源代码:
-
from urllib.parse import urlencode
-
import requests
-
-
base_url = 'https://m.weibo.cn/api/container/getIndex?'
-
-
# 构造headers
-
headers = {
-
'Host': 'm.weibo.cn',
-
# HTTP来源地址(referer,或 HTTP referer)是HTTP表头的一个字段,用来表示从哪儿链接到目前的网页,
-
# 采用的格式是URL。换句话说,借着HTTP来源地址,目前的网页可以检查访客从哪里而来,这也常被用来对付伪造的跨网站请求。
-
'Referer': 'https://m.weibo.cn/u/2830678474',
-
'User-Agent': "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 "
-
"(KHTML, like Gecko, Safari/419.3)Arora/0.3 (Change: 287 c9dfb30)",
-
# 可以利用它,request.getHeader("x-requested-with"); 为 null,则为传统同步请求,为 XMLHttpRequest,则为 Ajax 异步请求。
-
'X-Requested-With': 'XMLHttpRequest'
-
}
-
-
def get_page(page):
-
# 创建请求参数
-
params = {
-
'type': 'uid',
-
'value': '2830678474',
-
'containerid': '1076032830678474',
-
'page': page
-
}
-
url = base_url + urlencode(params)
-
try:
-
response =requests.get(url, headers = headers)
-
if response.status_code == 200:
-
return response.json()
-
except requests.ConnectionError as e:
-
print('Error', e.args)
-
-
-
from pyquery import PyQuery as pq
-
-
def parse_page(json):
-
if json:
-
items = json.get('data').get('cards')
-
for item in items:
-
item = item.get('mblog')
-
# 实际分析过程中发现部分 item 并没有 mblog, 浏览器实际页面也不显示这些item, 所以增加一个判断,去除无效的 item
-
if item:
-
print(item)
-
weibo = {}
-
weibo['id'] = item.get('id')
-
weibo['text'] = pq(item.get('text')).text()
-
weibo['attitudes'] = item.get('attitudes_count')
-
weibo['comments'] = item.get('comments_count')
-
weibo['reposts'] = item.get('reposts_count')
-
yield weibo
-
-
-
from pymongo import MongoClient
-
-
# 建立MongoDB数据库链接
-
client = MongoClient()
-
db = client['weibo']
-
collection = db['weibo']
-
-
def save_to_mongo(result):
-
if collection.insert(result):
-
print('Save to Mongo')
-
-
-
if __name__ == '__main__':
-
for page in range(1, 11):
-
json = get_page(page)
-
results = parse_page(json)
-
for result in results:
-
print(result)
-
save_to_mongo(result)
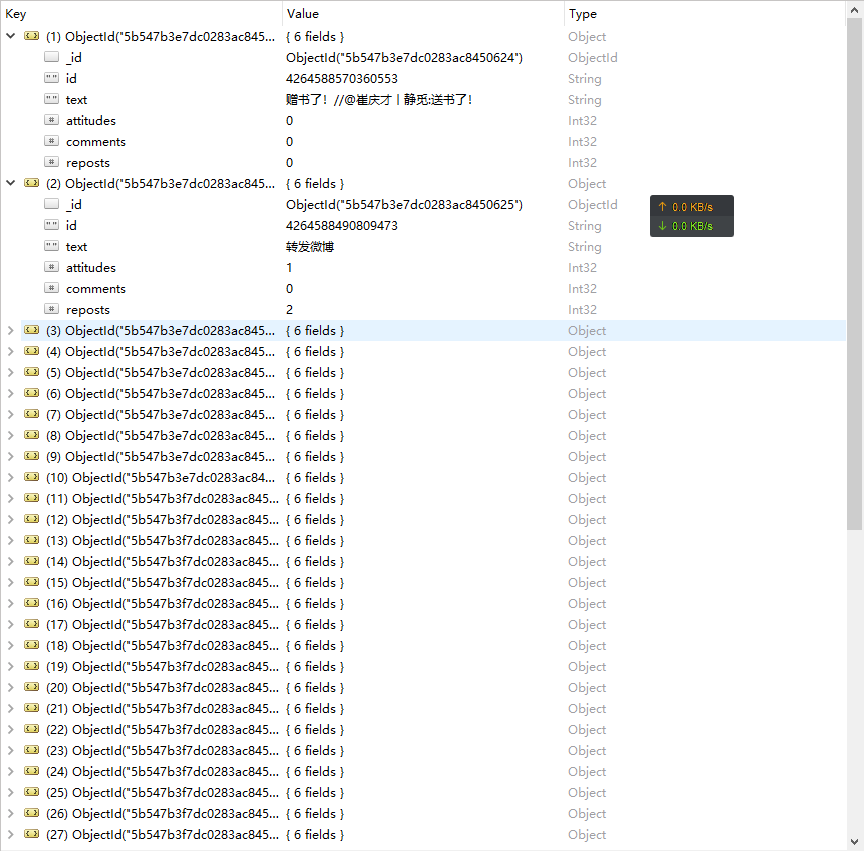
效果: