transformer模型是当前大红大热的语言模型,今天要讲解的是transformer中的positional encoding(位置编码).
我们知道,transformer模型的attention机制并没有包含位置信息,即一句话中词语在不同的位置时在transformer中是没有区别的,这当然是不符合实际的。因此,在transformer中引入位置信息相比CNN, RNN等模型有更加重要的作用。
作者添加位置编码的方法是:构造一个跟输入embedding维度一样的矩阵,然后跟输入embedding相加得到multi-head attention 的输入。
在paper中,作者使用的positional encoding如下:
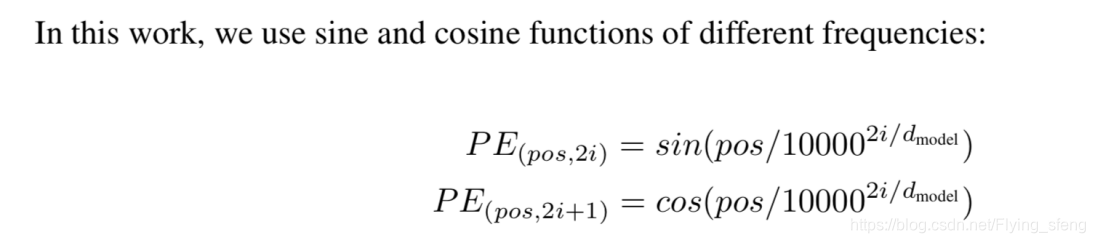
其中,PE为二维矩阵,大小跟输入embedding的维度一样,行表示词语,列表示词向量;pos 表示词语在句子中的位置;
表示词向量的维度;i表示词向量的位置。因此,上述公式表示在每个词语的词向量的偶数位置添加sin变量,奇数位置添加cos变量,以此来填满整个PE矩阵,然后加到input embedding中去,这样便完成位置编码的引入了。
使用sin编码和cos编码的原因是可以得到词语之间的相对位置,因为:
即由
可以得到,通过线性变换获取后续词语相对当前词语的位置关系。
positional encoding 的源代码如下:
class PositionalEncoding(nn.Module):
"Implement the PE function."
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) *
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + Variable(self.pe[:, :x.size(1)],
requires_grad=False)
return self.dropout(x)
其中,div_term是上述公式经过简单的数学变换得到的,具体如下:
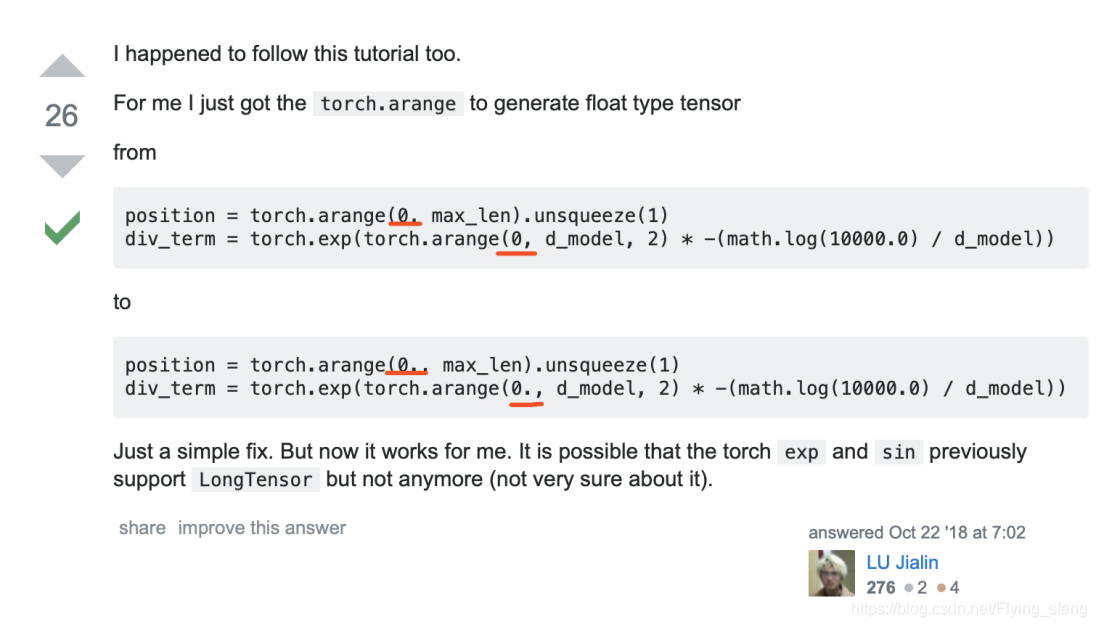
我在执行过程中,出现了如下错误:
RuntimeError: “exp” not implemented for ‘torch.LongTensor’
估计原因是pytorch的版本问题,解决方法为将torch.arange(0, d_model, 2)中的整型改为浮点型,即torch.arange(0.0, d_model, 2)
参考:
attention is all you need
自然语言处理N天-使用Pytorch实现Transformer第一节
RuntimeError: “exp” not implemented for ‘torch.LongTensor’