之前写过一篇爬取小说的博客,但是单线程爬取速度太慢了,之前爬取一部小说花了700多秒,1秒两章的速度有点让人难以接受。
所以弄了个多线程的爬虫。
这次的思路和之前的不一样,之前是一章一章的爬,每爬一章就写入一章的内容。这次我新增加了一个字典用于存放每章爬取完的内容,最后当每个线程都爬取完之后,再将所有信息写入到文件中。
之所以用字典是因为爬完之后需要排序,字典的排序比较方便
为了便于比较,这次选择的还是之前博客里面相同的小说,不清楚的可以看看那篇博客:
python爬虫实例之小说爬取器
下面就上新鲜出炉代码:
import threading
import time
from bs4 import BeautifulSoup
import codecs
import requests
begin = time.clock()
#多线程类
class myTread(threading.Thread):
def __init__(self,threadID,name,st):
threading.Thread.__init__ (self)
self.threadID = threadID
self.name = name
self.st = st
def run(self):
print('start ',str(self.name))
threadget(self.st)
print('end ',str(self.name))
txtcontent = {} #存储小说所有内容
novellist = {} #存放小说列表
def getnovels(html):
soup = BeautifulSoup(html,'lxml')
list = soup.find('div',id='main').find_all('a')
baseurl = 'http://www.paoshu8.com'
for l in list:
novellist[l.string] = baseurl+str(l['href']).replace('http:','')
#获取页面html源码
def getpage(url):
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
page = requests.get(url).content.decode('utf-8')
return page
chaptername = [] #存放小说章节名字
chapteraddress = [] #存放小说章节地址
#获取小说所有章节以及地址
def getchapter(html):
soup = BeautifulSoup(html,'lxml')
try:
alist = soup.find('div',id='list').find_all('a')
for list in alist:
chaptername.append(list.string)
href = 'http://www.paoshu8.com'+list['href']
chapteraddress.append(href)
return True
except:
print('未找到章节')
return False
#获取章节内容
def getdetail(html):
soup = BeautifulSoup(html,'lxml')
try:
content = ' '
pstring = soup.find('div',id='content').find_all('p')
for p in pstring:
content += p.string
content += '\n '
return content
except:
print('出错')
return '出错'
def threadget(st):
max = len(chaptername)
#print('threadget函数',st,max)
while st < max:
url = str(chapteraddress[st])
html = getpage(url)
content = getdetail(html)
txtcontent[st] = content
print('下载完毕'+chaptername[st])
st += thread_count
url = 'http://www.paoshu8.com/xiaoshuodaquan/' #小说大全网址
html = getpage(url)
getnovels(html) #获取小说名单
name = input('请输入想要下载小说的名字:\n')
if name in novellist:
print('开始下载')
url = str(novellist[name])
html = getpage(url)
getchapter(html)
thread_list = []
thread_count = int(input('请输入需要开的线程数'))
for id in range(thread_count):
thread1 = myTread(id,str(id),id)
thread_list.append(thread1)
for t in thread_list:
t.setDaemon(False)
t.start()
for t in thread_list:
t.join()
print('\n子线程运行完毕')
txtcontent1 = sorted(txtcontent)
file = codecs.open('C:/Users/Lenovo/Desktop/novellist/'+name+'.txt','w','utf-8') #小说存放在本地的地址
chaptercount = len (chaptername)
#写入文件中
for ch in range(chaptercount):
title = '\n 第' + str (ch + 1) + '章 ' + str (chaptername[ch]) + ' \n\n'
content = str(txtcontent[txtcontent1[ch]])
file.write(title+content)
file.close()
end = time.clock()
print('下载完毕,总耗时',end-begin,'秒')
else:
print('未找见该小说')
我开了100个线程用来测试:
速度比单线程提高了很多
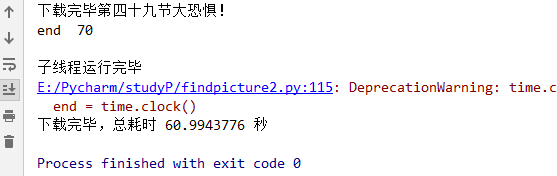
同一时间段的单线程花了1200多秒,而100个线程的速度是他的20多倍。

