文章目录
论文:《Attention is all you need》
论文链接:https://arxiv.org/abs/1706.03762
一、简介
2017年,Google发表论文《Attention is All You Need》,提出经典网络结构Transformer,即提出了一个只基于attention的结构来处理序列模型相关的问题,比如机器翻译,代替了传统的Encoder-Decoder框架必须结合CNN或RNN的固有模式。并在两项机器翻译任务中取得了显著效果。该模型可以高度并行地工作,所以在提升翻译性能的同时训练速度也特别快。该论文一经发出,便引起了业界的广泛关注,同时,Google于2018年发布的划时代模型BERT也是在Transformer架构上发展而来。
Transform模型是与RNN和CNN都完全不同的思路。相比Transformer,RNN/CNN的问题:
- RNN序列化处理效率提不上去。理论上,RNN效果上问题不大。
- CNN感受野小。CNN只考虑卷积核大小区域,核内参数共享,并行/计算效率不是问题,但受限于核的大小,不能考虑整个上下文。
在并行方面,多头attention和CNN一样不依赖于前一时刻的计算,可以很好的并行,优于RNN。在长距离依赖上,由于self-attention是每个词和所有词都要计算attention,所以不管他们中间有多长距离,最大的路径长度也都只是1。可以捕获长距离依赖关系。
二、模型结构
2.1 整体结构
目前大部分比较热门的神经序列转换模型都有Encoder-Decoder结构。Encoder将输入序列 映射到一个连续表示序列 。对于编码得到的 ,Decoder每次解码生成一个符号,直到生成完整的输出序列: 。对于每一步解码,模型都是自回归的,即在生成下一个符号时将先前生成的符号作为附加输入。
和大多数seq2seq模型一样,transformer的结构也是由encoder和decoder组成。通俗结构图如下所示:
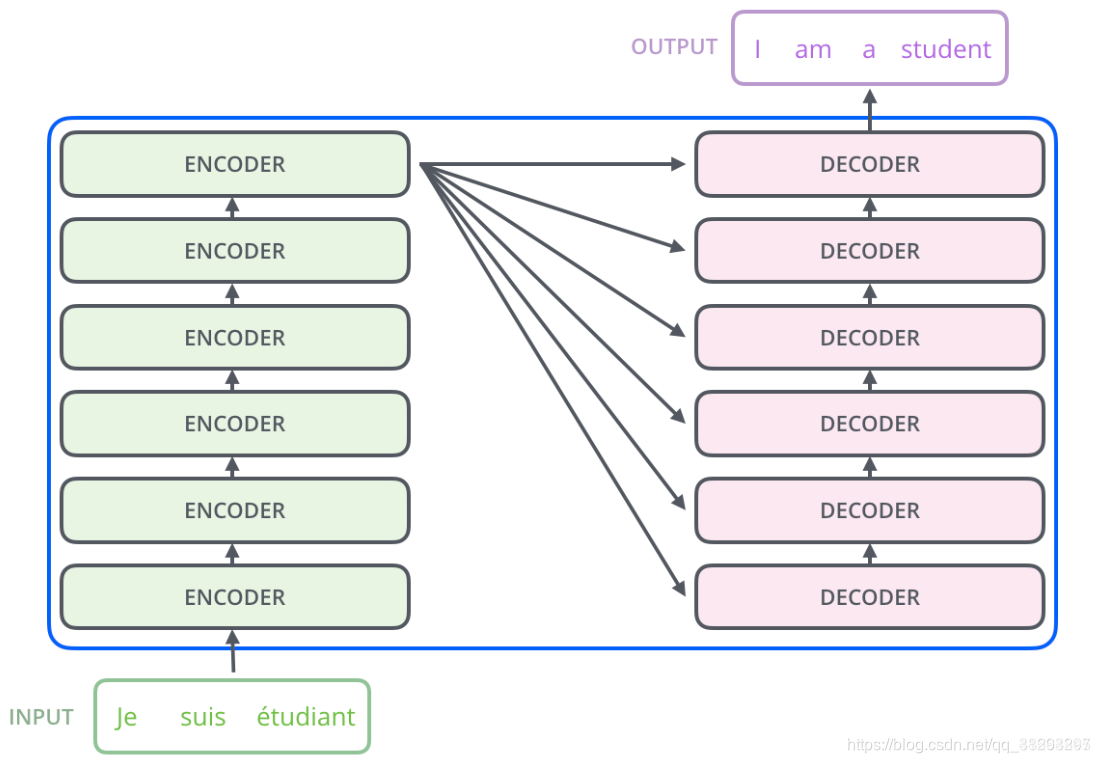
将上述图浓缩一下就是如下图,其中灰色长方形框框就是 Encoder和Decoder都如下所示:
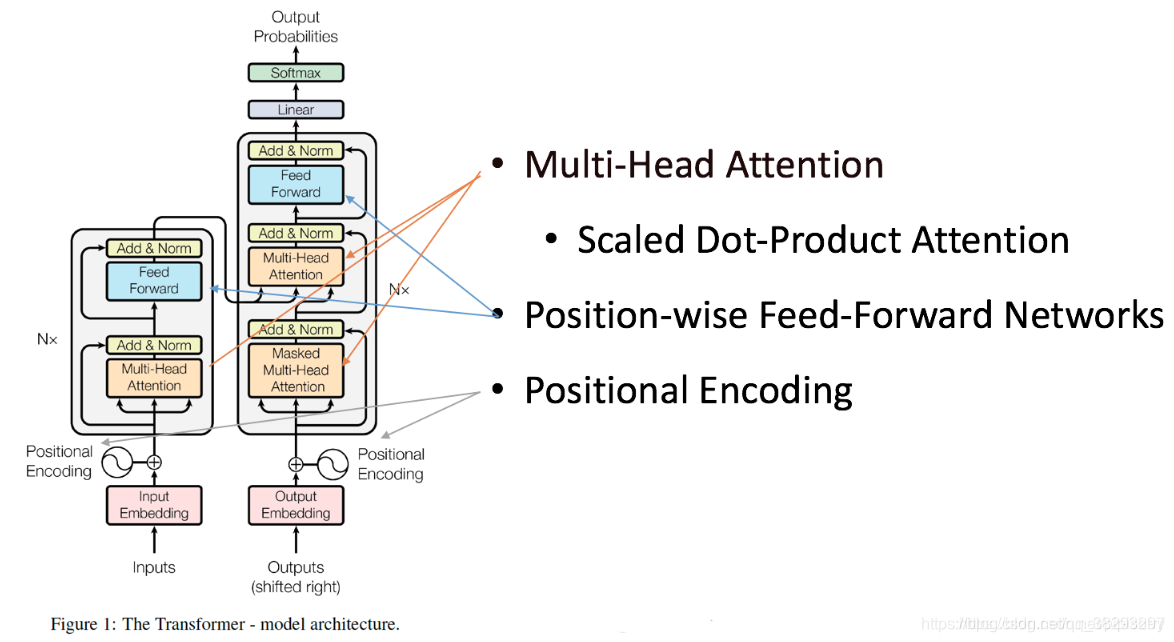
Encoder由
个相同的layer组成,每一个layer就是上图左侧的单元,最左边有个
参数,这里
。每个Layer由两个sub-layer组成,分别是multi-head self-attention mechanism(左图中橙色部分)和fully connected feed-forward network(左图中蓝色部分)。其中每个sub-layer都加了residual connection和normalisation,因此可以将sub-layer的输出表示为:
