在之前学习神经网络的时候,对于损失函数这块,一直以MSE来作为理解,后来交叉熵损失出现之后,也没有深刻地将其理解,写代码时也是直接调用库函数。现在因为读一些新的文章,发现有些看不懂了,因此将这一块知识补充起来。
1、熵(Entropy)
熵的概念来源于信息论,可以代表一个事件的复杂度,或者不确定性。一个事件越是不确定性大,那么就是月复杂,所提供的信息就会越多。
举个例子:事件1:我今天吃了早饭。
事件2:今天中午我要吃什么?
我们来看这两个例子,事件1是一个确定事件,那么它能提供的信息量就很小;第二个就太不确定了吧,你是吃水饺?吃面条?吃米饭?还是吃啥?
总的来说,信息熵应该满足两条特性:1. 越不可能发生的事情,信息量越大;2.独立事件的信息量可以叠加。基于此,我们来看信息熵的定义:
其中,为信息熵,
为某个事件
发生的概率,
为常数(通常取2),
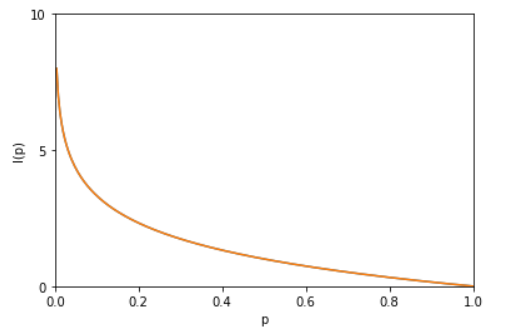
为某个不确定事件所能提供的信息量大小。如果我们来看单个事件的信息熵
,因为
,因此其曲线大概如下图。所以,这个定义是不是满足上面两条特性?而
的由来即是计算所有事件的信息量期望值,即
。
2.相对熵(KL散度)
KL散度是两个概率分布P和Q差别的非对称性的度量,通俗来讲也就是定义了两个事件的不同程度。注意,这时一个非对称的。
直接看定义,对于离散事件,其定义为
,注意来看,减号左侧是不是就等于事件A的信息熵?
3. 交叉熵(cross-entropy)
由上面对相对熵的公式,我们看到减号左侧代表事件A的信息熵,如果事件A是确定不变的,那么相对熵只取决于减号右边。我们把减号右边的东西单独拿出来,定义为交叉熵:。至于其在信息论中的具体解释,我这里不做具体说明,如果想理解透彻,可以参见知乎回答https://www.zhihu.com/question/65288314/answer/244557337。
4.交叉熵损失函数
根据2相对熵,我们知道KL散度代表A与B的差异,但是在机器学习中为什么要用交叉熵,而不是用KL散度呢?借助3中标粗的解释,对于事件A(训练数据的真实样本的label取值情况),其为固定的不变的,因此相对熵的大小只取决于交叉熵,因此,我们可以用交叉熵来衡量我们训练网络的预测label与样本真实的label之间的差异,也因此可以最小化这个差异,来让训练模型能够更接近真实样本。
基于此,我们可以定义交叉熵损失函数。这好像和我们在机器学习论文中看到的还不一致?别着急,我们再来看。一般来讲,对于一张图片的分类任务(如三分类:猫,狗,鱼)(假设某张图片上只有单个类别),那么真实的样本应该是
之类的形式,来代表真实事件中这张图片分类为狗的概率为1,分类为猫和鱼的概率为0;如果网络预测出来的概率为
代入交叉熵损失函数,会变成
。到这里,是不是跟你之前的认知相同了?
5.softmax损失函数
还是对上面那个例子,我们知道softmax函数的作用,其实就是将神经网络输出的“得分”(范围不固定,有可能是3,也有可能是10),归一化到(0,1)之间,代表分类为某个类别的概率,并且所有类别的概率之和为1
。
而softmax损失是:。这是将所有类别i都加进来的表达形式,但是我们知道真实label中只有一个1,其他都是0,因此便可以写成
,当然,这里的j不是一个变量,而是对应于真实label中为1的那个值。对于上面的例子,就是
,即
。到这里,你有没有发现,其实softmax损失和交叉熵损失其实就是一个东西?只不过会有一个前提,就是当交叉熵损失的输入P是由softmax得到的时候,那么交叉熵损失就等于softmax损失。