本分类专栏博客系列是学习《深入浅出强化学习原理入门》的学习总结。
书籍链接:链接:https://pan.baidu.com/s/1p0qQ68pzTb7_GK4Brcm4sw 提取码:opjy
文章目录
马尔科夫决策过程
1. 强化学习的基本原理
强化学习过程
智能体在完成某项任务时,⾸先通 过动作A与周围环境进⾏交互,在动作A和环境的作⽤下,智能体会产⽣新 的状态,同时环境会给出⼀个⽴即回报。如此循环下去,智能体与环境不 断地交互从⽽产⽣很多数据。强化学习算法利⽤产⽣的数据修改⾃⾝的动 作策略,再与环境交互,产⽣新的数据,并利⽤新的数据进⼀步改善⾃⾝ 的⾏为,经过数次迭代学习后,智能体能最终学到完成相应任务的最优动 作(最优策略)

强化学习与监督、非监督学习的区别?
在监督学习和⾮监督学习中,数据是静态的、 不需要与环境进⾏交互,⽐如图像识别,只要给出⾜够的差异样本,将数据输⼊深度⽹络中进⾏训练即可。然⽽,强化学习的学习过程是动态的、 不断交互的过程,所需要的数据也是通过与环境不断交互所产⽣的。
强化学习更像是⼈的学习过程: ⼈类通过与周围环境交互,学会了⾛路,奔跑,劳动;⼈类与⼤⾃然,与 宇宙的交互创造了现代⽂明。
深度学习如图像识别和语⾳识别解决 的是感知的问题,强化学习解决的是决策的问题。⼈⼯智能的终极⽬的是 通过感知进⾏智能决策。
2. ⻢尔科夫性
所谓⻢尔科夫性是指系统的下⼀个状态 仅与当前状态 有关,⽽与以前的状态⽆关。
状态 是⻢尔科夫的,当且仅当: 。
3. ⻢尔科夫过程
⻢尔科夫过程的定义:⻢尔科夫过程是⼀个⼆元组
,且满 ⾜:
是有限状态集合,
是状态转移概率。状态转移概率矩阵为:

如图2.2所⽰为⼀个学⽣的7种状态{娱乐,课程1,课程2,课程3,考过,睡觉,论⽂},每种状态之间的转换概率如图所⽰。则该⽣从课程 1 开始⼀天可能的状态序列为:
课1-课2-课3-考过-睡觉
课1-课2-睡觉
以上状态序列称为⻢尔科夫链。当给定状态转移概率时,从某个状态出发存在多条⻢尔科夫链。

4. ⻢尔科夫决策过程
将动作(策略)和回报考虑在内的⻢尔科夫过程称为⻢尔科夫决策过程。
4.1 符号化描述
⻢尔科夫决策过程由元组
描述,其中:
为有限的状态集
为有限的动作集
为状态转移概率
为回报函数
为折扣因⼦,⽤来计算累积回报。
注意,跟⻢尔科夫过程不同的是,⻢尔科夫决策过程的状态转移概率 是包含动作的,即:

在图2.3中, 学⽣有五个状态,状态集为S={s1 ,s2 ,s3 ,s4 ,s5 },动作集为A= {玩,退出,学习,发表,睡觉},在图2.3中⽴即回报⽤R标记。
强化学习的⽬标是给定⼀个⻢尔科夫决策过程,寻找最优策略。所谓 策略是指状态到动作的映射,策略常⽤符号
表⽰,它是指给定状态
时, 动作集上的⼀个分布,即:
策略 在每个状态 指定⼀个动作概 率。如果给出的策略 是确定性的,那么策略 在每个状态 指定⼀个确定的动作。例如其中⼀个学⽣的策略为 ,是指该学⽣在状态 时玩的概率为 ,不玩的概率是 ,显然这个学⽣更喜欢玩。
强化学习是找到最优的策略,这⾥的最优是指得到的总回报最⼤。
4.2 累积回报
当给定⼀个策略
时,我们就可以计算累积回报了。⾸先定义累积回报
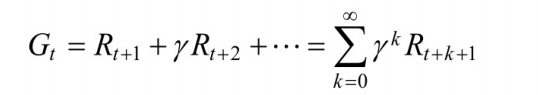
当给定策略
时,假设从状态
出发,学⽣状态序列可能为

