文章目录
一、Encoder-Decoder(编码-解码)
介绍
Encoder-Decoder是一个模型构架,是一类算法统称,并不是特指某一个具体的算法,在这个框架下可以使用不同的算法来解决不同的任务。首先,编码(encode)由一个编码器将输入序列转化成一个固定维度的稠密向量,解码(decode)阶段将这个激活状态生成目标译文。
回顾一下,算法设计的基本思路:将现实问题转化为一类可优化或者可求解的数学问题,利用相应的算法来实现这一数学问题的求解,然后再应用到现实问题中,从而解决了现实问题。(比如,我们想解决一个词性标注的任务(现实问题),我们转化成一个BIO序列标注问题(数学模型),然后设计一系列的算法进行求解,如果解决了这个数学模型,从而也就解决了词性标注的任务)。
Encoder :编码器,如下。

Decoder:解码器,如下。

合并起来,如下:

更具体一点的表达如下所示:
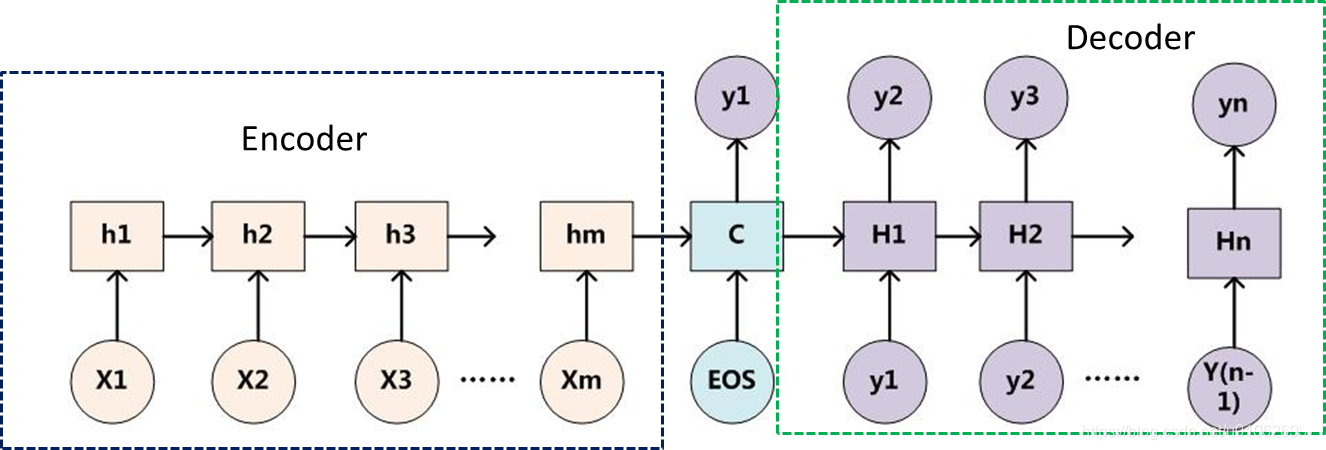
几点说明
- 不论输入和输出的长度是什么,中间的“向量c”长度都是固定的(这是它的缺陷所在)。
- 根据不同的任务可以选择不同的编码器和解码器(例如,CNN、RNN、LSTM、GRU等)
- Encoder-Decoder的一个显著特征就是:它是一个end-to-end的学习算法。
- 只要符合这种框架结构的模型都可以统称为Encoder-Decoder模型。
信息丢失的问题
通过上文可以知道编码器和解码器之间有一个共享的向量(上图中的向量c),来传递信息,而且它的长度是固定的。这会产生一个信息丢失的问题,也就是说,编码器要将整个序列的信息压缩进一个固定长度的向量中去。但是这样做有两个弊端,一是语义向量无法完全表示整个序列的信息,还有就是先输入的内容携带的信息会被后输入的信息稀释掉,或者说,被覆盖了。输入序列越长,这个现象就越严重。这就使得在解码的时候一开始就没有获得输入序列足够的信息,那么解码的准确度自然也就要打个折扣了。如果编码过程产生的不是一个固定长度的向量而是一系列向量,是不是会保留更多的信息呢。
便于理解,我们把“编码-解码”的过程类比为“压缩-解压”的过程:
将一张 800X800 像素的图片压缩成 100KB,看上去还比较清晰。而将一张 3000X3000 像素的图片也压缩到 100KB,看上去就模糊了。

基础的Encoder-Decoder是存在很多弊端的,最大的问题就是信息丢失。Encoder将输入编码为固定大小的向量的过程实际上是一个“信息有损的压缩过程”,如果信息量越大,那么这个转化向量的过程对信息的损失就越大,同时,随着序列长度(sequence length)的增加,意味着时间维度上的序列很长,RNN模型就会出现梯度弥散的问题。由于基础的Encoder-Decoder模型链接Encoder和Decoder的组件仅仅是一个固定大小的状态向量,这就使得Decoder无法直接无关注输入信息的更多细节。为了解决这些缺陷,随后又引入了Attention机制以及Bi-directional encoder layer等。Attention模型的特点是Encoder不再将整个输入序列编码为固定长度的中间向量,而是编码成一个【向量序列】。这样,在产生每一个输出的时候,都能够做到充分利用输入序列携带的信息。而且这种方法在翻译任务中取得了非常不错的成果。如下图所示

应用
一般情况下,输入端的形式各种各样(例如图片,文本、语音等),输出端的形式一般是文本格式,输入序列和输出序列的长度可能会有较大的差异(例如,一对一,多对多,多对一,一对多等)。

Seq2Seq就是该模型框架的一个典型代表。
二、Seq2Seq(序列到序列)
介绍
所谓的Sequence2Sequence任务主要是泛指一些Sequence到Sequence的映射问题,Sequence在这里可以理解为一个字符串序列,当我们在给定一个字符串序列后,希望得到与之对应的另一个字符串序列(如 翻译后的、如语义上对应的)时,这个任务就可以称为Sequence2Sequence了。这种结构最重要的地方在于输入序列和输出序列的长度是可变的。
Seq2Seq与Encoder-Decoder
Seq2Seq可以看作是Encoder-Decoder针对某一类任务的模型框架,它们的范围关系如下所示:
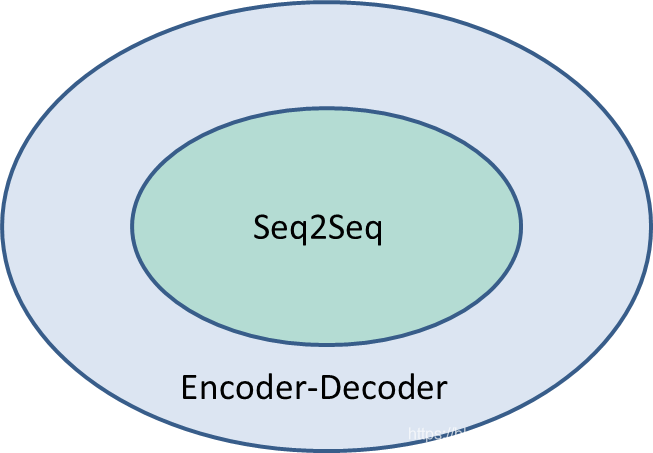
Encoder-Decoder强调的是模型设计(编码-解码的一个过程),Seq2Seq强调的是任务类型(序列到序列的问题)。
三、代码实现
任务描述
给定一个输入单词(字母序列),例如,python,设计模型,使得输出为:按照字母顺序排序,例如hnopty
数据集
- source_data数据集:每一行是一个单词
- target_data数据集:每一行是经过字母排序后的“单词”
- source_data和target_data中每一行是一一对应的
设计模型
Seq2Seq模型:主要包括Encoder、Decoder以及连接两者的国定大小的状态向量(State Vector)。
模型的实现过程
数据预处理
在神经网络中,对于文本的数据预处理无非是将文本转化为模型可理解的数字,这里都比较熟悉,不作过多解释。但在这里我们需要加入以下四种字符,<PAD>主要用来进行字符补全,<EOS>和<GO>都是用在Decoder端的序列中,告诉解码器句子的起始与结束,<UNK>则用来替代一些未出现过的词或者低频词。
- < PAD>: 补全字符。
- < EOS>: 解码器端的句子结束标识符。
- < UNK>: 低频词或者一些未遇到过的词等。
- < GO>: 解码器端的句子起始标识符。
代码如下:
encoder-decoder.py
#参考:https://zhuanlan.zhihu.com/p/27608348
import numpy as np
import time
import tensorflow as tf
from tensorflow.python.layers.core import Dense
#数据加载
with open('data/source_data.txt','r',encoding='utf-8') as fs:
source_data=fs.read()
with open('data/target_data.txt','r',encoding='utf-8') as ft:
target_data=ft.read()
#数据预处理
def extract_character_vocab(data):
special_words=['<PAD>','<UNK>','<GO>','<EOS>']
set_words=list(set([character for line in data.split('\n') for character in line]))
#构造映射表
int_to_vocab={idx:word for idx,word in enumerate(special_words+set_words)}
vocab_to_int={word:idx for idx,word in int_to_vocab.items()}
return int_to_vocab,vocab_to_int
#print(source_int[:10])
#建立模型
#输入层
def get_inputs():
'''
模型输入tensor
:return:
'''
inputs=tf.placeholder(tf.int32,[None,None],name='inputs')
targets=tf.placeholder(tf.int32,[None,None],name='targets')
learning_rate=tf.placeholder(tf.float32,name='learning_rate')
#定义target序列的最大长度,之后target_sequence_length和source_sequence_length会作为feed_dict的参数
target_sequence_length=tf.placeholder(tf.int32,(None,),name='target_sequence_length')
max_target_sequence_length=tf.reduce_max(target_sequence_length,name='max_target_len')
source_sequence_length=tf.placeholder(tf.int32,(None,),name='source_sequence_length')
return inputs,targets,learning_rate,target_sequence_length,max_target_sequence_length,source_sequence_length
#Encoder
def get_encoder_layer(input_data,rnn_size,num_layers,source_sequence_length,
source_vocab_size,encoding_embedding_size):
'''
构造Encoder层
:param input_data:输入tensor
:param run_size: RNN隐藏层节点数量
:param num_layers: 堆叠的rnn cell数量
:param source_sequence_length: 源数据序列长度
:param source_vocab_size: 源数据词典大小
:param encoding_embedding_size: embeding的大小
:return:
'''
#Encoder embedding
encoder_embed_input=tf.contrib.layers.embed_sequence(input_data,source_vocab_size,encoding_embedding_size)
# RNN Cell
def get_lstm_cell(rnn_size):
lstm_cell=tf.contrib.rnn.LSTMCell(rnn_size,initializer=tf.random_uniform_initializer(-0.1,0.1,seed=2))
return lstm_cell
cell=tf.contrib.rnn.MultiRNNCell([get_lstm_cell(rnn_size) for _ in range(num_layers)])
encoder_output,encoder_state=tf.nn.dynamic_rnn(cell,encoder_embed_input,
sequence_length=source_sequence_length,dtype=tf.float32)
print('encoder_output: ',encoder_output)
print('encoder_state:',encoder_state)
return encoder_output,encoder_state
#Decoder
def process_decoder_input(data, vocab_to_int, batch_size):
'''
补充<GO>,并移除最后一个字符
'''
# cut掉最后一个字符
ending = tf.strided_slice(data, [0, 0], [batch_size, -1], [1, 1])#cut掉最后一个字符
decoder_input = tf.concat([tf.fill([batch_size, 1], vocab_to_int['<GO>']), ending], 1)#将<GO>添加到第一个字符中
return decoder_input
#同样的,我们还需要对target进行embedding,使得他们能够传入Decoder的RNN中
def decoding_layer(target_letter_to_int, decoding_embedding_size, num_layers, rnn_size,
target_sequence_length, max_target_sequence_length, encoder_state, decoder_input):
