图论-网络流③-最大流②
上一篇:图论-网络流②-最大流①
下一篇:图论-网络流④-最大流解题①
参考文献:
- https://www.cnblogs.com/DuskOB/p/11216861.html
- https://blog.csdn.net/yjr3426619/article/details/82808303
- https://blog.csdn.net/lym940928/article/details/90209172
- https://baike.baidu.com/item/%E7%BD%91%E7%BB%9C%E6%B5%81/2987528?fr=aladdin
- https://www.cnblogs.com/pk28/p/8039645.html
- https://blog.csdn.net/disgustinglemon/article/details/51296636
大纲
- 什么是网络流
- 最大流(最小割)
- (常用)
- (不讲)
- (快)
- 最大流解题
- 费用流
- 费用流
- 费用流
- 费用流
- 费用流
- 费用流解题
- 有上下界的网络流
- 无源汇上下界可行流
- 有源汇上下界可行流
- 有源汇上下界最大流
- 有源汇上下界最小流
- 最大权闭合子图
- 有上下界的网络流解题
上一篇中讲了最大流定义、最小割定理以及 算法,这篇中会讲剩下三种最大流算法: , 和 。
EK
的全称叫 。是一个与 相比代码较短,跑得较慢的算法。
就是简单地暴力搜索整个网络流图。在每次搜索增广路的时候,都采取 的策略,将所有的从源点到汇点的路径都找出来,那么如果有增广路,就一定可以将它找出来。因此采用 策略首先是正确的,代码:
#include<bits/stdc++.h>
using namespace std;
const int N=210;
const int inf=0x3f3f3f3f;
int n,m,s,t;
int fw[N][N],pre[N]; //残留网络,初始化为原图
bool vis[N];
queue<int> q;
bool bfs(int s,int t){//寻找一条从s到t的增广路,若找到返回true
memset(pre,0,sizeof pre);
memset(vis,0,sizeof vis);
while(q.size()) q.pop();
q.push(s),pre[s]=s,vis[s]=1;
while(q.size()){
int x=q.front();q.pop();
for(int i=1;i<=n;i++)
if(fw[x][i]>0&&!vis[i]){
pre[i]=x,vis[i]=1;
if(i==t) return 1;
q.push(i);
}
}
return 0;
}
int EdmondsKarp(int s,int t){
int flow=0,f;
while(bfs(s,t)){
f=inf;
for(int i=t;i!=s;i=pre[i])
f=min(f,fw[pre[i]][i]);
for(int i=t;i!=s;i=pre[i])
fw[pre[i]][i]-=f,fw[i][pre[i]]+=f;
flow+=f;
}
return flow;
}
int main(){
scanf("%d%d%d%d",&n,&m,&s,&t);
for(int i=1,x,y,f;i<=m;i++){
scanf("%d%d%d",&x,&y,&f);
fw[x][y]+=f;
}
printf("%d\n",EdmondsKarp(s,t));
return 0;
}
比较
已经不抽象很多了,但为了方便理解,举以下图例:
可以看出
算法有很多多余的增广与遍历。《算法导论》中证明了在每次
查找增广路之后,最短增广路的长度一定是非减的,也即对于每一个节点,它到源点的最短距离是非减的。 同时根据
的增广过程,我们可以推导出在
算法中所能找到的增广路的数量为
。由于
找增广路的时间复杂度为
,而至多进行
次查找,因此就可以得出
算法的时间复杂度为
。
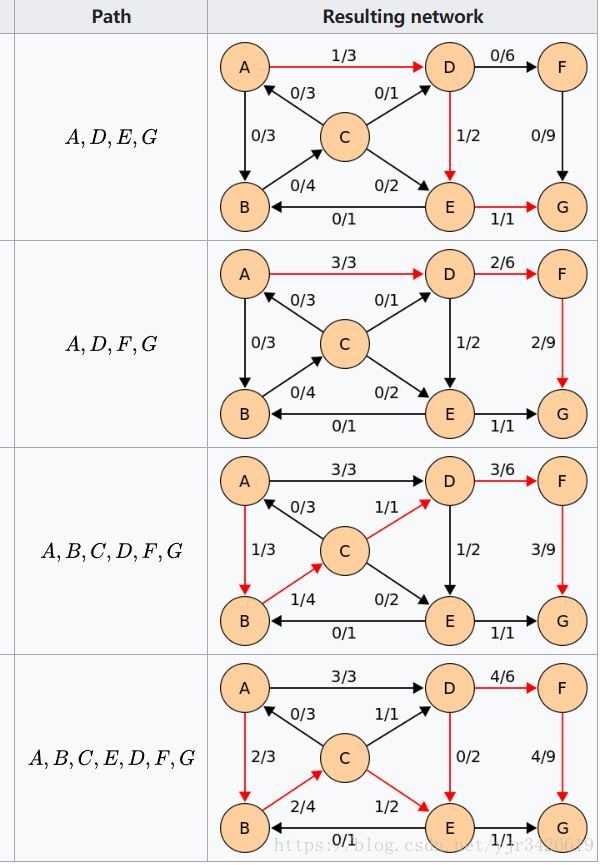
虽说 算法是“时间换码量”,但当整个图是稀疏图的时候,使用 算法不失为一种简便可行的方法,但是如果图的边数非常多,这个算法的性能也就显得不是那么优秀。
