第一次学习网络流,发表一下自己的看法。
在这篇博文当中主要讲一讲3个最大流算法:EK算法,Dinic算法和SAP算法。
一、EK(Edmonds Karp)算法
首先,假如所有边上的流量都没有超过容量(不大于容量),那么就把这一组流量,或者说,这个流,称为一个可行流。一个最简单的例子就是,零流,即所有的流量都是0的流。
我们就从这个零流开始考虑,假如有这么一条路,这条路从源点开始一直一段一段的连到了汇点,并且,这条路上的每一段都满足流量<容量,注意,是严格的<,而不是<=。那么,我们一定能找到这条路上的每一段的(容量-流量)的值当中的最小值Δ。我们把这条路上每一段的流量都加上这个Δ,一定可以保证这个流依然是可行流,这是显然的。
这样我们就得到了一个更大的流,他的流量是之前的流量+Δ,而这条路就叫做增广路。
我们不断地从起点开始寻找增广路,每次都对其进行增广,直到源点和汇点不连通,也就是找不到增广路为止。当找不到增广路的时候,当前的流量就是最大流,这个结论非常重要。
寻找增广路的时候我们可以简单的从源点开始做bfs,并不断修改这条路上的Δ量,直到找到源点或者找不到增广路。
这里要先补充一点,在程序实现的时候,我们通常只是用一个c数组来记录容量,而不记录流量,当流量+1的时候,我们可以通过容量-1来实现,以方便程序的实现。
但事实上并没有这么简单,上面所说的增广路还不完整,比如说下面这个网络流模型。
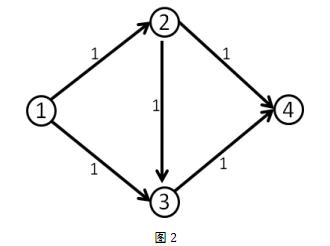
我们第一次找到了1-2-3-4这条增广路,这条路上的delta值显然是1。于是我们修改后得到了下面这个流。(图中的数字是容量)。
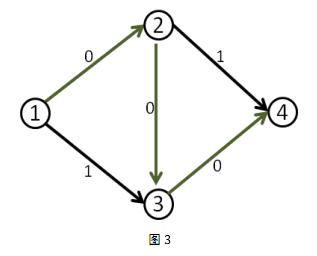
这时候(1,2)和(3,4)边上的流量都等于容量了,我们再也找不到其他的增广路了,当前的流量是1。
但这个答案明显不是最大流,因为我们可以同时走1-2-4和1-3-4,这样可以得到流量为2的流。
那么我们刚刚的算法问题在哪里呢?问题就在于我们没有给程序一个”后悔”的机会,应该有一个不走(2-3-4)而改走(2-4)的机制。那么如何解决这个问题呢?回溯搜索吗?那么我们的效率就上升到指数级了。
而这个算法神奇的利用了一个叫做反向边的概念来解决这个问题。即每条边(I,j)都有一条反向边(j,i),反向边也同样有它的容量。
我们直接来看它是如何解决的:
在第一次找到增广路之后,在把路上每一段的容量减少Δ的同时,也把每一段上的反方向的容量增加Δ。即在Dec(c[x,y],Δ)的同时,inc(c[y,x],Δ)。
我们来看刚才的例子,在找到1-2-3-4这条增广路之后,把容量修改成如下。
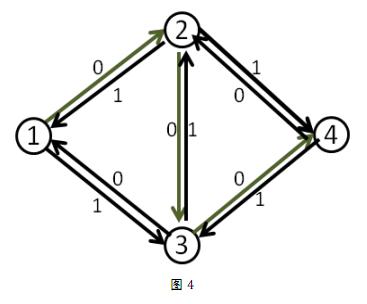
这时再找增广路的时候,就会找到1-3-2-4这条可增广量,即delta值为1的可增广路。将这条路增广之后,得到了最大流2。
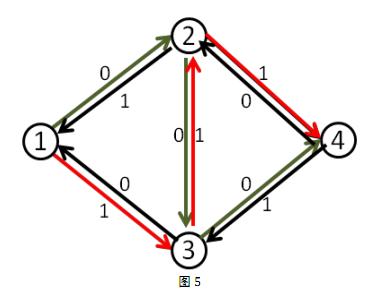
那么,这么做为什么会是对的呢?我来通俗的解释一下吧。
事实上,当我们第二次的增广路走3-2这条反向边的时候,就相当于把2-3这条正向边已经是用了的流量给”退”了回去,不走2-3这条路,而改走从2点出发的其他的路也就是2-4。(有人问如果这里没有2-4怎么办,这时假如没有2-4这条路的话,最终这条增广路也不会存在,因为他根本不能走到汇点)同时本来在3-4上的流量由1-3-4这条路来”接管”。而最终2-3这条路正向流量1,反向流量1,等于没有流量。
这就是这个算法的精华部分,利用反向边,使程序有了一个后悔和改正的机会。而这个算法和我刚才给出的代码相比只多了一句话而已。
例题:POJ1273。
Code:
#include<iostream>
#include<cstdio>
#include<cstring>
#include<cstdlib>
#include<cmath>
#include<algorithm>
#include<queue>
#define inf 10000000
#define N 205
using namespace std;
int r[N][N],flag[N],pre[N],n,m;
bool bfs(int s,int t)
{
int p;
queue<int >Q;
memset(pre,-1,sizeof(pre));
memset(flag,false,sizeof(flag));
pre[s]=s;
flag[s]=true;
Q.push(s);
while(!Q.empty())
{
p=Q.front();
Q.pop();
for(int i=1;i<=n;i++)
if(r[p][i]>0&&!flag[i])
{
pre[i]=p;
flag[i]=true;
if(i==t)return true;
Q.push(i);
}
}
return false;
}
int EK(int s,int t)
{
int flow=0,d;
while(bfs(s,t))
{
d=inf;
for(int i=t;i!=s;i=pre[i])
d=d<r[pre[i]][i]?d:r[pre[i]][i];
for(int i=t;i!=s;i=pre[i])
{
r[pre[i]][i]-=d;
r[i][pre[i]]+=d;
}
flow+=d;
}
return flow;
}
int main()
{
while(~scanf("%d%d",&m,&n))
{
memset(r,0,sizeof(r));
for(int i=1;i<=m;i++)
{
int u,v,w;
scanf("%d%d%d",&u,&v,&w);
r[u][v]+=w;
}
printf("%d\n",EK(1,n));
}
}
二、Dinic算法(百科讲解)
Dinic算法是网络流最大流的优化算法之一,每一步对原图进行分层,然后用DFS求增广路。Dinic算法最多被分为n个阶段,每个阶段包括建层次网络和寻找增广路两部分。
Dinic算法的思想是分阶段地在层次网络中增广。它与最短增广路算法不同之处是:最短增广路每个阶段执行完一次BFS增广后,要重新启动BFS从源点Vs开始寻找另一条增广路;而在Dinic算法中,只需一次BFS过程就可以实现多次增广。
层次图
层次图,就是把原图中的点按照点到源的距离分“层”,只保留不同层之间的边的图。
算法流程
1、根据残量网络计算层次图。
2、在层次图中使用DFS进行增广直到不存在增广路。
3、重复以上步骤直到无法增广。
时间复杂度
因为在Dinic的执行过程中,每次重新分层,汇点所在的层次是严格递增的,而n个点的层次图最多有n层,所以最多重新分层n次。在同一个层次图中,因为每条增广路都有一个瓶颈,而两次增广的瓶颈不可能相同,所以增广路最多m条。搜索每一条增广路时,前进和回溯都最多n次,所以这两者造成的时间复杂度是O(nm);而沿着同一条边(i,j)不可能枚举两次,因为第一次枚举时要么这条边的容量已经用尽,要么点j到汇不存在通路从而可将其从这一层次图中删除。综上所述,Dinic算法时间复杂度的理论上界是O(n^2*m)。
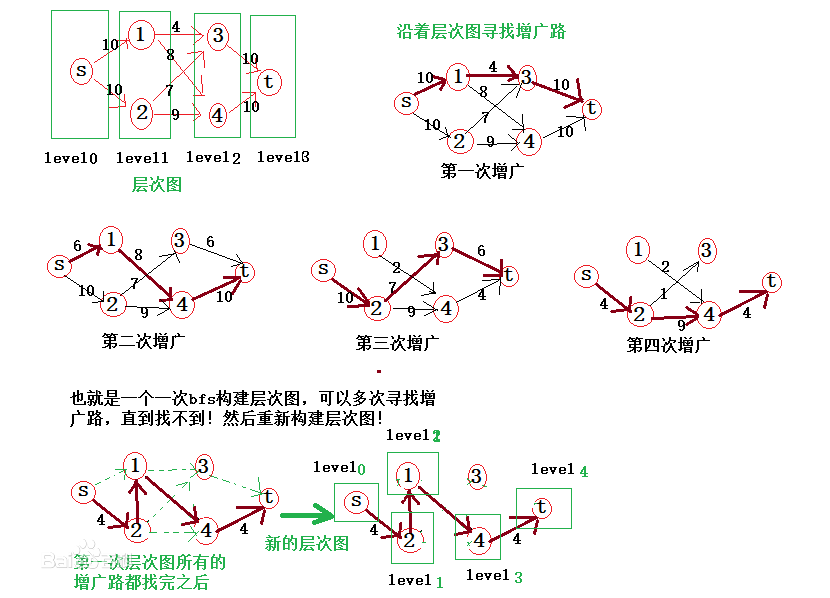
还是POJ1273用Dinic实现。
Code:
#include<iostream>
#include<cmath>
#include<cstring>
#include<cstdlib>
#include<algorithm>
#include<cstdio>
#include<queue>
#define inf 100000000
#define N 10005
using namespace std;
int s,t,n,m,tot;
struct node
{
int next,vet,cap;
}edge[N];
int head[N],deep[N];
void add(int x,int y,int z)
{
edge[++tot].vet=y;
edge[tot].next=head[x];
edge[tot].cap=z;
head[x]=tot;
}
int bfs()
{
memset(deep,0,sizeof(deep));
queue<int> Q;
while(!Q.empty())Q.pop();
deep[s]=1;
Q.push(s);
do
{
int u=Q.front();
Q.pop();
for(int i=head[u];i!=-1;i=edge[i].next)
{
if(edge[i].cap>0&&deep[edge[i].vet]==0)
{
deep[edge[i].vet]=deep[u]+1;
Q.push(edge[i].vet);
}
}
}while(!Q.empty());
if(deep[t]!=0)return 1;else return 0;
}
int dfs(int u,int dist)
{
if(u==t)return dist;
for(int i=head[u];i!=-1;i=edge[i].next)
{
if((deep[edge[i].vet]==deep[u]+1)&&(edge[i].vet!=0))
{
int d=dfs(edge[i].vet,min(dist,edge[i].cap));
if(d>0)
{
edge[i].cap-=d;
edge[i^1].cap+=d;
return d;
}
}
}
return 0;
}
int dinic()
{
int ans=0;
while(bfs())
while(int d=dfs(s,inf))ans+=d;
printf("%d\n",ans);
}
int main()
{
while(~scanf("%d%d",&m,&n))
{
s=1;t=n;
int x,y,z;
tot=0;//如果是tot=-1更快,神奇,洛谷里tot=0WA了,tot=-1A了,神奇
//哪位大神知道为什么麻烦告诉我一下,谢谢。
memset(head,-1,sizeof(head));
memset(edge,0,sizeof(edge));
for(int i=0;i<m;i++)
{
scanf("%d%d%d",&x,&y,&z);
add(x,y,z);
add(y,x,0);
}
dinic();
}
return 0;
}三、SAP算法(未完待续)