此时,在策略 下,利⽤ 那个公式可以计算累积回报 ,此时 有 多个可能值。由于策略 是随机的,因此累积回报也是随机的。为了评价状态 的价值,我们需要定义⼀个确定量来描述状态 的价值,很⾃然的想法是利⽤累积回报来衡量状态 的价值。然⽽,累积回报 是个随机变 量,不是⼀个确定值,因此⽆法描述,但其期望是个确定值,可以作为状态值函数的定义。
4.3 价值函数:状态值函数与状态-⾏为值函数
1. 状态值函数的定义
当智能体采⽤策略
时,累积回报服从⼀个分布,累积回报在状态
处的期望值定义为状态值函数:
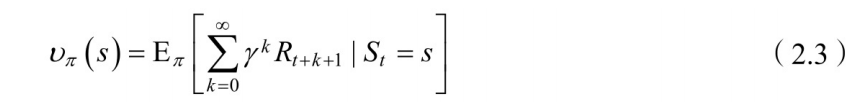
注意:状态值函数是与策略
相对应的,这是因为策略π决定了累积回报
的状态分布。图2.4是与图2.3相对应的状态值函数图。图中空⼼圆圈中的数值为该状 态下的值函数。即:

2. 状态-⾏为值值函数的定义
相应地,状态-⾏为值函数为
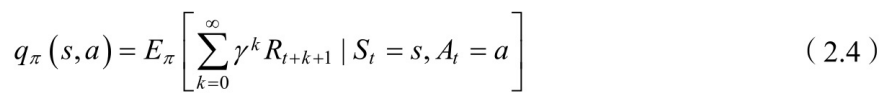
上面分别给出了状态值函数和状态-⾏为值函数的定 义计算式,但在实际真正计算和编程的时候并不会按照定义式编程。接下 来我们会从不同的⽅⾯对定义式进⾏解读。
3. 状态值函数和状态-行为值函数的区别

