文章目录
总述
贪心算法是一种常用且便携的方法,且通常情况下是有效的。本文中叙述了两个基础且经典的贪心问题—区间选点问题和区间覆盖问题,希望读后有所理解。
题目一:区间选点问题
原题叙述
数轴上有 n 个闭区间 [a_i, b_i]。取尽量少的点,使得每个区间内都至少有一个点(不同区间内含的点可以是同一个)
INPUT
第一行1个整数N(N<=100)
第2~N+1行,每行两个整数a,b(a,b<=100)
OUTPUT
一个整数,代表选点的数目
输入样例
2
1 5
4 6
输出样例
1
题目重述
题意比较简单,给定N个区间,每个区间都要保证至少存在一个点,每个选中的点可以存在于多个区间中,尝试求出满足这个条件需要挑选多少个这样的点。
解题思路
思路概述
一道经典的贪心算法,贪心算法的最核心问题便是贪心规则,确定了贪心规则问题便能轻松的解决。
本题目中选用的贪心规则是依次选择最小的区间上限,依次考虑,如果区间内没有点就将区间的上限选用,直至全部区间被遍历到。
实际的实现思路大概可以描述为:
首先维持一个map[]数组来存放每个点是否被添加过,初始化所有点为0表示没有被添加过,在访问过程中需要添加进去就置为1。
添加一个全局变量
int number=0
作为添加点计数器,每当加入一个新点,计数器++
中间的贪心流程按照下图执行即可:
如果访问到区间的上限还没找到添加过的点,说明这个区间需要新添加一个点进来,为了选用更少点覆盖较大的区间,选用区间上限作为选点。
完成全部区间的遍历后,计数器的值即为需要选点数。
题目一总结
一道比较简单的贪心算法题目,重点在于贪心策略的两个方面:
1、对区间遍历的顺序—采用按照区间上限升序的策略进行访问,保证不会有区间被忽略,每一个区间都有至少一个点。
2、选点的位置—当一个区间没有添加过点时,添加新点的位置选在区间的上限。在向后遍历的过程中,每次添加区间上限点的策略能够保证添加的点是最少的。
题目一源码
#include<iostream>
#include<stdio.h>
#include<algorithm>
#include<string.h>
using namespace std;
int map[200];
int number=0;
struct time
{
int a;
int b;
bool operator<(const time & ano)const
{
if(b!=ano.b) return b<ano.b;
return a>ano.a;
}
void insert()
{
bool flag=true;
for(int i=a;i<=b;i++)
{
if(map[i]==1)
flag=false;
}
if(flag==true)
{
number++;
map[b]=1;
}
}
};
int main()
{
int all_number=0;
cin>>all_number;
int start=0;
int end=0;
time a[200];
for(int i=0;i<200;i++)
{
map[i]=0;
}
for(int i=0;i<all_number;i++)
{
cin>>start>>end;
a[i].a=start;
a[i].b=end;
}
sort(a,a+all_number);
for(int i=0;i<all_number;i++)
{
a[i].insert();
}
cout<<number<<endl;
return 0;
}
题目二:区间覆盖问题
原题叙述
数轴上有 n (1<=n<=25000)个闭区间 [ai, bi],选择尽量少的区间覆盖一条指定线段 [1, t]( 1<=t<=1,000,000)。
覆盖整点,即(1,2)+(3,4)可以覆盖(1,4)。
不可能办到输出-1
INPUT
第一行:N和T
第二行至N+1行: 每一行一个闭区间。
OUTPUT
选择的区间的数目,不可能办到输出-1
输入样例
3 10
1 7
3 6
6 10
输出样例
2
题目重述
题面同样比较容易理解,使用给出的区间,选择最优的策略,覆盖目标的区间。
但是在求解的过程中有几个数据点需要注意,否则容易在某些点上报错:
1、需要覆盖的区间下限是固定的1,闭区间。
2、要覆盖的目的区间和使用的区间都是闭区间,即所有边界点和中间点都是能够取到的,题目比较良心说明了一种易错情况
2 4
1 2
3 4
题意说明是闭区间且只要求覆盖整点,要求如下图所示:
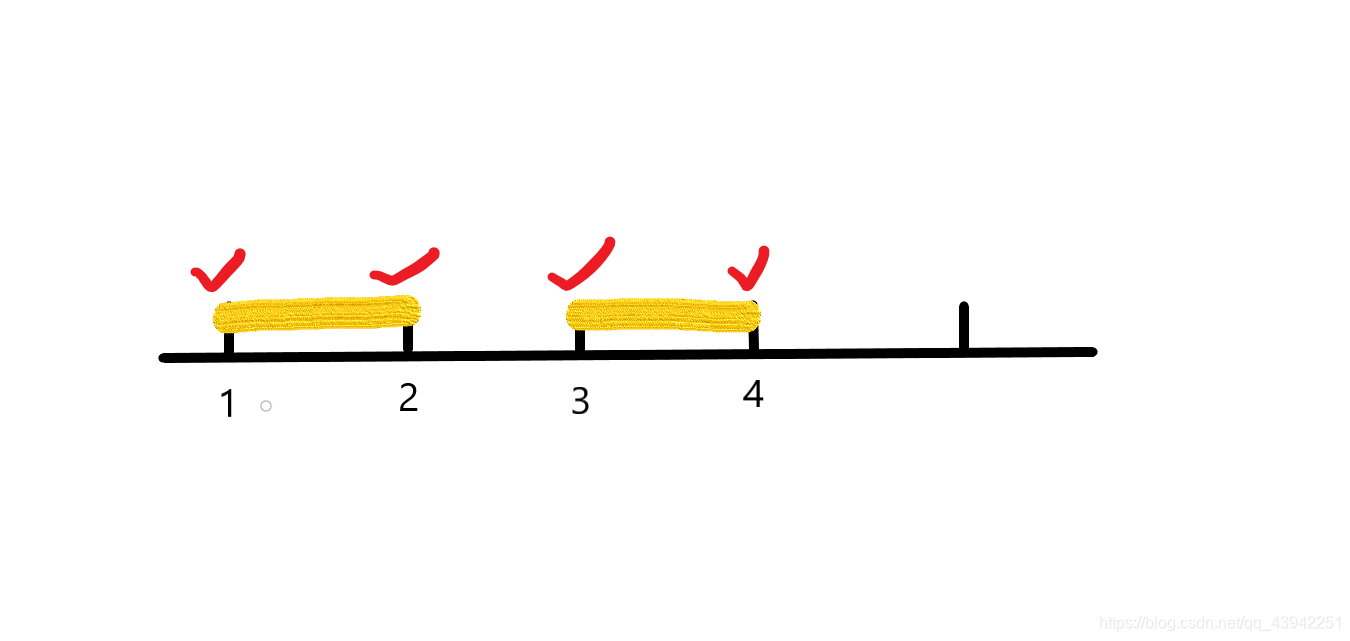 在求解题的过程中要注意边界点的控制和考虑,保证代码符合题意。
在求解题的过程中要注意边界点的控制和考虑,保证代码符合题意。
3、题目中说明了固定下限是1,上限是可以等于1的,那也就是说可能出现要求覆盖[1,1],这种情况下应该输出的是1而不是0。
解题思路
思路概述
了解了题目的一些坑和选择区间的规则,就可以确定贪心规则着手设计代码了。
首先将区间输入的过程中,可以对点进行一定的预处理,方便说明我们将输入的区间记作[a,b],将要覆盖的目标区间记作[A,B]。
如果a>B或者b<B,则输入的点是无用的垃圾数据,直接将其丢弃,这样可以保证在出现大量垃圾数据时,减少运算的时间复杂度。
为了方便所有区间的考虑,对筛选过的数据进行排序,按照区间上限的大小升序排列,保证排序完成后在进行遍历访问时,排在最前面一定是最小的区间上限,能够方便的判断已有区间能否覆盖A点。
考虑到题意,要选择最少的区间个数,引入指标可用长度L来进行贪心算法。
对每个可用的区间[a,b](b>A)
L=b-A
该题目的贪心策略可以确定为:选择所有区间中,可用长度L最大的区间。进行过一次区间选择后,将求解[A,B]覆盖问题转化为求解[b+1,B]的区间覆盖问题。
如果L(MAX)>B-A,说明可选的区间已经能够完全覆盖目标区间,贪心结束,返回一个覆盖成功的标志;
如果找不到L>0的区间,则证明该区间无法被覆盖,贪心结束,返回一个覆盖失败的标志。
分析题意可知每次选择A是一个定值,因此可以将对L的贪心选择转化为对b大小的贪心选择策略。设计代码需要注意的是,区间上下限的转换。
封装后的实现代码如下:
int choose(int begin,int end)
{
int cnt=0;
int j=0;
int flag=0;
for(int i=0;i<room_number;i++)
{
int max_choose=-2e9;
for(j=i;j<room_number && a[j].a<=begin;j++)
{
max_choose=max(max_choose,a[j].b);
}
if(max_choose<begin)
{
cnt=-1;
break;
}
cnt++;
if(max_choose>=end)
{
flag=1;
break;
}
i=j-1;
begin=max_choose+1;
