决策树模型是一种描述对实例进行分类的树形结构。决策树由结点和有向边组成。结点有两种类型:内部节点和叶节点,内部节点表示一个特征或属性,叶节点表示一个类。分类的时候,从根节点开始,对实例的某一个特征进行测试,根据测试结果,将实例分配到其子结点;此时,每一个子结点对应着该特征的一个取值。如此递归向下移动,直至达到叶结点,最后将实例分配到叶结点的类中。
所有的数据最终都会落到叶子节点,既可以做分类也可以做回归。
一个例子:要将一家人分为3类分别为中老年人,少年和少女。我们被给年龄和性别特征。
我们首先可以通过年龄是否大于15将数据分为中老年人(肯定不是少年和少女)和非中老年人。然后在通过性别将非中老年人分为少年和少女。

根节点:第一个选择点(年龄特征)
非叶子节点与分支:中间过程(性别特征)
叶子节点:最终的决策结果(3种分类结果:中老年人,少年和少女)
特征的选取
其实一旦构造好了决策树,那么分类或者预测任务就很简单了,只需要走一遍就可以了,那么难点就在于如何构造出来一颗树,这就没那么容易了,需要考虑的问题还有很多的!
那如何切分特征(选择节点)呢?
特征选择问题希望选取对训练数据具有良好分类能力的特征,这样可以提高决策树学习的效率。如果利用一个特征进行分类的结果没多大影响,则称这个特征是没有分类能力的(老婆是否长得漂亮,身材好不好和有没D啊(⊙o⊙)…,是会成为你找她的关键特征。但是喜欢不喜欢打游戏应该不会成为关键特征吧,也许也许也许也会吧……)。
想象一下,我们要通过一种衡量标准,来计算通过不同特征进行分支选择后的分类情况,找出来最好的那个当成根节点(就像一个老大似的能更好的切分数据(分类效果更好)),然后接下来选择下面的节点也就是二当家,以此类推。
衡量标准-熵
度量样本集合纯度的衡量。熵:熵是表示随机变量不确定性的度量(解释:说白了就是物体内部的混乱程度,比如杂货市场里面什么都有那肯定混乱呀(熵大),专卖店里面只卖一个牌子的那就稳定多啦(熵小))。
公式:
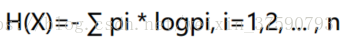
例子:
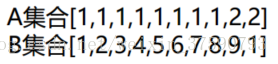
显然A集合的熵值要低,因为A里面只有两种类别,相对稳定一些而B中类别太多了,熵值就会大很多。
不确定性越大,得到的熵值也就越大当p=0或p=1时,H(p)=0,随机变量完全没有不确定性当p=0.5时,H(p)=1,此时随机变量的不确定性最大。

那么在决策树分类任务中我们希望通过节点分支后数据类别的熵值大还是小呢?肯定是熵小啊,熵越小不就信息越确定,越确定不就里面的类越少吗?
信息增益:



基尼系数:

例子:



注意