-
状态值函数V:从状态 开始, 所有的动作 ,都是执行某个策略 的结果,最后求每个动作带来累积奖赏;
-
状态-动作函数Q:从状态 开始,先执行动作 , 然后再执行某个策略 ,再求相应的积累奖赏。
4. 状态值函数的具体推导过程
如下图所示:其中空⼼圆圈表⽰状态,实⼼圆圈表⽰状态-⾏为对。
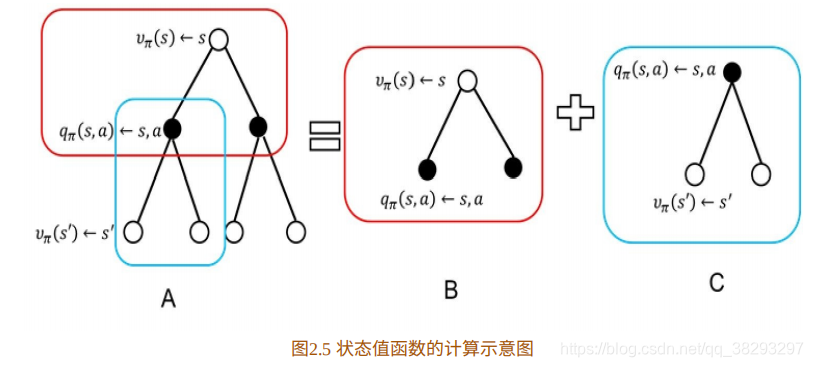
图2.5为值函数的计算分解⽰意图,图2.5B计算公式为
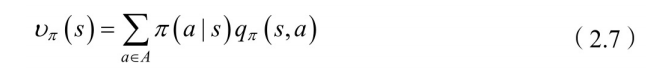
上式中,
表示在状态
时做动作
的概率。
表示状态-行为值函数。我们可以理解为求解离散型随机变量的期望:概率乘以值。
图2.5B给出了状态值函数与状态-⾏为值函数的关系。图2.5C计算状态- ⾏为值函数为
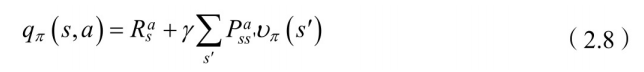
在这里,回顾一下状态行为值函数:从状态
开始,先执行动作
, 然后再执行某个策略
,再求相应的积累奖赏。
我们可以理解为,当前状态的积累奖赏加上转移状态的行为奖赏。
将(2.8)式代⼊(2.7)式可以得到:
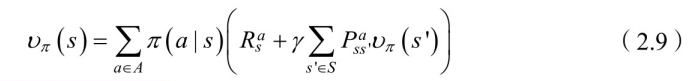
公式(2.9)可以在图2.4中进⾏验证。选择状态
处。由图2.4知道
,由公式(2.9)得
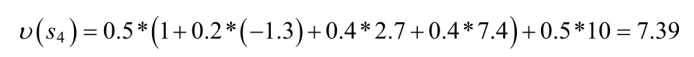
保留⼀位⼩数为7.4。 计算状态值函数的⽬的是为了构建学习算法从数据中得到最优策略。 每个策略对应着⼀个状态值函数,最优策略⾃然对应着最优状态值函数。
4. 状态-行为值函数的具体推导过程
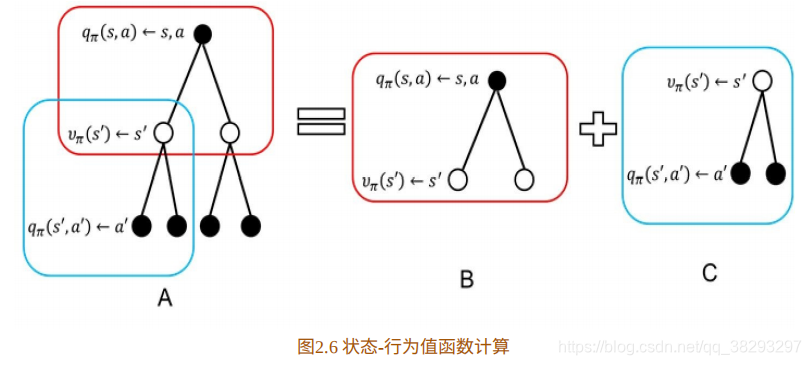
在2.6C中,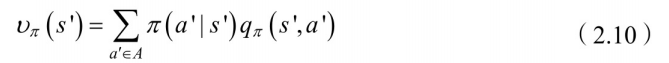
将(2.10)代⼊(2.8)中,得到状态-⾏为值函数:
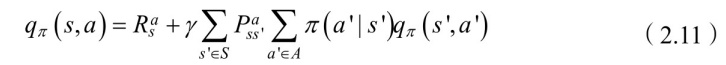
4.4 状态值函数与状态-⾏为值函数的⻉尔曼⽅程
我们先来讲一下什么是贝尔曼方程:贝尔曼方程,又叫动态规划方程,是以Richard Bellman命名的,表示动态规划问题中相邻状态关系的方程。某些决策问题可以按照时间或空间分成多个阶段,每个阶段做出决策从而使整个过程取得效果最优的多阶段决策问题,可以用动态规划方法求解。某一阶段最优决策的问题,通过贝尔曼方程转化为下一阶段最优决策的子问题,从而初始状态的最优决策可以由终状态的最优决策(一般易解)问题逐步迭代求解。存在某种形式的贝尔曼方程,是动态规划方法能得到最优解的必要条件。绝大多数可以用最优控制理论解决的问题,都可以通过构造合适的贝尔曼方程来求解。
首先我们从value function的角度进行理解,value function可以分为两部分:
- 立即回报
- 后继状态的折扣价值函数
由状态值函数的定义式(2.3)可以得到状态值函数的⻉尔曼⽅程:
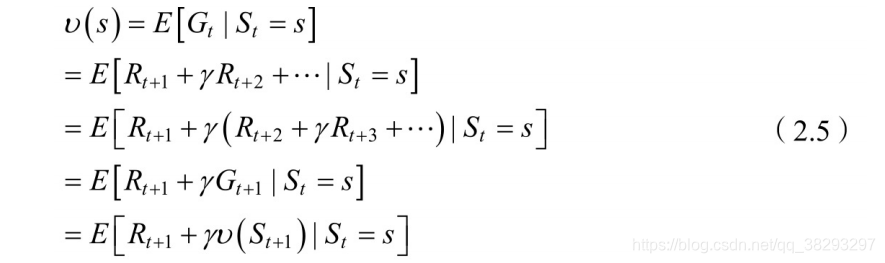
解释一下,
- 从状态 到状态 是不确定的,比如掷骰子游戏,当前点数是1的情况下,下一个状态有可能是1,2,3,4,5,6的任意一种状态可能,所以最外层会有一个期望符号。
- 如果我们跟着一直推下来的话:有疑问的会在导出最后一行时,将 变成了 。其理由是收获的期望等于收获的期望的期望。参考叶强童鞋的理解。
通过方程可以看出 由两部分组成,一是该状态的即时奖励期望,即时奖励期望等于即时奖励,因为根据即时奖励的定义,它与下一个状态无关;这里解释一下为什么会有期望符合,是因为从状态 到下一个状态 可能有多个状态,比如掷骰子,下一个状态可能有1,2,3,4,5,6,从 到下一个状态都是有一定概率,所以会有期望符合。
另一个是下一时刻状态的价值期望,可以根据下一时刻状态的概率分布得到其期望,比如在上面掷骰子例子中,从状态1到下一个状态1,2,3,4,5,6求期望的做法,我们可以直接用概率公式 然后乘以对应下一状态的价值函数即可。
如果用
表示
状态下一时刻任一可能的状态,那么Bellman方程可以写成:
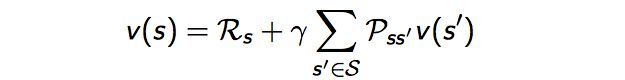
同样我们可以得到状态-动作值函数的⻉尔曼⽅程:
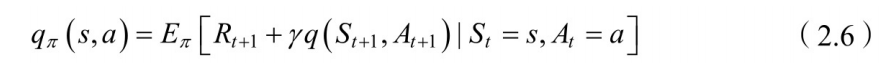
4.5 最优策略的选择
计算状态值函数的⽬的是为了构建学习算法从数据中得到最优策略。 每个策略对应着⼀个状态值函数,最优策略⾃然对应着最优状态值函数。
定义:最优状态值函数 为在所有策略中值最⼤的值函数,即 ,最优状态-⾏为值函数 为在所有策略中最⼤的状态-⾏为值函数,即
我们由(2.9)式和(2.11)式分别得到最优状态值函数和最优状态-⾏动值函数的⻉尔曼最优⽅程:
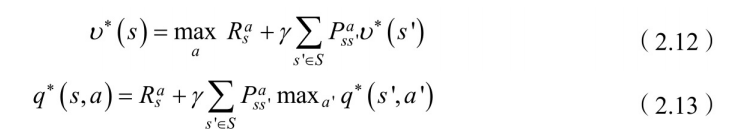
若已知最优状态-动作值函数,最优策略可通过直接最⼤化
来决定。
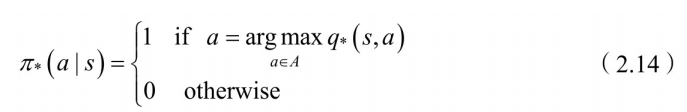
如图2.7所⽰为最优状态值函数⽰意图,图中虚线箭头所⽰的动作为最 优策略。
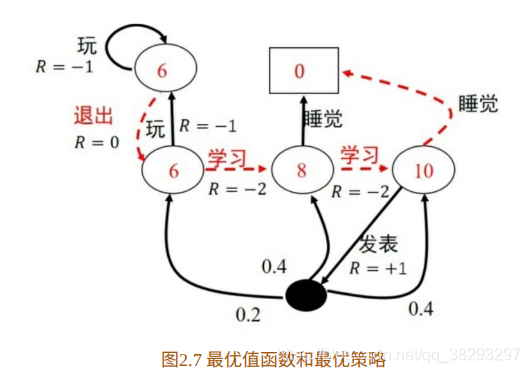
⾄此,我们将强化学习的基本理论即⻢尔科夫决策过程介绍完毕。现 在该对强化学习算法进⾏形式化描述了。
我们定义⼀个离散时间有限范围的折扣⻢尔科夫决策过程:
,
- :状态集
- :动作集
- 是转移概率
- 为⽴即回报函数
- 是初始状 态分布
- :折扣因⼦
- :⽔平范围(其实就是步数)
- :⼀个轨迹序列,即
- 累积回报:
强化学习的⽬标是找到最优策略 ,使得该策略下的累积回报期望最⼤,即:
