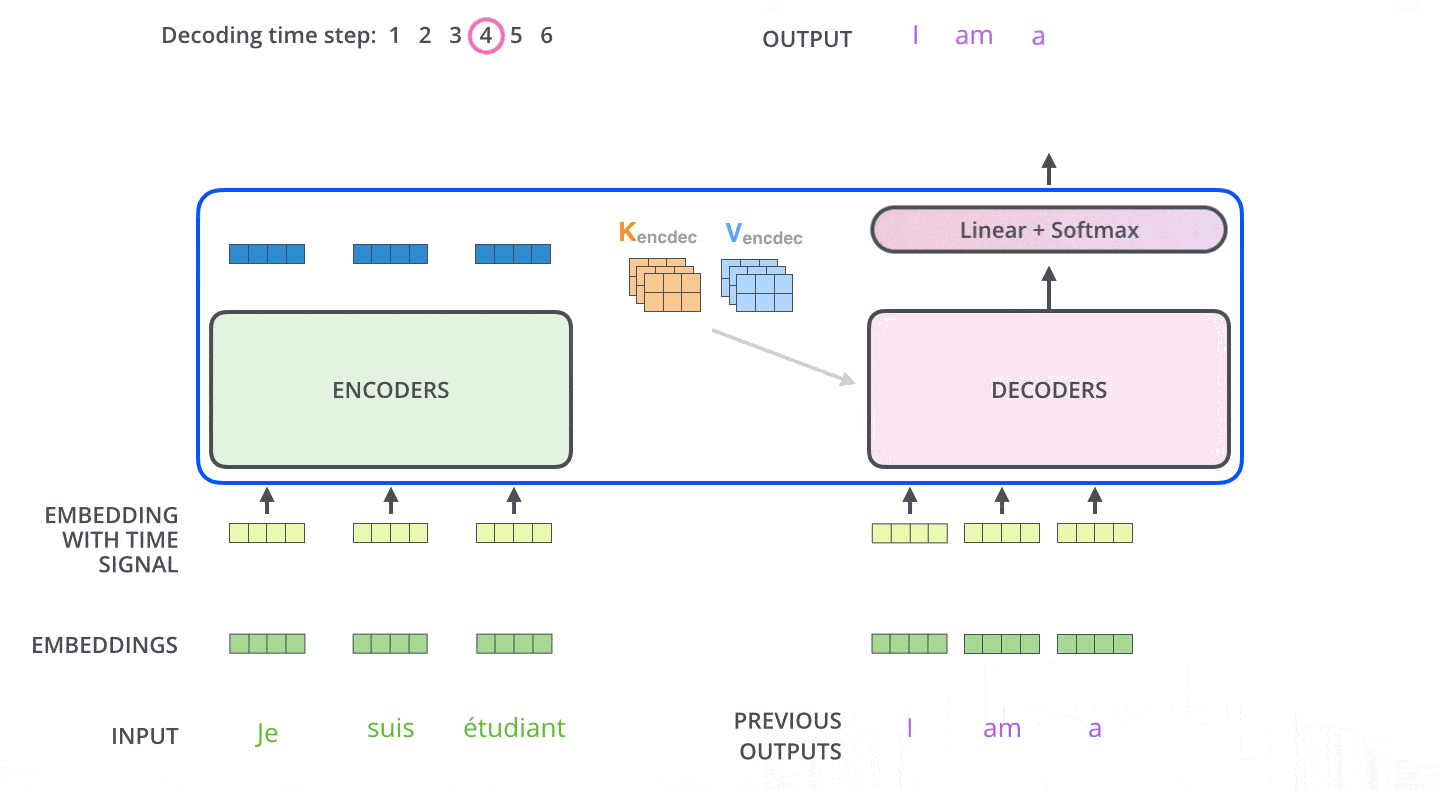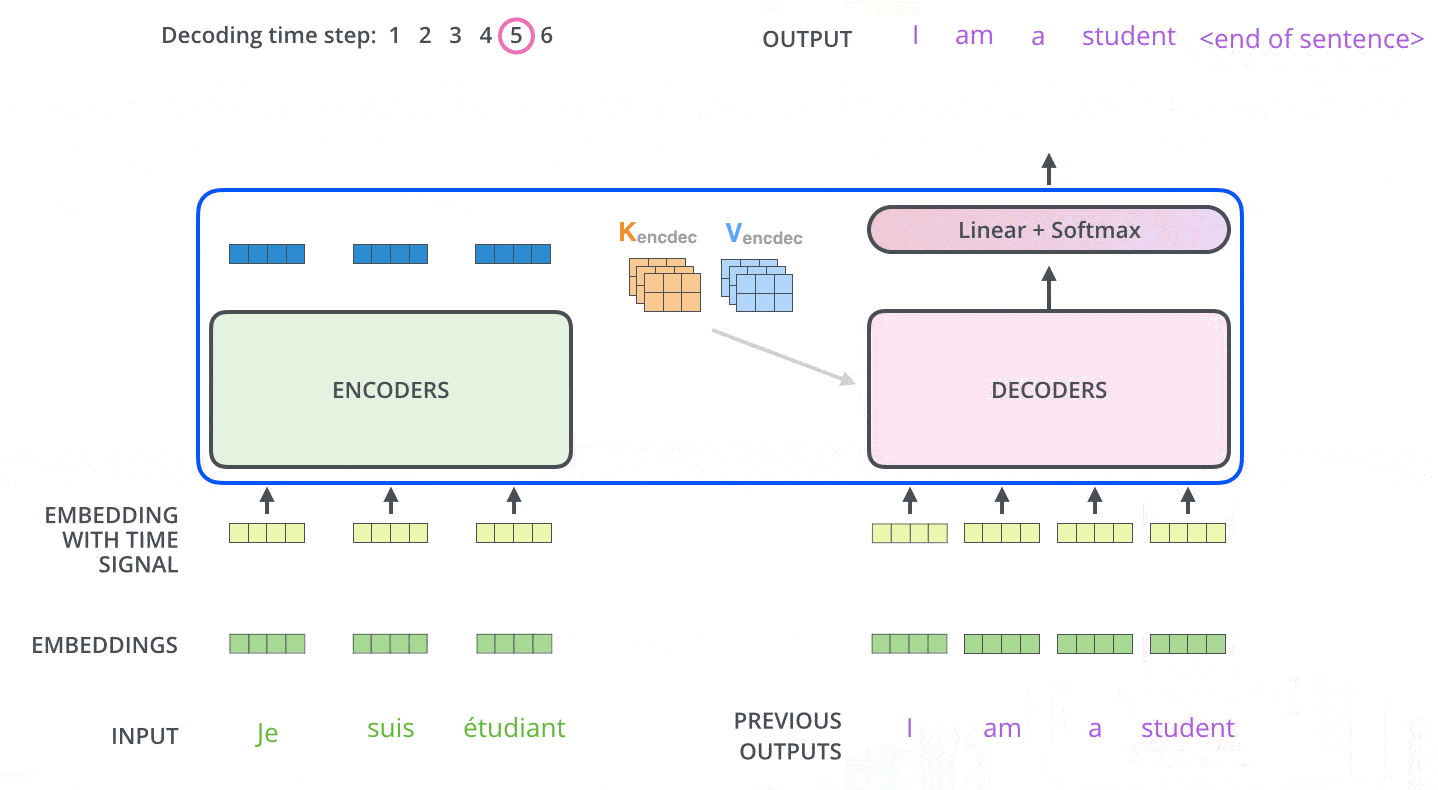
decoder中的自注意力层与encoder中的略有不同,只关注输出语句中前置位置的单词,而不会关注后置位置的单词。
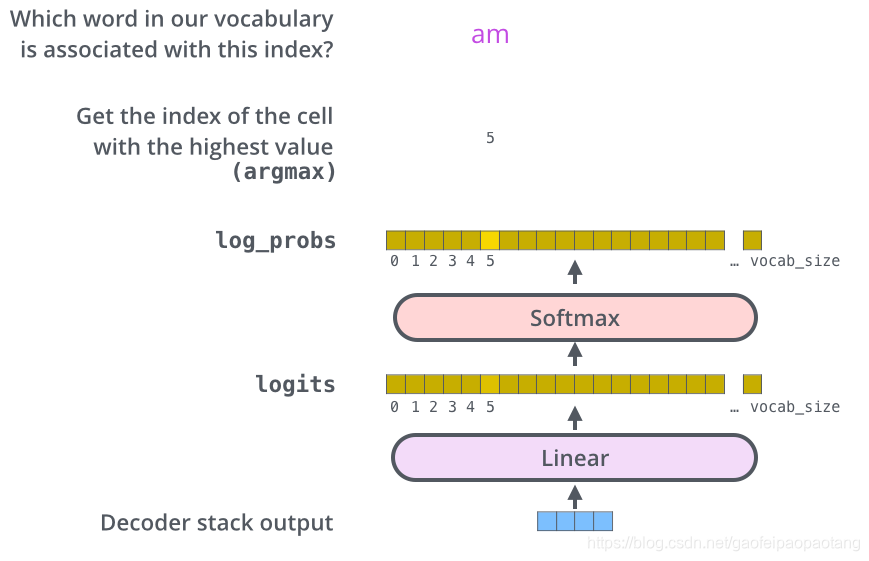
Liner和Softmax层