再通俗一点的图,可能你在其他博客里看到的图,如下所示:
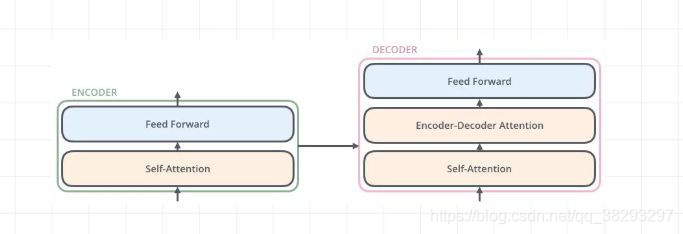
2.2 Transformer的编解码器
模型分为编码器和解码器两个部分。
2.2.1 编码器
- 编码器由6个相同的层堆叠在一起,每一层又有两个支层。第一个支层是一个多头的自注意机制,第二个支层是一个简单的全连接前馈网络。在两个支层外面都添加了一个residual的连接,然后进行了layer nomalization的操作。模型所有的支层以及embedding层的输出维度都是 。
2.2.2 解码器
- 解码器也是堆叠了六个相同的层。不过每层除了编码器中那两个支层,解码器还加入了第三个支层对编码器栈的输出实行“多头”的Attention,如图中所示同样也用了residual以及layer normalization。
我们可以看大Decoder和Encoder的结构差不多, 不同的是Decoder有两个多头attention机制:
- 一个是其自身的mask自注意力机制
- 另一个则是从Encoder到Decoder的注意力机制,而且是Decoder内部先做一次attention后再接收Encoder的输出。
Decoder有N(默认是6)层,每层包括三个sub-layers(自下往上):
- 第一个是Masked multi-head self-attention,也是计算输入的self-attention,但是因为是生成过程,因此在时刻 的时候,大于 的时刻都没有结果,只有小于 的时刻有结果,因此需要做Mask,也就是去上一次的decoder层做输入。
- 第二个sub-layer是对encoder的输入进行attention计算,这里仍然是multi-head的attention结构,只不过输入的分别是encoder的输出和decoder的输入,encoder的输出会做用在每一层decoder中的第二个sub-layer,后面的动图可以帮助理解。
- 第三个sub-layer是全连接网络,与Encoder相同。
这里先明确一下decoder的输入输出和解码过程:
-
输入:encoder的输出 和 对应 位置decoder的输出。所以中间的attention不是self-attention,它的 来自encoder, 来自上一位置decoder的输出。向量 (键向量)和 (值向量)的注意力向量集来自 Encoder。这些向量将被每个解码器用于自身的“编码-解码注意力层”,并作用在Decoder的每一层。
-
解码:这里要特别注意一下,编码可以并行计算,一次性全部encoding出来,但解码不是一次把所有序列解出来的,而是像RNN一样一个一个解出来的,因为要用上一个位置的输入当作attention的query
-
输出:对应输入 的输出词的概率分布
明确了解码过程之后最上面的图就很好懂了,这里主要的不同就是新加的attention多加了一个mask,因为训练时的output都是ground truth,这样可以确保预测
时不会接触到未来的信息,下面是一个详细解析图:

以下动态图,可以体验下,第一个动图只展示了两个Encoder和两个Decoder,正常是各自6个,这里怕读者误解。生成第一个单词“I”。


上面的动图可以看到,Encoders的输出结果值对一个Decoders的输出有影响,也就是对第一个单词“I”有影响,对第二个单词“am”没有什么作用。这个需要继续研究一下
2.3 输入层
编码器和解码器的输入就是利用学习好的embeddings将tokens(一般应该是词或者字符)转化为d维向量。对解码器来说,利用线性变换以及softmax函数将解码的输出转化为一个预测下一个token的概率。
与其他序列转换模型类似,我们使用预学习的Embedding将输入Token序列和输出Token序列转化为 维向量。我们还使用常用的预训练的线性变换和Softmax函数将解码器输出转换为预测下一个Token的概率。
在我们的模型中,我们在两个Embedding层和Pre-softmax线性变换之间共享相同的权重矩阵,类似于这篇文章《Using the Output Embedding to Improve Language Models》。在Embedding层中,我们将这些权重乘以
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model)
2.4 位置向量
由于我们的模型不包含递归和卷积结构,为了使模型能够有效利用序列的顺序特征,我们需要加入序列中各个Token间相对位置或Token在序列中绝对位置的信息。在这里,我们将位置编码添加到编码器和解码器栈底部的输入Embedding。由于位置编码与Embedding具有相同的维度dmodel,因此两者可以直接相加。其实这里还有许多位置编码可供选择,其中包括可更新的和固定不变的。
在此项工作中,我们使用不同频率的正弦和余弦函数:
其中, 表示单词的位置, 代表embedding中的第几维,表示单词的维度。也就是说,位置编码的每个维度都对应于一个正弦曲线,其波长形成从 到 的等比级数。我们之所以选择了这个函数,是因为我们假设它能让模型很容易学会Attend相对位置,因为对于任何固定的偏移量 , 可以表示为 的线性函数。
此外,在编码器和解码器堆栈中,我们在Embedding与位置编码的加和上都使用了Dropout机制。在基本模型上,我们使用 的比率。
即奇数位置用余弦编码,偶数位置用正弦编码,最终得到一个 维的位置向量。位置编码是不参与训练的,而词向量是参与训练的。作者通过实验发现,位置编码参与训练与否对最终的结果并无影响。