'''
构造Decoder层
参数:
- target_letter_to_int: target数据的映射表
- decoding_embedding_size: embed向量大小
- num_layers: 堆叠的RNN单元数量
- rnn_size: RNN单元的隐层结点数量
- target_sequence_length: target数据序列长度
- max_target_sequence_length: target数据序列最大长度
- encoder_state: encoder端编码的状态向量
- decoder_input: decoder端输入
'''
# 1. Embedding
target_vocab_size = len(target_letter_to_int)
print('target_vocab_size: ',len(target_letter_to_int))
decoder_embeddings = tf.Variable(tf.random_uniform([target_vocab_size, decoding_embedding_size]))
print('decoder_embeddings: ',decoder_embeddings)
decoder_embed_input = tf.nn.embedding_lookup(decoder_embeddings, decoder_input)
print('decoder_embed_input: ',decoder_embed_input)
# 2. 构造Decoder中的RNN单元
def get_decoder_cell(rnn_size):
decoder_cell = tf.contrib.rnn.LSTMCell(rnn_size,
initializer=tf.random_uniform_initializer(-0.1, 0.1, seed=2))
return decoder_cell
cell = tf.contrib.rnn.MultiRNNCell([get_decoder_cell(rnn_size) for _ in range(num_layers)])
# 3. Output全连接层
output_layer = Dense(target_vocab_size,
kernel_initializer = tf.truncated_normal_initializer(mean = 0.0, stddev=0.1))
print('output_layer: ',output_layer)
'''
Dense层这里可以这样理解:
对Decoder层的输出做映射(projection),Dense会把输出变成字典大小,
这样才能计算预测出来哪个单词的概率最大呀
'''
# 4. Training decoder
with tf.variable_scope("decode"):
# 得到help对象
training_helper = tf.contrib.seq2seq.TrainingHelper(inputs=decoder_embed_input,
sequence_length=target_sequence_length,
time_major=False)
#print('training_helper: ',training_helper)
# 构造decoder
training_decoder = tf.contrib.seq2seq.BasicDecoder(cell,
training_helper,
encoder_state,
output_layer)
#print('training_decoder: ',training_decoder)
training_decoder_output, training_state,training_sequence_lengths = tf.contrib.seq2seq.dynamic_decode(training_decoder,impute_finished=True,
maximum_iterations=max_target_sequence_length)
print('training_decoder_output',training_decoder_output)
print('traininig_state',training_state)
print('traininig_sequence_length',training_sequence_lengths)
# 5. Predicting decoder
# 与training共享参数
with tf.variable_scope("decode", reuse=True):
# 创建一个常量tensor并复制为batch_size的大小
start_tokens = tf.tile(tf.constant([target_letter_to_int['<GO>']], dtype=tf.int32), [batch_size],
name='start_tokens')
predicting_helper = tf.contrib.seq2seq.GreedyEmbeddingHelper(decoder_embeddings,
start_tokens,
target_letter_to_int['<EOS>'])
predicting_decoder = tf.contrib.seq2seq.BasicDecoder(cell,
predicting_helper,
encoder_state,
output_layer)
predicting_decoder_output, _,_ = tf.contrib.seq2seq.dynamic_decode(predicting_decoder,impute_finished=True,
maximum_iterations=max_target_sequence_length)
return training_decoder_output, predicting_decoder_output
#Seq2Seq
#上面已经构建完成Encoder和Decoder,下面将这两部分连接起来,构建seq2seq模型
def seq2seq_model(input_data, targets, lr, target_sequence_length,
max_target_sequence_length, source_sequence_length,
source_vocab_size, target_vocab_size,
encoding_embedding_size, decoding_embedding_size,
rnn_size, num_layers):
# 获取encoder的状态输出
_, encoder_state = get_encoder_layer(input_data,
rnn_size,
num_layers,
source_sequence_length,
source_vocab_size,
encoding_embedding_size)
# 预处理后的decoder输入
decoder_input = process_decoder_input(targets, target_letter_to_int, batch_size)
print('decoder_input: ',decoder_input)
# 将状态向量与输入传递给decoder
training_decoder_output, predicting_decoder_output = decoding_layer(target_letter_to_int,
decoding_embedding_size,
num_layers,
rnn_size,
target_sequence_length,
max_target_sequence_length,
encoder_state,
decoder_input)
print('training_decoder_output:',training_decoder_output)
return training_decoder_output, predicting_decoder_output
source_int_to_letter,source_letter_to_int=extract_character_vocab(source_data)
target_int_to_letter,target_letter_to_int=extract_character_vocab(target_data)
source_int=[[source_letter_to_int.get(letter,source_letter_to_int['<UNK>'])for letter in line]
for line in source_data.split('\n')]
target_int=[[target_letter_to_int.get(letter,target_letter_to_int['<UNK>'])for letter in line]
+[target_letter_to_int['<EOS>']] for line in target_data.split('\n')]
# 超参数
# Number of Epochs
epochs = 60
# Batch Size
batch_size = 128
# RNN Size
rnn_size = 50
# Number of Layers
num_layers = 2
# Embedding Size
encoding_embedding_size = 15
decoding_embedding_size = 15
# Learning Rate
learning_rate = 0.001
# 构造graph
train_graph = tf.Graph()
with train_graph.as_default():
# 获得模型输入
input_data, targets, lr, target_sequence_length, max_target_sequence_length, source_sequence_length = get_inputs()
training_decoder_output, predicting_decoder_output = seq2seq_model(input_data,
targets,
lr,
target_sequence_length,
max_target_sequence_length,
source_sequence_length,
len(source_letter_to_int),
len(target_letter_to_int),
encoding_embedding_size,
decoding_embedding_size,
rnn_size,
num_layers)
print('training_decoder_output',training_decoder_output)
#print(predicting_decoder_output)
training_logits = tf.identity(training_decoder_output.rnn_output, 'logits')
predicting_logits = tf.identity(predicting_decoder_output.sample_id, name='predictions')
masks = tf.sequence_mask(target_sequence_length, max_target_sequence_length, dtype=tf.float32, name='masks')
#masks:[128,8]
'''
mask在这里的可以这样理解:在计算loss的时候,忽略掉padding部分。
比如我们的batch 是5,意味着我们每次训练5个句子,这五个句子的实际长
度肯定是不一样的,比如句子长度分别是5,3,8,10,3,那么我们在传入
训练时,会把整个batch 的句子都pad 到10,同样的,对于target 句子也
是这样,把一个batch 中数据处理为同一个长度,那么在计算loss 的时候,
我们实际上是不想计算每个句子padding 部分的loss,只计算真实长度的部分。
所以用mask 来乘以句子,对应padding 部分会变成0,也就不会算入loss
'''
with tf.name_scope("optimization"):
# Loss function
cost = tf.contrib.seq2seq.sequence_loss(
training_logits,
targets,
masks)
# Optimizer
optimizer = tf.train.AdamOptimizer(lr)
# Gradient Clipping
gradients = optimizer.compute_gradients(cost)
capped_gradients = [(tf.clip_by_value(grad, -5., 5.), var) for grad, var in gradients if grad is not None]
train_op = optimizer.apply_gradients(capped_gradients)
def pad_sentence_batch(sentence_batch, pad_int):
'''
对batch中的序列进行补全,保证batch中的每行都有相同的sequence_length
参数:
- sentence batch
- pad_int: <PAD>对应索引号
'''
max_sentence = max([len(sentence) for sentence in sentence_batch])
return [sentence + [pad_int] * (max_sentence - len(sentence)) for sentence in sentence_batch]
def get_batches(targets, sources, batch_size, source_pad_int, target_pad_int):
'''
定义生成器,用来获取batch
'''
for batch_i in range(0, len(sources)//batch_size):
start_i = batch_i * batch_size
sources_batch = sources[start_i:start_i + batch_size]
targets_batch = targets[start_i:start_i + batch_size]
# 补全序列
pad_sources_batch = np.array(pad_sentence_batch(sources_batch, source_pad_int))
pad_targets_batch = np.array(pad_sentence_batch(targets_batch, target_pad_int))
# 记录每条记录的长度
targets_lengths = []
for target in targets_batch:
targets_lengths.append(len(target))
source_lengths = []
for source in sources_batch:
source_lengths.append(len(source))
yield pad_targets_batch, pad_sources_batch, targets_lengths, source_lengths
# 将数据集分割为train和validation
train_source = source_int[batch_size:batch_size+batch_size]
train_target = target_int[batch_size:batch_size+batch_size]
# 留出一个batch进行验证
valid_source = source_int[:batch_size]
valid_target = target_int[:batch_size]
(valid_targets_batch, valid_sources_batch, valid_targets_lengths, valid_sources_lengths) = next(get_batches(valid_target, valid_source, batch_size,
source_letter_to_int['<PAD>'],
target_letter_to_int['<PAD>']))
#print(valid_targets_batch, valid_sources_batch, valid_targets_lengths, valid_sources_lengths)
display_step = 50 # 每隔50轮输出loss
checkpoint = "trained_model.ckpt"
with tf.Session(graph=train_graph) as sess:
sess.run(tf.global_variables_initializer())
for epoch_i in range(1, epochs+1):
for batch_i, (targets_batch, sources_batch, targets_lengths, sources_lengths) in enumerate(
get_batches(train_target, train_source, batch_size,
source_letter_to_int['<PAD>'],
target_letter_to_int['<PAD>'])):
#print(batch_i, (targets_batch, sources_batch, targets_lengths, sources_lengths))
_, loss,train_out,predic_out = sess.run(
[train_op, cost,training_logits,predicting_logits],
{input_data: sources_batch,
targets: targets_batch,
lr: learning_rate,
target_sequence_length: targets_lengths,
source_sequence_length: sources_lengths})
print('train_out',train_out.shape)
#print('train_out',train_out)
print('predict_out',predic_out.shape)
#print('predict_out',predic_out)
if batch_i % display_step == 0:
# 计算validation loss
validation_loss = sess.run(
[cost],
{input_data: valid_sources_batch,
targets: valid_targets_batch,
lr: learning_rate,
target_sequence_length: valid_targets_lengths,
source_sequence_length: valid_sources_lengths})
print('Epoch {:>3}/{} Batch {:>4}/{} - Training Loss: {:>6.3f} - Validation loss: {:>6.3f}'
.format(epoch_i,
epochs,
batch_i,
len(train_source) // batch_size,
loss,
validation_loss[0]))
# 保存模型
saver = tf.train.Saver()
saver.save(sess, checkpoint)
print('Model Trained and Saved')
#预测模型
def source_to_seq(text):
'''
对源数据进行转换
:param text:
:return:
'''
sequence_length=7
return [source_letter_to_int.get(word,source_letter_to_int['<UNK>'])for word in text]+\
[source_letter_to_int['<PAD>']]*(sequence_length-len(text))
#输入一个单词
input_word='common'
text=source_to_seq(input_word)
#print(text)
#print( [text]*batch_size)
checkpoint = "./trained_model.ckpt"
loaded_graph = tf.Graph()
with tf.Session(graph=loaded_graph) as sess:
# 加载模型
loader = tf.train.import_meta_graph(checkpoint + '.meta')
loader.restore(sess, checkpoint)
input_data = loaded_graph.get_tensor_by_name('inputs:0')
print('test input_data',input_data)
logits = loaded_graph.get_tensor_by_name('predictions:0')
print('test logits:',logits)
source_sequence_length = loaded_graph.get_tensor_by_name('source_sequence_length:0')
target_sequence_length = loaded_graph.get_tensor_by_name('target_sequence_length:0')
answer_logits = sess.run(logits, {input_data: [text]*batch_size,
target_sequence_length: [len(input_word)]*batch_size,
source_sequence_length: [len(input_word)]*batch_size})
print(answer_logits.shape)
#print(answer_logits)
answer_logits=answer_logits[0]
#print(answer_logits)
pad = source_letter_to_int["<PAD>"]
print('原始输入:', input_word)
print('\nSource')
print(' Word 编号: {}'.format([i for i in text]))
print(' Input Words: {}'.format(" ".join([source_int_to_letter[i] for i in text])))
print('\nTarget')
print(' Word 编号: {}'.format([i for i in answer_logits if i != pad]))
print(' Response Words: {}'.format(" ".join([target_int_to_letter[i] for i in answer_logits if i != pad])))
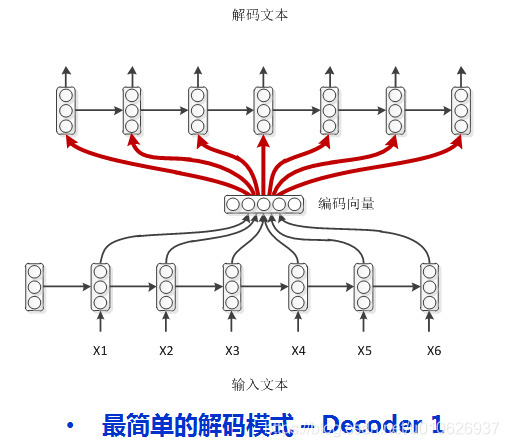
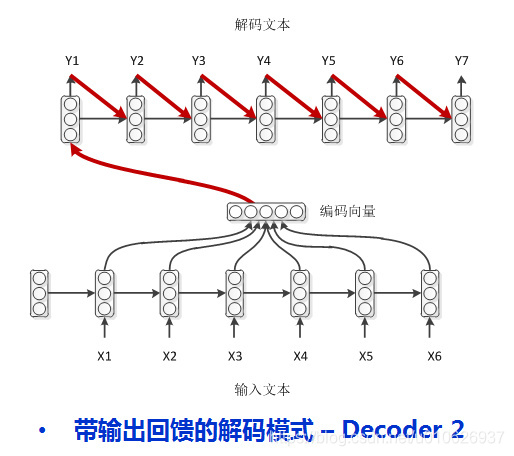
四种Encoder-Decoder模式


参考文献
-
Enoder-Decoder知乎
本文一部分信息来自于这篇博客 -
Encoder-Decoder注意力机制
推荐看一下,更清楚的理解注意力机制是如何加入Encoder-Decoder中的 -
tensorflow seq2seq详解
主要是关于源码中几个重要函数的解释
