map,.unordered_map, hash_map的比较https://blog.csdn.net/u014209688/article/details/95366594
1.unordered_map的存储结构
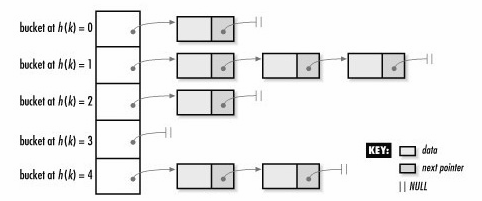
hashtable是可能存在冲突的(多个key通过计算映射到同一个位置),在同一个位置的元素会按顺序链在后面。
把这个位置称为一个bucket
2.桶子个数的增长规律
template<typename K, typename V,
typename A, typename Ex, typename Eq,
typename H1, typename H2, typename H, typename RP,
bool c, bool ci, bool u>
void
hashtable<K, V, A, Ex, Eq, H1, H2, H, RP, c, ci, u>::
m_rehash(size_type n)
{
node** new_array = m_allocate_buckets(n);
try
{
for (size_type i = 0; i < m_bucket_count; ++i)
while (node* p = m_buckets[i])
{
size_type new_index = this->bucket_index(p, n); // 重新计算桶编号
m_buckets[i] = p->m_next;
p->m_next = new_array[new_index]; // 将当前的index插入到p的后面
new_array[new_index] = p; // 将p作为桶子的表头
}
m_deallocate_buckets(m_buckets, m_bucket_count); // 释放原来的桶子的内存
m_bucket_count = n; // 更新桶子个数
m_buckets = new_array; // 修改桶子指针
}
catch(...)
{
// A failure here means that a hash function threw an exception.
// We can't restore the previous state without calling the hash
// function again, so the only sensible recovery is to delete
// everything.
m_deallocate_nodes(new_array, n);
m_deallocate_buckets(new_array, n);
m_deallocate_nodes(m_buckets, m_bucket_count);
m_element_count = 0;
__throw_exception_again;
}
}为什么unordered_map比hash_map性能更好呢?
hash_map的源码如下
// Re-initialise the hash from the values already contained in the list.
void rehash(std::size_t num_buckets)
{
if (num_buckets == num_buckets_)
return;
num_buckets_ = num_buckets;
BOOST_ASIO_ASSERT(num_buckets_ != 0);
iterator end_iter = values_.end();
// Update number of buckets and initialise all buckets to empty.
bucket_type* tmp = new bucket_type[num_buckets_];
delete[] buckets_;
buckets_ = tmp;
for (std::size_t i = 0; i < num_buckets_; ++i)
buckets_[i].first = buckets_[i].last = end_iter;
...
}每次都要重新申请内存,申请内存的时间造成了大量的浪费。。
3.map与unordered_map的性能比较
map的空间复杂度O(n)
扫描二维码关注公众号,回复:
10552949 查看本文章

插入,查找,删除的空间复杂度均为O(log(n))
unordered_map:
底层是HashTable和桶,当桶的个数不够时会加倍
插入 查找 删除 O(1)复杂度
当内存较小而时间不限制的时候使用map
当内存不限制而时间要求很高的时候用unordered_map