我们也尝试了使用预学习的位置Embedding,但是发现这两个版本的结果基本是一样的。我们选择了使用正弦曲线版本的实现,因为使用此版本能让模型能够处理大于训练语料中最大序列长度的序列。
2.5 Attention模型
注意力实际就是加权。
2.5.1 NLP中的注意力
以RNN做机器翻译为例,下面第一张图是没有注意力,第二张图是有注意力的:
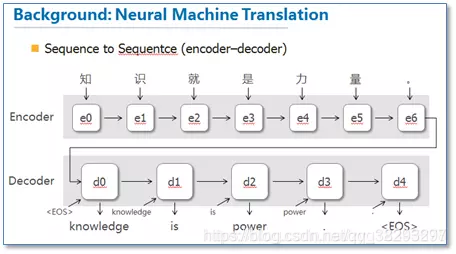

没有注意力机制的机器翻译,翻译下一词时,只考虑源语言经过网络后最终的表达(编码/向量);而注意力机制是要考虑源语言中每(多)个词的表达(编码/向量)。
NLP中有个非常常见的一个三元组概念:Query、Key、Value,其中绝大部分情况Key=Value。在机器翻译中,Query是已经翻译出来的部分,Key和Value是源语言中每个词的表达(编码/向量),没有注意力时直接拿Query就去预测下一个词,注意力机制的计算就是用Query和Key计算出一组权重,赋权到Value上,拿Value去预测下一词。
举个例子,没有注意力的模型:

加上注意力的模型计算过程:

2.5.2 Scaled attention
自注意力模型就是Query“=”Key“=”Value,挖掘一个句子内部的联系。计算句子中每个字之间的互相影响/权重,再加权到句子中每个字的向量上。这个计算就是用了点积。Query、Key、Value都来自同一个输入,但是经过3个不同线性映射(全连接层)得到,所以未必完全相等。
论文中用的attention是基本的点乘的方式,就是多了一个所谓的scale。输入包括维度为 的queries以及keys,还有维度为 的values。计算query和所有keys的点乘,然后每个都除以 (这个操作就是所谓的Scaled)。之后利用一个softmax函数来获取values的权重。
实际操作中,attention函数是在一些列queries上同时进行的,将这些queries并在一起形成一个矩阵 同时keys以及values也并在一起形成了矩阵 以及 。则attention的输出矩阵可以按照下述公式计算:
公式中
是Query向量和Key向量做点积,为了防止点积结果数值过大,做了一个放缩(
是Key向量的长度),结果再经过一个softmax归一化成一个和为1的权重,乘到Value向量上。

attention可视化的效果(这里不同颜色代表attention不同头的结果,颜色越深attention值越大)。可以看到self-attention在这里可以学习到句子内部长距离依赖"making…….more difficult"这个短语。

具体的计算过程:
1.