SAP
算法是对 算法一个小的优化。在 算法中,每次增广都要进行一次 来更新层次网络,这是一种浪费,因为有些点的层次实际上是不需要更新的。 算法就采取一边找增广路,一边更新层次网络的策略。代码:
#include <bits/stdc++.h>
using namespace std;
const int N=1e3+10;
const int M=2e5+10;
const int inf=0x3f3f3f3f;
int n,m,s,t,fw[N][N]; //邻接矩阵
int dep[N],gap[N],pre[N]; //层次、gap优化、前驱
int SAP(int s,int t){
int flow=0,x=s,y,f;
gap[0]=n,pre[s]=s;
while(dep[s]<n){
for(y=1;y<=n;y++)
if(fw[x][y]&&dep[x]==dep[y]+1) break; //找增广边
if(y<=n){//找到了
pre[y]=x,x=y;
if(x==t){ //找到了一条增广路
f=inf;
for(int i=x;i!=s;i=pre[i])
f=min(f,fw[pre[i]][i]);
flow+=f;
for(int i=x;i!=s;i=pre[i])
fw[pre[i]][i]-=f,fw[i][pre[i]]+=f;
x=s; //同EK
}
} else {
f=inf;
for(int i=1;i<=n;i++)
if(fw[x][i]) f=min(f,dep[i]);
gap[dep[x]]--;
if(!gap[dep[x]]) break;
dep[x]=f+1,gap[dep[x]]++,x=pre[x]; //gap优化,使层次尽量小
}
}
return flow;
}
int main(){
scanf("%d%d%d%d",&n,&m,&s,&t);
for(int i=1,x,y,f;i<=m;i++){
scanf("%d%d%d",&x,&y,&f);
fw[x][y]+=f;
}
printf("%d\n",SAP(s,t));
return 0;
}
在 算法中源点的层次是最高的。一定要有 优化,这个算法的时间复杂度优越性也得不到良好的表现。 算法的复杂度上界和 一样也是 。
HLPP
算法即最高标号预流推进算法。与前面三种算法不同的是,它并不采取找增广路的思想,而是不断地在可行流中找到那些仍旧有盈余的节点,将其盈余的流量推到周围可接纳流量的节点中。
对于一个最大流而言,除了源点和汇点以外所有的其他节点都应该满足流入的总流量等于流出的总流量,如果首先让源点的流量都尽可能都流到其相邻的节点中,这个时候相邻的节点就有了盈余,即它流入的流量比流出的流量多,所以要想办法将这些流量流出去。这种想法其实很自然,如果不知道最大流求解的任何一种算法,要手算最大流的时候,采取的策略肯定会是这样,将能流的先流出去,遇到容量不足的边就将流量减少,直到所有流量都流到了汇点。
但是这样做肯定会遇到一个问题,可能会有流量从一个节点流出去然后又流回到这个节点。如果这个节点是源点的话这么做是没问题的,因为有的时候通过某些节点是到达不了汇点的,这个时候要将流量流回到源点,但是其他情况就可能会造成循环流动,因此需要用到层次网络,只在相邻层次间流动。
#include <bits/stdc++.h>
using namespace std;
#define lng long long
#define fo(i,a,b,c) for(int i=a;i<=b;i+=c)
#define al(i,g,x) for(int i=g[x];i;i=e[i].nex)
const int V=2e3;
const int M=4e5;
const int inf=0x3f3f3f3f;
int n,m,s,t,p;
namespace graph{
class edge{
public:
int adj,nex,fw;
}e[M];
int g[V],top=1;
void add(int x,int y,int w){
e[++top]=edge{y,g[x],w},g[x]=top;
}
void Add(int x,int y,int w){