decoder最终输出的是一个float向量,如何转换成一个单词呢?者就是最后的Liner层和紧随其后的Softmax层的工作。
假设模型的输出语言为英语,并且英语的词汇量为10000,则liner层的输出为长度为10000向量,其中每个元素为每个单词的得分。
经过softmax层归一化后,得出每个单词的概率。
训练过程
以上我们基本了解了预测的过程,接下来我们看一下训练的过程。
首先假设我们的输出词汇量只有6个(“a”, “am”, “i”, “thanks”, “student”, and “” (表示语句结束))。
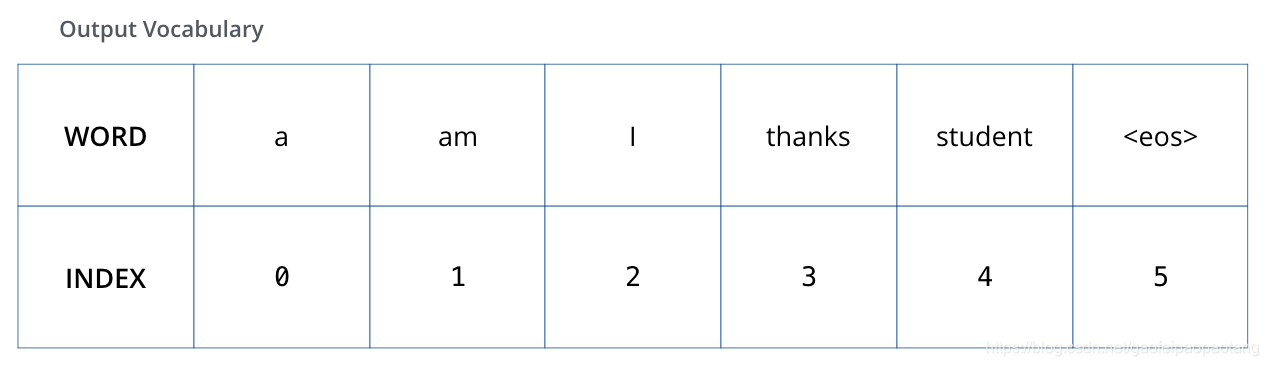
之后,可能对每个输出单词进行one-hot编码,比如"am"的编码为:
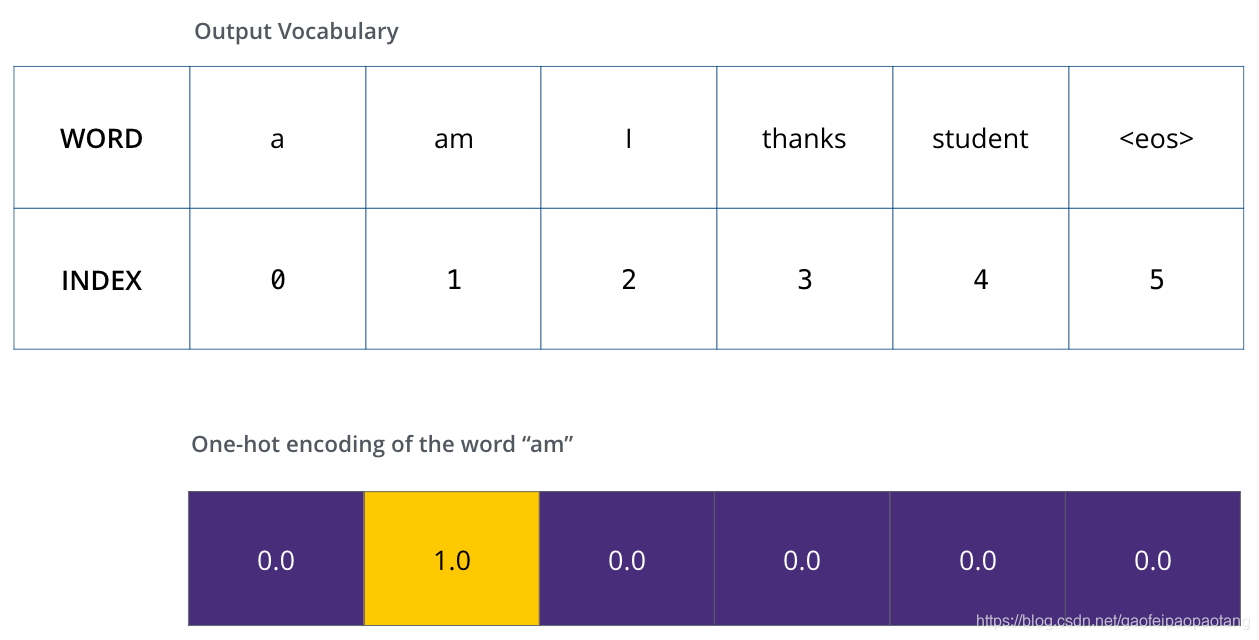
有了这些准备之后,可以讨论损失函数了。
损失函数
例如我们想训练模型,将"merci"翻译为"thanks".下图上半部分表示未训练的模型的输出,下半部分表示期望的输出。