}
if(flag==1)
return cnt;
else
return -1;
}
题目二总结
两道题可以反映出贪心类题目一个明确的特点,题面简单,要解决的问题十分明确,多组数据要进行处理,需要按照一定的策略去进行数据的处理和遍历。
贪心算法从分类上是一种求部分最优解的策略,其求解的重点是贪心策略的选择和证明。选择一个优秀且合理的贪心策略可以在保证低时间复杂度的前提下,简便地解决问题。
题目二改进点
在学习过程中,了解了一种多次预处理方法,大致思路如下:
1、数据预处理,对每个区间进行修剪,只保留需要覆盖区间[A,B]之间的有效部分,如果修剪后不存在有效部分,则将该区间删除
2、对剩余的区间进行贪心,每次选择从A开始上限最大的,有如下几种情况:
- 如果某个区间上限最大值达到B,则证明覆盖结束,返回一个成功的标志。
- 如果剩余的区间个数为0,且A!=B,说明无法完成覆盖,返回一个失败的标志。
- 如果剩余的区间个数>0,但找不到从A开始的区间,则说明无法覆盖,返回一个失败的标志。
- 如果区间个数>0,且能找到A开始的区间,选择上限最大的其上限为b,转化为区间
[b,B]的区间覆盖问题,重复1、2步骤知道找出答案
该做法理论上可行,但尚未找到较好的数据结构来实现,如果你有建议,请慷慨指教。
题目二源码
#include<iostream>
#include<stdio.h>
#include<string.h>
#include<algorithm>
using namespace std;
int room_number=0;
int destination=0;
struct room
{
int a;
int b;
bool operator<(const room& ano)
{
return a<ano.a;
}
}a[25001];
int choose(int begin,int end)
{
int cnt=0;
int j=0;
int flag=0;
for(int i=0;i<room_number;i++)
{
int max_choose=-2e9;
for(j=i;j<room_number && a[j].a<=begin;j++)
{
max_choose=max(max_choose,a[j].b);
}
if(max_choose<begin)
{
cnt=-1;
break;
}
cnt++;
if(max_choose>=end)
{
flag=1;
break;
}
i=j-1;
begin=max_choose+1;
}
if(flag==1)
return cnt;
else
return -1;
}
int main()
{
while(scanf("%d%d",&room_number,&destination)!=EOF)
{
for(int i=0;i<room_number;i++)
{
a[i].a=0;
a[i].b=0;
}
int begin,end=0;
for(int i=0;i<room_number;i++)
{
scanf("%d %d",&begin,&end);
a[i].a=begin;
a[i].b=end;
}
sort(a,a+room_number);
int number=choose(1,destination);
cout<<number<<endl;
}
return 0;
}