:Query向量和Key向量做点积

2. scale放缩、softmax归一化、dropout随机失活/置零
3. 将权重矩阵加权到Value上,维度未变化。

2.5.3 多头自注意力
本文结构中的Attention并不是简简单单将一个点乘的attention应用进去。作者发现先对queries,keys以及values进行 次不同的线性映射效果特别好。学习到的线性映射分别映射到 , 以及 维。分别对每一个映射之后的得到的queries,keys以及values进行attention函数的并行操作,生成 维的output值。具体结构和公式如下。

并不是将长度是 的句子整个做点积自注意力,而是将其“拆”成 份,每份长度为 ,然后每份单独去加权注意力再拼接到一起, 分别拆分。
“拆”的过程是一个独立的(different)、可学习的(learned)线性映射。实际实现可以是 个全连接层,每个全连接层输入维度是 ,输出 ;也可以用一个全连接,输入输出均为 ,输出之后再切成h份。
多头能够从不同的表示子空间里学习相关信息。
在两个头和单头的比较中,可以看到单头"its"这个词只能学习到"law"的依赖关系,而两个头"its"不仅学习到了"law"还学习到了"application"依赖关系。
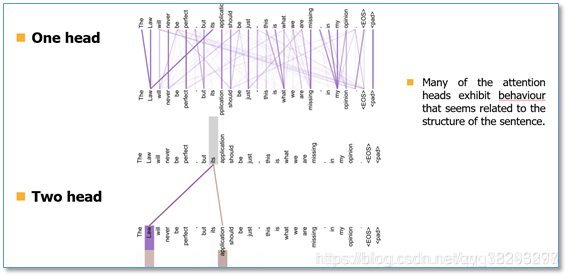
Transformer以三种不同的方式使用了多头attention。
- 在encoder-decoder的attention层,queries来自于之前的decoder层,而keys和values都来自于encoder的输出。这个类似于很多已经提出的seq2seq模型所使用的attention机制。
- 在encoder含有self-attention层。在一个self-attention层中,所有的keys,values以及queries都来自于同一个地方,本例中即encoder之前一层的的输出。
- 类似的,decoder中的self-attention层也是一样。不同的是在scaled点乘attention操作中加了一个mask的操作,这个操作是保证softmax操作之后不会将非法的values连到attention中。
下面我们已直观的方法看一下多头自注意力的计算过程。
我们的工作中使用 个Head并行的Attention,对每一个Head来说有 ,总计算量与完整维度的单个Head的Attention很相近。
- 从每个编码器的输入向量(每个单词的词向量)中生成三个向量。也就是说对于每个单词,我们创造一个查询向量 、一个键向量 和一个值向量 。这三个向量是通过词嵌入与三个权重矩阵后相乘创建的。
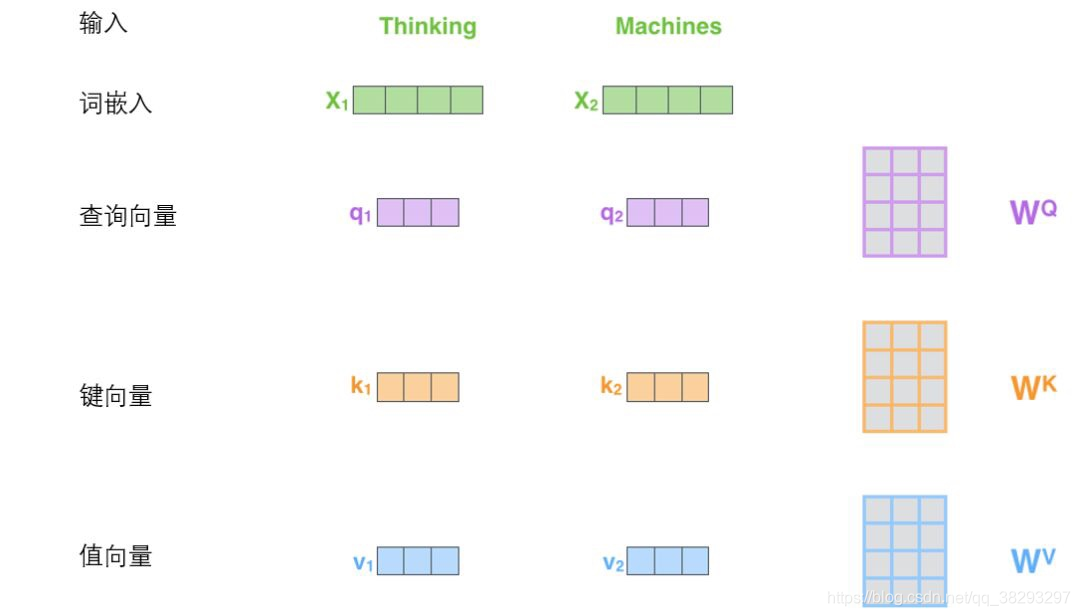
其中:
可以发现这些新向量在维度上比词嵌入向量更低。他们的维度是 ,而词嵌入和编码器的输入/输出向量的维度是 ,但实际上不强求维度更小,这只是一种基于架构上的选择,它可以使多头注意力(multiheaded attention)的大部分计算保持不变。
-
计算得分,假设我们在为这个例子中的第一个词“Thinking”计算自注意力向量,我们需要拿输入句子中的每个单词对“Thinking”打分。这些分数决定了在编码单词“Thinking”的过程中有多重视句子的其它部分。这些分数是通过打分单词(所有输入句子的单词)的键向量 与“Thinking”的查询向量 相点积来计算的。所以如果我们是处理位置最靠前的词的自注意力的话,第一个分数是 和 的点积,第二个分数是 和 的点积。

-
缩放和softmax:是将分数除以 ( 是论文中使用的键向量的维数 的平方根,这会让梯度更稳定。这里也可以使用其它值, 只是默认值),然后通过softmax传递结果。softmax的作用是使所有单词的分数归一化,得到的分数都是正值且和为 。

这个softmax分数决定了每个单词对编码当下位置(“Thinking”)的贡献。显然,已经在这个位置上的单词将获得最高的softmax分数,但有时关注另一个与当前单词相关的单词也会有帮助。 -
将每个值向量 乘以softmax分数(这是为了准备之后将它们求和),不过这里有一个问题,比如输入有 个单词,就有 个 和 个 ,比如第一个单词评分分别是 、 、 ,这里就有 个softmax值,这3个值分别跟对应的 相乘,就有 个向量。这里的直觉是希望关注语义上相关的单词,并弱化不相关的单词(例如,让它们乘以 这样的小数)。
-
对加权值向量求和,然后即得到自注意力层在该位置的输出(在我们的例子中是对于第一个单词),也就是第4步中我们说的3个向量。自注意力的另一种解释就是在编码某个单词时,就是将所有单词的表示(值向量)进行加权求和,而权重是通过该词的表示(键向量)与被编码词表示(查询向量)的点积并通过softmax得到。不过现在仔细想想,求和是各个向量同位置上的求和还是所有向量累加?看下图就是多个向量同位置的元素相加。
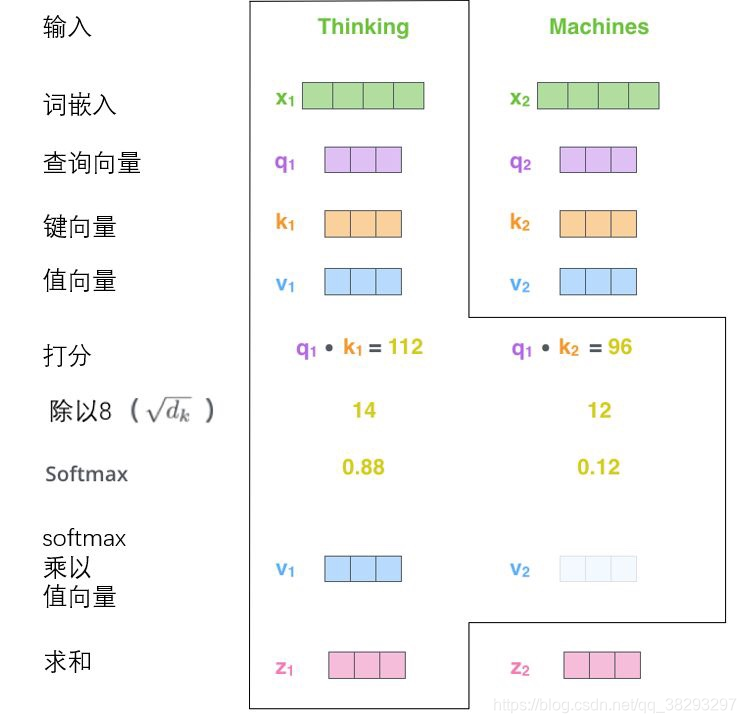
这里还有一个“多头”注意力(“multi-headed” attention)的机制,论文进一步完善了自注意力层,并在两方面提高了注意力层的性能:
- 它扩展了模型专注于不同位置的能力。在上面的例子中,虽然每个编码都在z1中有或多或少的体现,但是它可能被实际的单词本身所支配。如果我们翻译一个句子,比如“The animal didn’t cross the street because it was too tired”,我们会想知道“it”指的是哪个词,这时模型的“多头”注意机制会起到作用。
- 它给出了注意力层的多个“表示子空间”(representation subspaces)。接下来我们将看到,对于“多头”注意机制,我们有多个查询 、键 、值 权重矩阵集(Transformer使用八个注意力头,因此我们对于每个编码器/解码器有八个矩阵集合)。这些集合中的每一个都是随机初始化的,在训练之后,每个集合都被用来将输入词嵌入(或来自较低编码器/解码器的向量)投影到不同的表示子空间中。
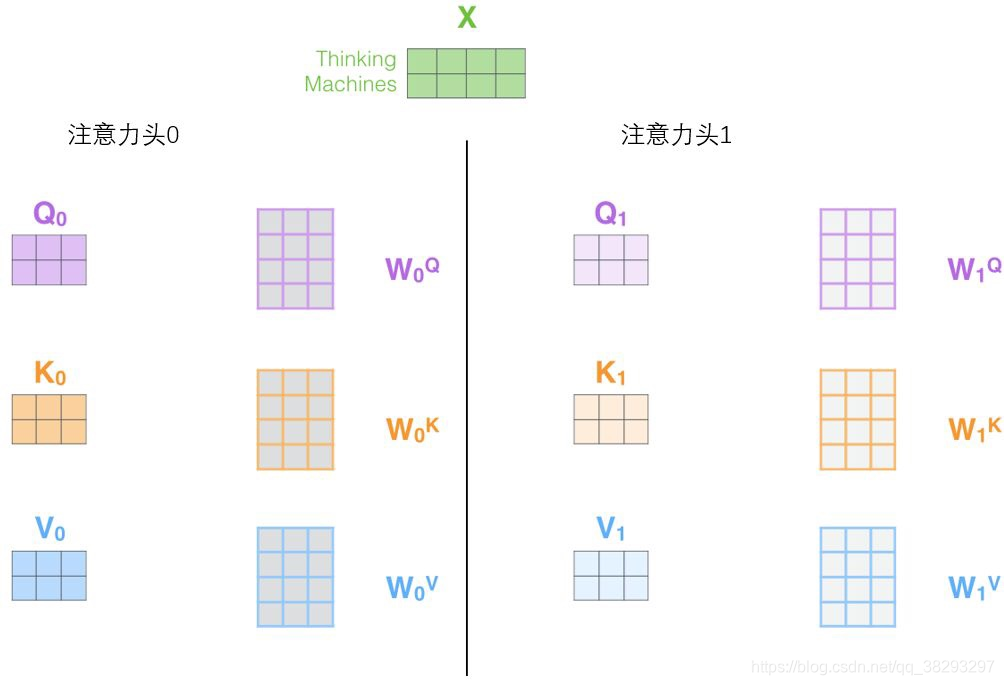
multi-head attention则是通过h个不同的线性变换对
进行投影,最后将不同的attention结果拼接起来:
从
公式中我们可以看出每一个
都独立维护一套
的权值矩阵。假设我们有8个head,那么最终我们可以得到8个head值,然后拼接在一起作为一个向量,与
相乘,作为Multi-head self-attention 层的输出,计算流程如下图所示:
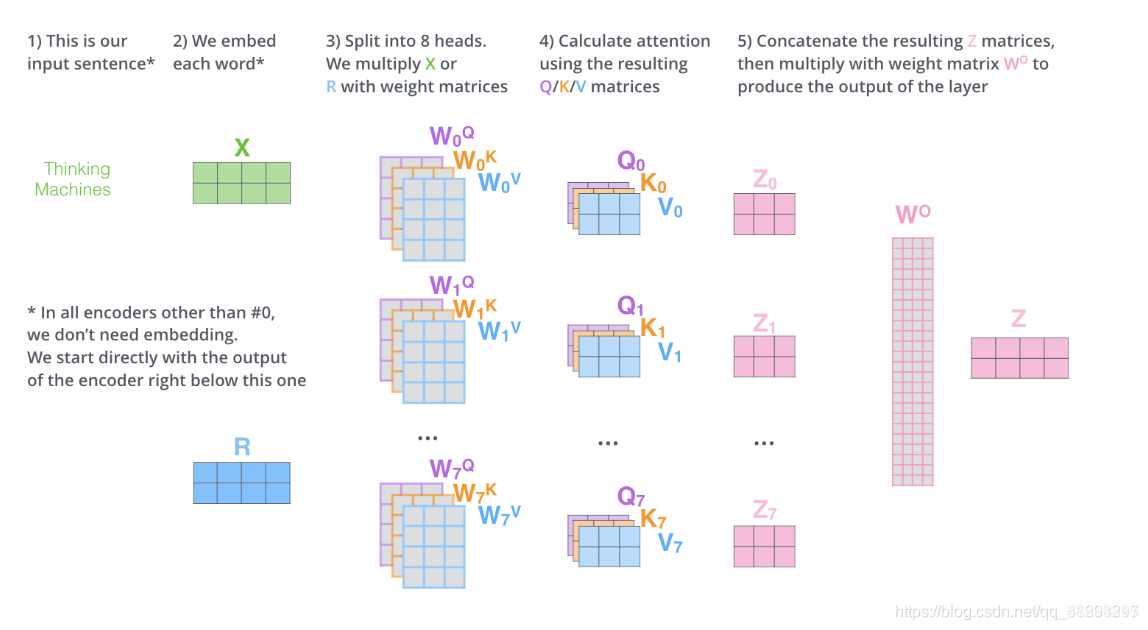
self-attention则是取
维度相同。文章中attention的计算采用了scaled dot-product,即:
于是,图中的 ,其中 表示为 维度。同时,作者同样提到了另一种复杂度相似但计算方法additive attention,在 很小的时候和dot-product结果相似, 大的时候,如果不进行缩放则表现更好,但dot-product的计算速度更快,进行缩放后可减少影响。
2.6 Position-wise feed-forward networks(位置全链接前馈网络)
每层由两个支层,attention层就是其中一个,而attention之后的另一个支层就是一个前馈的网络。Feed Forward Neural Network全连接有两层dense,第一层的激活函数是ReLU(或者其更平滑的版本Gaussian Error Linear Unit-gelu),第二层是一个线性激活函数,如果multi-head输出表示为Z,则FFN可以表示为:公式描述如下:
- Position-wise: 顾名思义,就是对每个position采用相同的操作。
- Feed-Forward Network: 就是最普通的全连接神经网络,这里采用的两层,relu作为激活函数。
Position-wise feed forward network其实就是一个MLP 网络,每个 维向量 在此先由 变为 维的 ,再经过 回归 维。hidden_size变化为: 。之后就是对hidden层进行dropout,最后加一个resnet并normalization(tensor的最后一维,即feature维进行)。Transformer通过对输入的文本不断进行这样的注意力机制层和普通的非线性层交叠来得到最终的文本表达。
