unordered_map
前言
如果想对unordered_map有一个全面了解的读者可以参考:unordered_map - C++ Reference
正文
相信读者对unordered_map已经有了基本的了解,废话不多说,下面直接说怎样实现:
#include<tr1/unordered_map>//在unordered_map之前加上tr1库名,
using namespace std::tr1;//与此同时需要加上命名空间
//[查找元素是否存在]
unordered_map<int, int> mp
if(mp.find(x)!=mp.end()) //方法一:查找x是否在map中
if(mp.count(x)!=0) //方法二:查找x是否在map中
//[插入数据]
mp[x] = 1; //使用[ ]进行单个插入,若已存在键值2,则赋值修改,若无则插入。
mp.insert(pair<int, int>(x, 1));//使用insert和pair插入
//[遍历map]
unordered_map<key,T>::iterator it;
(*it).first; //the key value
(*it).second //the mapped value
for(unordered_map<key,T>::iterator iter=mp.begin();iter!=mp.end();iter++)
cout<<"key value is"<<iter->first<<" the mapped value is "<< iter->second;
//也可以这样
for(auto& v : mp)
print v.first and v.second基本操作差不多就是这样,那么既然有了map,我们为什么要用unordered_map呢?下面就是两者的比较:
map:
优点:
1.有序性,这是map结构最大的优点,其元素的有序性在很多应用中都会简化很多的操作。
2.红黑树,内部实现一个红黑书使得map的很多操作在lgn的时间复杂度下就可以实现,因此效率非常的高。
缺点:
1.空间占用率高,因为map内部实现了红黑树,虽然提高了运行效率,但是因为每一个节点都需要额外保存父节点、孩子节点和红/黑性质,使得每一个节点都占用大量的空间。
适用处:对于那些有顺序要求的问题,用map会更高效一些。
unordered_map:
优点:
1.因为内部实现了哈希表,因此其查找速度非常的快。
缺点:
1.哈希表的建立比较耗费时间。
适用处:对于查找问题,unordered_map会更加高效一些,因此遇到查找问题,常会考虑一下用unordered_map。
总结:
1. 内存占有率的问题就转化成红黑树 VS hash表 , 还是unorder_map占用的内存要高。
2. 但是unordered_map执行效率要比map高很多 。
3.对于unordered_map或unordered_set容器,其遍历顺序与创建该容器时输入的顺序不一定相同,因为遍历是按照哈希表从前往后依次遍历的。
4.unordered_map的用法和map是一样的,提供了 insert,size,count等操作,并且里面的元素也是以pair类型来存贮的。其底层实现是完全不同的,上方已经解释了,但是就外部使用来说却是一致的。
unordered_map与手写哈希效率比较:
首先来看一道简单哈希题。。。
题目描述
给定两个集合 A、B,集合内的任一元素 x 满足 1≤x≤10^9,并且每个集合的元素个数不大于10^7。我们希望求出 A、B 之间的关系,只需确定在 B 中但是不在 A 中的元素的个数即可。
输入格式
输入文件有两行,分别表示两个集合,每行的第一个整数为这个集合的元素个数(至少一个),然后紧跟着这个集合的元素(均为不同的正整数)。
输出格式
输出文件只有一个整数,即在 B 中但是不在 A 中的元素的个数即可。
首先是手写哈希:
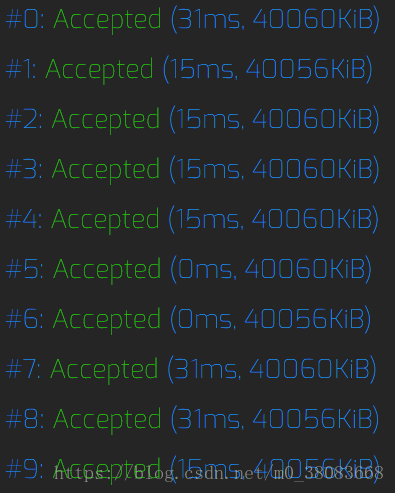
然后是unordered_map:
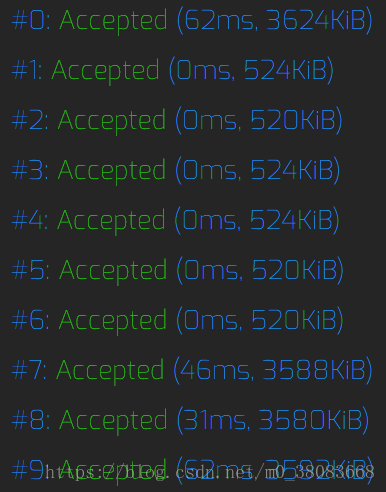
不难看出差异是不大的,所以如果在考场上遇见用哈希来查找,可以考虑使用unordered_map,毕竟至少比手写哈希好写多了。