add(x,y,w),add(y,x,0);
}
}using namespace graph;
namespace HLPP{
int fl[V],dep[V],ct[V<<1]; //节点盈余、层次和gap优化
bool vis[V]; //访问
queue<int> Q;
class cmp{public:
bool operator()(int x,int y){return dep[x]<dep[y];}
};
priority_queue<int,vector<int>,cmp> q; //优先推进层次高的节点
bool bfs(){ //和Dinic差不多的bfs
fo(i,1,p,1) dep[i]=inf,vis[i]=0;
Q.push(t),dep[t]=0,vis[t]=1;
while(Q.size()){
int x=Q.front();Q.pop(),vis[x]=0;
al(i,g,x){ int to=e[i].adj;
if(e[i^1].fw&&dep[to]>dep[x]+1){
dep[to]=dep[x]+1;
if(!vis[to]) Q.push(to),vis[to]=1;
}
}
}
return dep[s]<inf;
}
void Push(int x){ //推x节点盈余的流
al(i,g,x){ int to=e[i].adj;
if(e[i].fw&&dep[to]+1==dep[x]){
int f=min(fl[x],e[i].fw);
e[i].fw-=f,e[i^1].fw+=f;
fl[x]-=f,fl[to]+=f;
if(!vis[to]&&to!=t&&to!=s)
q.push(to),vis[to]=1;
if(!fl[x]) break;
}
}
}
void Low(int x){ //gap优化,离散化层次
dep[x]=inf;
al(i,g,x){ int to=e[i].adj;
if(e[i].fw&&dep[x]>dep[to]+1)
dep[x]=dep[to]+1;
}
}
int hlpp(){
if(!bfs()) return 0;
dep[s]=p; //源点层次最高
fo(i,1,p,1)if(dep[i]<inf)
ct[dep[i]]++;
al(i,g,s){int to=e[i].adj,f; //先将源点推流
if((f=e[i].fw)>0){
e[i].fw-=f,e[i^1].fw+=f;
fl[s]-=f,fl[to]+=f;
if(to!=t&&to!=s&&!vis[to])
q.push(to),vis[to]=1;
}
}
while(q.size()){ //取层次大的节点预流推进
int x=q.top();q.pop(),vis[x]=0;
Push(x);
if(fl[x]){
if(!--ct[dep[x]]) //Gap优化
fo(to,1,p,1) if(to!=s&&to!=t
&&dep[to]>dep[x]&&dep[to]<=p)
dep[to]=p+1;
Low(x),ct[dep[x]]++;
q.push(x),vis[x]=1;
}
}
return fl[t];
}
}using namespace HLPP;
int main(){
scanf("%d%d%d%d",&n,&m,&s,&t),p=n;
fo(i,1,m,1){
int x,y,z;
scanf("%d%d%d",&x,&y,&z);
Add(x,y,z);
}
printf("%d\n",hlpp());
return 0;
}
推进都是从高层次节点推到低层次节点中,源点的层次始终为节点总数。我们注意到预流推进算法的程序实现中有个优先队列,这使得程序会先取层次较高的节点推进。因为层次较低的节点是有可能接受到层次高节点流出的流量的,如果先推层次低的节点的流量,之后它有可能又接受到了高层次节点的流量,那么又要对其作推进处理。而如果每次都先将高层次节点取出,就可以将所有的高层次的节点的流量都先推入对应的低层次的节点中,在低层次的节点中先累积流量,最后再一起推进,提升效率。
特别的, 算法的时间复杂度上限为 ,所以有时 过得了别的算法过不了的题。
下一篇会讲最大流解题技巧、方法。
祝大家学习愉快!