2.7 残差连接网络
如下图红色箭头:
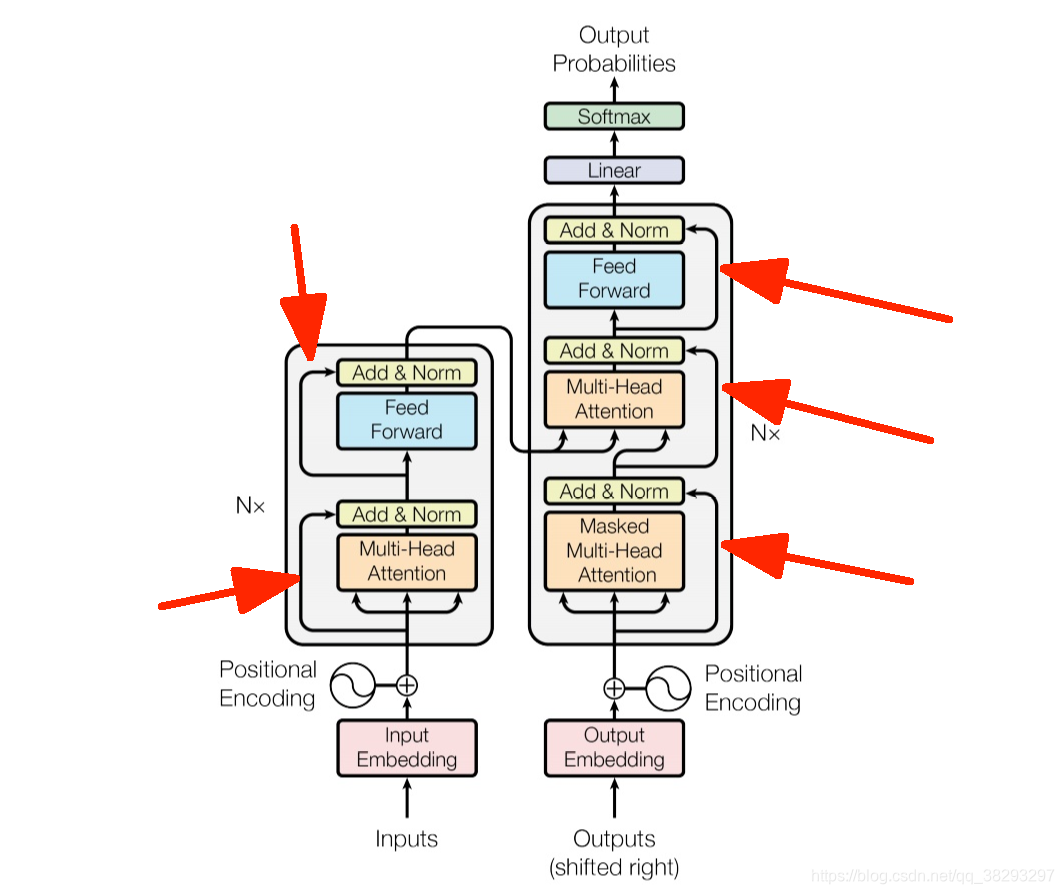
这个红色箭头表明这个可能是一个残差链接,残差连接其实在很多网络机构中都有用到。原理很简单,假设一个输入向量
,经过一个网络结构,得到输出向量
,加上残差连接,相当于在输出向量中加入输入向量,即输出结构变为
,这样做的好处是在对
求偏导时,加入一项常数项
,避免了梯度消失的问题。详细的可以去参考这方面知识-Residual connection。
2.8 Mask
mask的思想非常简单:就是对输入序列中没某些值进行掩盖,使其不起作用。在论文中,做multi-head attention的地方用到了padding mask,在decode输入数据中用到了sequence mask。
- padding mask在我们输入的数据中,因为每句话的长度不同,所以要对较短的数据进行填充补齐长度。而这些填充值并没有什么作用,为了减少填充数据对attention计算的影响,采用padding mask的机制,即在填充物的位置上加上一个趋紧于负无穷的负数,这样经过softmax计算后这些位置的概率会趋近于0。
- sequence mask在上文中我们提到,预测 时刻的输出值 ,应该使用全部的输入序列 ,和 时刻之前的输出序列 进行预测。所以在训练时,应该将 时刻之后的信息全部隐藏掉。所以需要用到sequence mask。实现也很简单,就是用一个上三角矩阵,上三角值均为1,下三角值均为0,对角线值为0,与输入序列相乘,就达到了目的。
三、总结
3.1 模型的优点
模型的整体框架基本介绍完了,其最重要的创新应该就是Self-Attention和Multi-Head Attention的架构。在摒弃传统CNN和RNN的情况下,还能提高表现,降低训练时间。Transformer用于机器翻译任务,表现极好,可并行化,并且大大减少训练时间。并且也给我们开拓了一个思路,在处理问题时可以增加一种结构的选择。Transformer的设计最大的带来性能提升的关键是将任意两个单词的距离是1,这对解决NLP中棘手的长期依赖问题是非常有效的。
其实,主要看数据量,数据量大可能用transformer好一些,小的话还是继续用rnn-based model。
3.2 模型不足
-
粗暴的抛弃RNN和CNN虽然非常炫技,但是它也使模型丧失了捕捉局部特征的能力,RNN + CNN + Transformer的结合可能会带来更好的效果。
-
Transformer失去的位置信息其实在NLP中非常重要,而论文中在特征向量中加入Position Embedding也只是一个权宜之计,并没有改变Transformer结构上的固有缺陷。