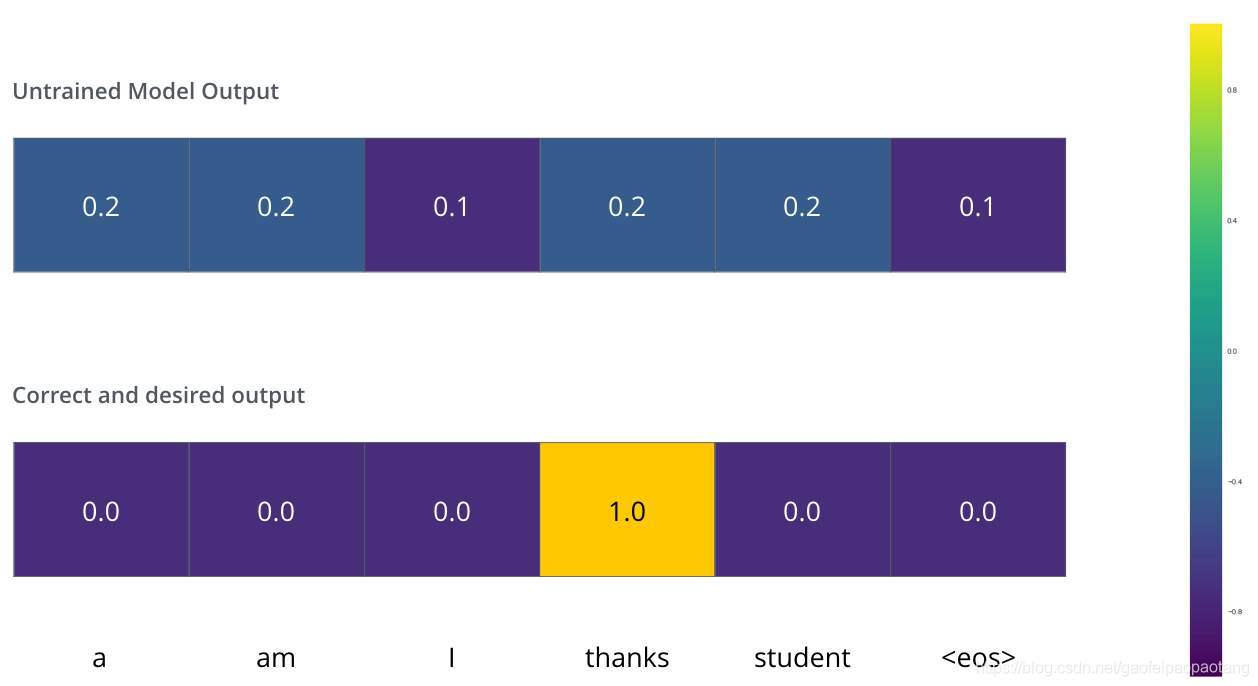
损失函数则是关于实际输出和期望输出的函数,表示两者间的差异。
类似的,对于整个句子的翻译,期望的输出为"i am a student":
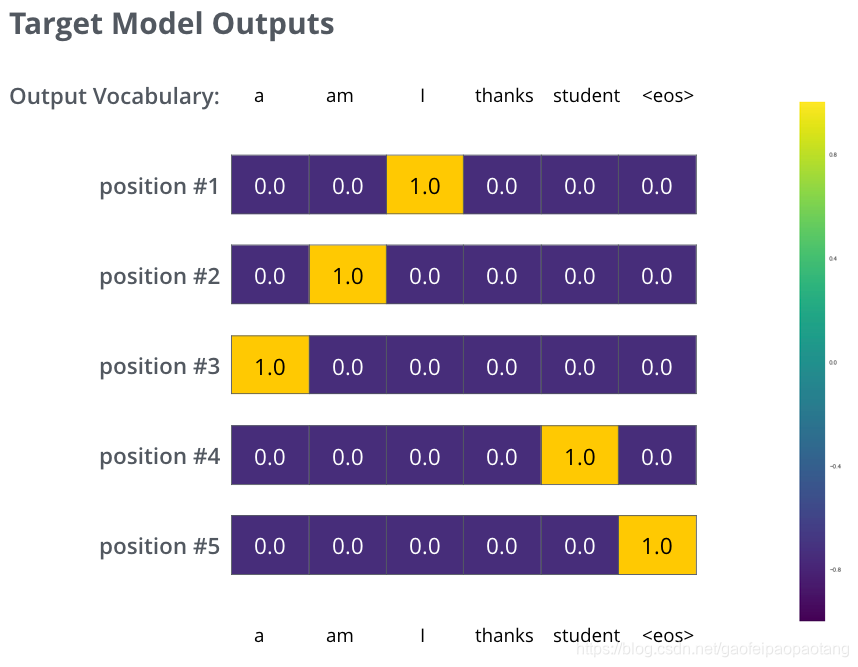
经过在大量数据集上的充分的训练之后,我们期望实际的输出类似与下图:
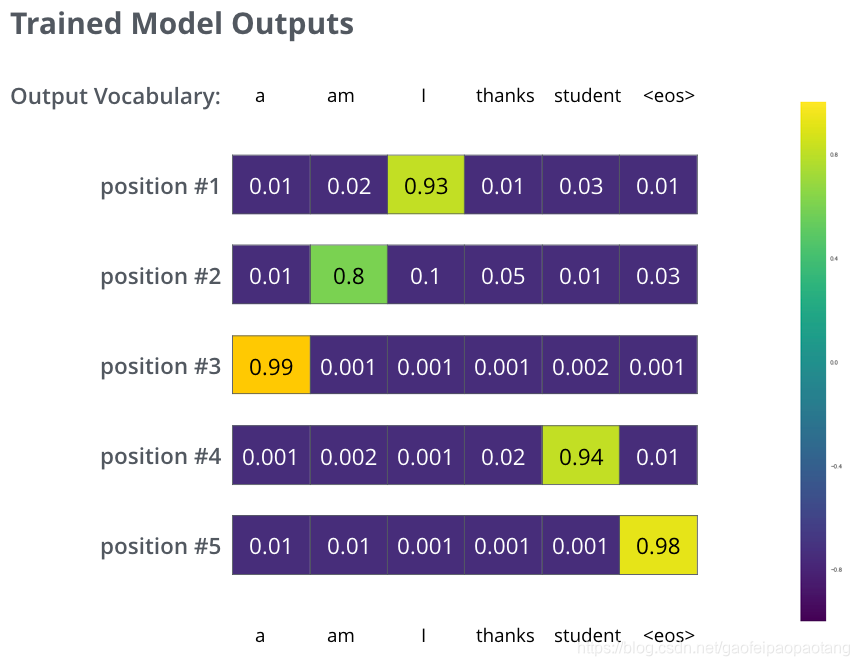
因为我们的模型是一次输出一个单词,在上述情况下,训练过程可以有多种选择。比如最简单的,每输出一个单词,我们选择概率最高的输出,并依此计算损失值进行训练,这是一种贪婪的训练算法。
其实还有其他训练方法,比如我们还可以选择Top N个概率最高的单词,比如前Top 2个。接下来运行模型2次,一次假设前一个单词是概率Top 1的单词,一次假设前一个单词是概率Top 2的单词,考虑两个的总误差选择误差较低的保留。如此类似,进行接下来的训练。其中N为模型的超参,可以通过多次实验来选择合适的值。
