前言:隐马尔可夫模型(Hidden Markov Model, HMM)是可用于标注问题(即输入输出都是离散序列的监督学习问题)的统计学模型,描述由隐藏的马尔可夫链随机生成观测序列的过程,属于生成模型。本文首先介绍马尔可夫过程和隐马尔可夫模型的基本概念,然后分别叙述和实现隐马尔可夫模型的概率计算算法、学习算法以及预测算法。
一、马尔可夫过程
马尔可夫过程 (Markov Process),因俄罗斯数学家安德烈 · 马尔可夫而得名,代表数学中具有马尔可夫性质的离散随机过程。该过程中,每个状态的转移只依赖于之前的 n 个状态,这个过程被称为1个 n 阶的模型,其中 n 是影响转移状态的数目。我们称该过程具有马尔可夫性或无后效性。通俗的说,在已经知道过程“现在”的条件下,其“将来”不依赖于“过去”。最简单的马尔科夫过程就是一阶过程,每一个状态的转移只依赖于其之前的那一个状态。注意这和确定性系统不一样,因为这种转移是有概率的,而不是确定性的。时间和状态都是离散的马尔可夫过程就称为马尔可夫链,记为
这个条件概率称为马氏链在时刻
该矩阵有约束条件:
然而,当马尔科夫过程不够强大的时候,我们又该怎么办呢?在某些情况下,马尔科夫过程不足以描述我们希望发现的模式。
例如,一个隐居的人可能不能直观的观察到天气的情况,但是民间传说告诉我们海藻的状态在某种概率上是和天气的情况相关的。在这种情况下我们有两个状态集合,一个可以观察到的状态集合(海藻的状态)和一个隐藏的状态(天气状况)。我们希望能找到一个算法可以根据海藻的状况和马尔科夫假设来预测天气的状况。
一个更现实的例子是语音识别,我们听到的声音是声带、喉咙和一起其他的发音器官共同作用的结果。这些因素相互作用,共同决定了每一个单词的声音,而一个语音识别系统检测的声音(可以观察的状态)是人体内部各种物理变化(隐藏的状态、引申一个人真正想表达的意思)产生的。
某些语音识别设备把内部的发音机制作为一个隐藏的状态序列,把最后的声音看成是一个和隐藏的状态序列十分相似的可以观察到的状态的序列。在这两个例子中,一个非常重要的地方是隐藏状态的数目和可以观察到的状态的数目可能是不一样的。在一个有3种状态的天气系统(sunny、cloudy、rainy)中,也许可以观察到4种潮湿程度的海藻(dry、dryish、damp、soggy)。在语音识别中,一个简单的发言也许只需要80个语素来描述,但是一个内部的发音机制可以产生不到80或者超过80种不同的声音。
在上面的这些情况下, 可以观察到的状态序列和隐藏的状态序列是概率相关的。于是我们可以将这种类型的过程建模为有一个 隐藏的马尔科夫过程和一个与这个隐藏马尔科夫过程概率相关的并且可以观察到的状态集合。这就是本文重点介绍的 隐马尔可夫模型。
二、隐马尔可夫模型的定义
隐马尔可夫模型 (Hidden Markov Model) 是一种统计模型,用来描述一个含有隐含未知参数的马尔可夫过程。其难点是从可观察的参数中确定该过程的隐含参数,然后利用这些参数来作进一步的分析。下图是一个三个状态的隐马尔可夫模型状态转移图,其中x 表示隐含状态,y 表示可观察的输出,a 表示状态转换概率,b 表示输出概率:
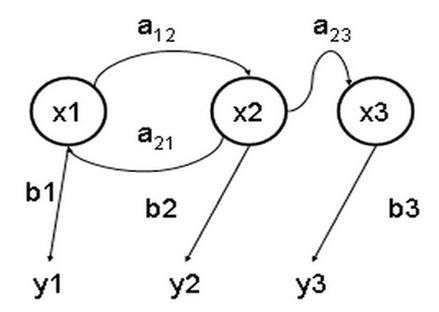
HMM的完整定义如下:
设
其中N是可能的状态数,M是可能的观测数。
设
其中,
是在时刻
B是观测概率矩阵:
其中,
是在时刻
其中,
是时刻
隐马尔可夫模型由初始状态概率向量
从定义知,HMM作了两个基本假设:
(1)齐次马尔可夫性假设,即假设隐藏的马尔可夫链在任意时刻
(2)观测独立性假设,即假设任意时刻的观测只依赖于该时刻的马尔可夫链的状态,与其他观测及状态无关。
三、隐马尔可夫模型的3个基本问题
(1)概率计算问题。给定模型
(2)学习问题。已知观测序列
(3)预测问题,也称为解码(decoding)问题。已知模型
四、概率计算算法
1.直接计算法
直接按照定义得到的计算公式是
但是利用这条公式计算量非常大,概念上可行,实际上不可取。
2.前向算法
前向概率:给定隐马尔可夫模型
算法:
输入:HMM的参数
输出:观测序列概率
(1)初值
(2)递推:对
(3)终止
相关证明可查阅相关论文。下面给出代码实现。
我们考虑盒子和球模型:总共有三个盒子,box1, box2, box3。每个盒子里面装着一定数量的红白两色小球。从这3个盒子中随机抽出一个,并从这个盒子随机抽出一个球,记录颜色后放回。如此进行下去便得到一个球的颜色的观测序列,例如
class HMM:
def __init__(self, pi, A, B):
self.pi = pi
self.A = A
self.B = B
self.M = B.shape[1]
self.N = A.shape[0]
def forward(hmm, obs):
T = len(obs) # 观察序列长度
N = hmm.N # 隐藏层状态数
alpha = matrix(zeros((N,T))) # 前向概率
alpha[:,0] = multiply(hmm.pi[:], hmm.B[:,observation.index(obs[0])]) # 初值
for t in range(1,T): # 递推
for n in range(0,N):
alpha[n,t] = sum(alpha[:,t-1].T * hmm.A[:,n]) * hmm.B[n,observation.index(obs[t])]
prob = sum(alpha[:,T-1]) # 计算观察序列概率
return prob, alpha测试代码如下:
if __name__ == "__main__":
# 状态转移概率矩阵
A = matrix([[0.5,0.2,0.3],
[0.3,0.5,0.2],
[0.2,0.3,0.5]])
# 观测概率矩阵
B = matrix([[0.5,0.5],
[0.4,0.6],
[0.7,0.3]])
pi = matrix([0.2,0.4,0.4]).T
hmm = HMM(pi, A, B)
observation = ['red','write']# 所有可能的观测集合
observed = ['red','write','red']# 观测序列
prob, alpha = forward(hmm, observed)
print('The forword probability is: \n', alpha)
print('The probability of this observed sequence is %f' % prob)计算结果为:
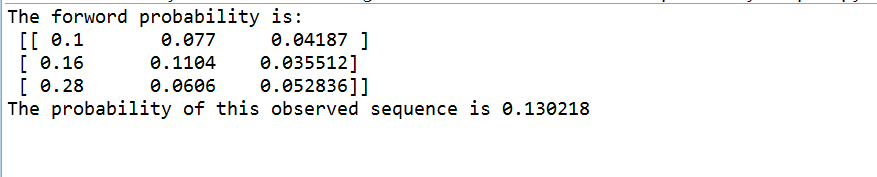
计算结果和手算结果一致。
3.后向算法
后向概率:给定隐马尔可夫模型
算法:
输入:HMM的参数
输出:观测序列概率
(1)
(2)对
(3)
代码实现如下:
def backward(hmm, obs):
T = len(obs) # 观察序列长度
N = hmm.N # 隐藏层状态数
beta = matrix(zeros((N,T))) # 后向概率
beta[:,T-1] = 1
for t in reversed(range(0,T-1)):
for n in range(0,N):
beta[n,t] = sum(multiply(multiply(hmm.A[n,:].T, hmm.B[:,observation.index(obs[t+1])]), beta[:,t+1]))
prob = sum(multiply(multiply(hmm.pi, hmm.B[:,observation.index(obs[0])]), beta[:,0]))
return prob, beta同样的测试输入
prob2, beta = backward(hmm, observed)
print('The backward probability is: \n', beta)
print('The probability of this observed sequence is %f' % prob2)测试结果为:

关于学习算法和预测算法,将在下一篇博文讲述。To be continue……
