Spark SQL简单介绍 & 为什么需要SQL
切记:Spark不止是单单写SQL那么简单!
为什么需要SQL?
这是对数据统计分析的一种标准
关系型数据库,存储的数据量是有限制的:
[1] 将庞大的数据量使用关系型数据库进行存储,之后进行统计分析 是有一定的难度的
[2] 三大运营商的BI系统,原来都是基于DB2来做的,但是随着量的越来越大,他们肯定要做类似的升级
==> 因此有了云化
说白了,就是将原来的关系型数据库处理,放到大数据平台上进行处理那么,由此引出一个问题
原来基于关系型数据库做的那些东西,所使用的 分析和技巧 是否已经过时了呢?
其实原来,针对关系型数据库肯定是做了很多优化(针对SQL层面)
那么对于这些优化,或是分析的过程 是否是过时了呢?
答案是没有的
==> 原来的那些分析技巧,基于不同的分析维度来统计一系列东西 是没有过时的
只是现在的数据量变大了云化的过程
RDBMS ==> Hadoop(广义上的Hadoop,指整个生态)
最简单的迁移方式就是原来SQL是什么,我们拿过来不改,直接用
==> 如果迁移过程中,要去改SQL
也就意味着所有的业务逻辑,全部需要重新去梳理
那么,这个所带来的工作量是十分可怕的
因此迁移的原则是:
尽可能保留原有的SQL的样子
==> 但是这又不太现实
因为不同的数据库,内置的函数肯定是不一样的
打个比方:
原来在DB2的语法,到Hive里面,不支持了怎么办???
这就需要我们开发大量的UDF去支持原有RDBMS内置的一些函数
因此,SQL还是需要的;在大数据里面,SQL是非常重要的关于SQL在企业中的作用
如果让本地的研发团队,进行如下开发:
RDD: scala python java ==> RDD
Hadoop: MapReduce
是会耗费很大成本的,因为本地的研发团队的研发水平和总部的比起来,肯定是有差距的;哪怕是让总部的来写MR,那也是很费时的;所以相对于,MR或者RDD的表达来说,SQL的表达更容易让人接受与学习大数据层面
到了大数据层面来了,那么原有的存储机制是肯定需要改变的
RDBMS的数据存在哪里呢? ==> 存在文件中 ==> 也就意味着大小是有限制的
从计算层面来说,也是要改的:
MySQL用到了哪些计算引擎
对于大数据来说是分布式的计算框架(比如说MR、Spark)
因此在迁移的过程中,storage + compute 是需要进行改动的,但是对于SQL我们最好是别动
Hive受欢迎(很多公司拿Hive来做数据仓库,大数据界 SQL的一个事实上的标准),所以 说白了SQL简单易用面广
针对page_views.dats使用Hive:
table(tablename + columns)
==> 定义一张表,columns里包含了字段名称、类型等等
select * from xxx where condition
如果使用RDD编程或MR进行编程,就很麻烦了,是使用SQL更加方便
建议:
以后在工作中,能使用DataFrame或是DataSet这种高级的API来操作就使用它们来操作
SQL on Hadoop
Hadoop生态当中,有很多框架是支持SQL的,这些框架统称为SQL on Hadoop
Hive(* 非常重要,用的比较多):
Facebook开源的一套框架
现在支持的引擎:MapReduce/Tez/Spark
原理:SQL ==转换==> 底层的作业
MapReduce转换成MapReduce作业
Tez转换成Tez作业
Spark转换成Spark作业
metastore
梳理出metastore里整个体系内的表的UML图 很重要!!!
理解metastore内的表结构
==> 可以做数据地图
根据这张地图,我们可以知道集群上面所有的数据存储量
比如,哪个业务占了多少存储空间,我们可以使用HDFS shell命令进行查看
但是这样太麻烦,最好的是通过可视化,进行动态的展示,
通过这种方式,我们很明显可以知道最近存储量增加了多少
但是这些信息如何获取呢?
==> 必然是要去metastore里进行获取的
==> 很多SQL on Hadoop都是共用metastore的
我们Hive里创建的表,我们使用Spark SQL也可以访问、Presto也可以访问
因为它们之间是共用一套metastore的
Hive现在的执行速度和原来对比,已经有了很大的提升Impala:
Cloudera公司的;为了解决Hive里面交互式查询,速度比较慢的问题;也可以与Hive共享一套metastore
Impala所推荐的存储格式是parquet
==> 但是我们通常的格式是文本格式,为了更好在Impala里进行使用,是需要一步转换的
我们使用Spark SQL是可以很好的将文本格式转换成parquet格式的
Impala与CM配合起来进行使用的,但是Impala占用资源很高,比较吃MemoryPresto
京东用的很多,有京东的开源版本Shark
早期的,现在已经没有了;Spark SQL的前身 伯克利自己的Drill
这个东西,现在前景不错
我们可以借助Drill的思想,使用Spark实现的一套整合多源数据的项目(思想很重要)Phoenix:
Spark与Phoenix对接,采用外部数据源的方式:val df = sqlContext.read.format( "org.apache.phoenix.spark", Map("table" -> "TABLE1", "zkUrl" -> "phoenix-server:2181") ).loadHive关联HBase去查询,不建议!!!
通过官网解读Spark SQL & 特点
官网:http://spark.apache.org/sql/
官网对于Spark SQL的解读:
Spark SQL is Apache Spark’s module for working with structured data.
Spark的一个子模块,主要功能是用于处理结构化数据
自己的理解:
- not-so-secret truth
- is not about SQL
- about more than SQL
Spark SQL它不仅是SQL,它是超出SQL的
特点:
Integrated
Seamlessly mix SQL queries with Spark programs.
在Spark程序里面,能够和多种复杂的SQL查询无缝对接,Spark SQL能够让我们在Spark程序里面去查询结构化的数据,既可以使用SQL,也可以使用DataFrame APIUniform Data Access
Connect to any data source the same way.
统一的数据访问,能够连接到好多的外部数据源上去 使用类似的方式;DataFrame 和 SQL 都支持一种通用的方式去访问各种数据源,包括Hive, Avro, Parquet, ORC, JSON, and JDBC等等,也可以Join这些数据,跨数据源进行Join。比如:将Hive的数据与Parquet的数据进行JoinHive Integration
Run SQL or HiveQL queries on existing warehouses.
Hive的集成性;能够运行SQL或者Hive SQL的查询 在已经存在的数据仓库上面;这点也是很重要的:比如,已经存在的数据仓库,原来就是使用Hive来实现的,那么现在可以使用Spark SQL来做对接Standard Connectivity
Connect through JDBC or ODBC.
标准的数据连接,举例:
使用Spark SQL,我们把Thrift server起起来之后,
我们后面的BI系统,就可以通过JDBC的方式进行访问
==> 这里会涉及到一个问题:
Thrift server如何做一些优化
否则 咣咣咣的上来 服务不挂才怪 这是重点!!!
Spark SQL介绍
官网网址:http://spark.apache.org/docs/latest/sql-programming-guide.html
the interfaces provided by Spark SQL provide Spark with more information about the structure of both the data and the computation being performed.
提供的接口,能够提供给Spark更多的information
如何理解with more information??
==> 更多体现在schema
有schema了,我们就知道列名、数据类型等
有了数据类型,压缩…等就引出来了
本质上,Spark SQL是使用了额外的信息去做了一些优化的操作,因此必然很多的信息是借助schema过来的
当我们去计算一个结果的时候,类似的执行引擎就会被我们使用,其实就是Catalyst
使用:
整个Spark的一个入口点:SparkSession ==> 所有的东西通过SparkSession来进行获取就行了
Spark SQL里有两个入口:
- SQLContext ==> 不支持Hive
- HiveContext ==> 支持Hive;继承了SQLContext
可以通过下列例子进行学习:examples/src/main/scala/org/apache/spark/examples/sql/SparkSQLExample.scala
Spark SQL 的 cache测试
网址:http://spark.apache.org/docs/latest/sql-programming-guide.html#caching-data-in-memory
Spark SQL可以cache tables,使用基于内存的列式存储方式:
1. spark.catalog.cacheTable(“tableName”)
2. dataFrame.cache()
在SQL中使用cache
spark-sql (default)>cache table emp;
spark-sql (default)>cache table dept;在web ui界面的Storage界面立刻可以看到,与Spark Core对比:
- Core中是lazy机制的
- SQL中是eager机制的
注意,cache之后,去执行上述的join操作: spark-sql (default)>select * from emp e join dept d on e.deptno=d.deptno
通过web ui去对比观察没有cache之前的join操作,input的大小有区别,因为cache之后,从内存中读取了
清除cache
spark-sql (default)>uncache table emp;
spark-sql (default)>uncache table dept;在web ui界面的Storage界面立刻可以看到,没有想关信息了
Hive Tables
网址:http://spark.apache.org/docs/latest/sql-programming-guide.html#hive-tables
Spark SQL也能够支持 直接从Hive里面来读和写数据除了上述那样写SQL,我们还可以使用API方式进行操作:
$>spark-shell --master local[2] --jars ~/software/mysql-connector-java-5.1.27-bin.jar
scala>spark.table("emp").show对官网的解读:
Spark SQL也能够支持 直接从Hive里面来 读和写 数据。因为Hive有非常多的dependencies,而这些dependencies是并没有被包含到我们的默认的Spark distribution这个包里的。也就是说我们编译出来那个包是没有这些的。如果Hive的这些依赖能够被在classpath中被找到,Spark是能够自动得加载进来的。也就说只要我们配置了HIVE_HOME之类的,spark里面是不需要hive的那些东西的。注意,hive的dependencies需要在每个worker节点上都有,这样我们才可以去访问hive的那些序列化和反序列化的东西。配置hive,需要将hive-site.xml、core-site.xml、hdfs-site.xml都丢到spark得到conf目录下来其实在生产上,是不需要core-site.xml、hdfs-site.xml这些配置文件的,因为要跑在yarn上面,已经指定了yarn的目录了,自己已经能找得到。当我们用Hive工作的时候,需要实例化一个SparkSession支持Hive support,这样才能够持久化到Hive的metastore里去,支持Hive的序列化和反序列化,用户如果在生产上没有对Hive进行部署,仍然能够开启Hive support。
提出问题:
生产上如果没有安装Hive,对使用Spark SQL有没有关系??
答案是:是没有关系的
我们真正需要的是hive-site.xml ==> 这个名字也是可以改的
我们只需要能够访问到metasotre就可以了 ==> 说白了就配置一个元数据就够了
如果工作中没有hive-site.xml,那么context会自动创建一个 metastore_db 在当前的目录下面
创建数据仓库指向spark.sql.warehouse.dir
工作中是不会这样用的
val spark = SparkSession
.builder()
.appName("Spark Hive Example")
.config("spark.sql.warehouse.dir", warehouseLocation)
.enableHiveSupport() //如果想访问Hive的话,就必须指定这句话;没有这个拿不到Hive相关的东西的
.getOrCreate()总结:
使用Spark SQL整合Hive,对Hive表的数据进行读和写,是不需要Hive的安装部署,仅仅需要一个metastore的一个配置信息
Spark SQL 架构 & 通过执行计划进行分析
结合下图进行分析:
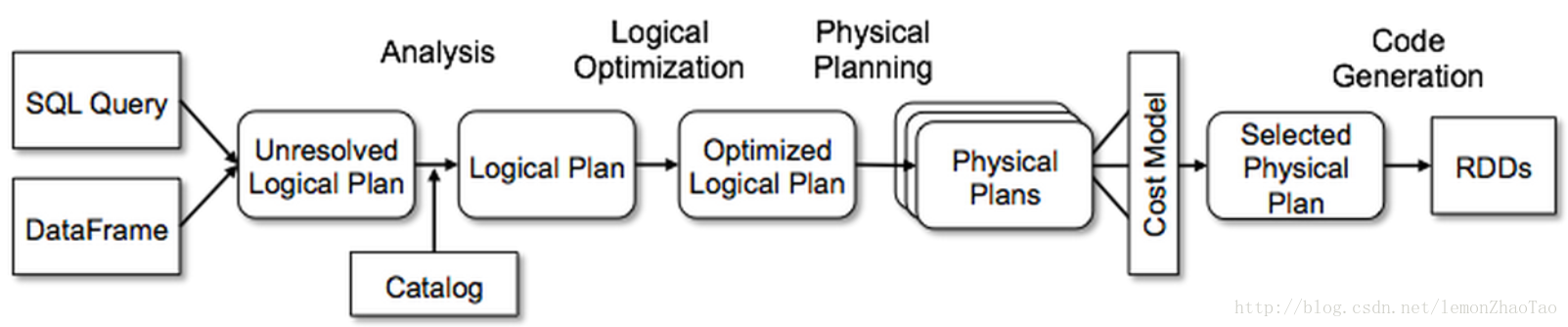
- SQL Query、DataFrame上述的都是Spark SQL外面的东西
- 进来之后,需要解析未解析的逻辑执行计划
比如说:SQL写的对不对,这个字段在表里面有没有,写的表到底有没有
这些东西都在Schema Catalog里面进行获取查询 - 拿到之后变成一个逻辑执行计划
- 之后成为一个物理的执行计划
- 最终基于成本的CBO的模式,给它选择出来就行了
通过执行计划分析:
$>spark-sql --master local[2] --jars ~/software/mysql-connector-java-5.1.27-bin.jar
spark-sql (default)>create table aa(key string, value string); //创建一张表
// 通过执行计划查看Spark SQL的执行过程 自己和自己join
spark-sql (default)>explain extended select a.key*(4+5),b.value from aa a join aa b on a.key=b.key and a.key>10;
解析逻辑执行计划 对应图中未解析的逻辑查询计划
== Parsed Logical Plan ==
'Project [unresolvedalias(('a.key * (4 + 5)), None), 'b.value] // Project是投影,输出的2个字段
+- 'Join Inner, (('a.key = 'b.key) && ('a.key > 10)) // InnerJoin 这里是我们的条件
:- 'SubqueryAlias a
: +- 'UnresolvedRelation `aa` // 因为有个join 有两张表 未解析出来的表aa 现在只是第一步 只知道aa是个字符串
+- 'SubqueryAlias b
+- 'UnresolvedRelation `aa` // 因为有个join 有两张表 未解析出来的表aa 现在只是第一步 只知道aa是个字符串
分析逻辑执行计划 对应图中 经过Catalog的Analyze之后形成了逻辑查询计划
== Analyzed Logical Plan ==
(key * (4 + 5)): int, value: string
Project [(key#37 * (4 + 5)) AS (key * (4 + 5))#41, value#40] // 最终需要的字段
+- Join Inner, ((key#37 = key#39) && (key#37 > 10)) // 解析出来aa之后,进行Iner Join
:- SubqueryAlias a
: +- SubqueryAlias aa // 现在已经知道aa这张表从哪里来,采用的是什么序列化和反序列化,取的别名是什么 已经解析出来aa
: +- CatalogRelation `default`.`aa`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [key#37, value#38]
+- SubqueryAlias b
+- SubqueryAlias aa // 现在已经知道aa这张表从哪里来,采用的是什么序列化和反序列化,取的别名是什么 已经解析出来aa
+- CatalogRelation `default`.`aa`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [key#39, value#40]
// 优化 对应图中 优化的逻辑查询计划
== Optimized Logical Plan ==
Project [(key#37 * 9) AS (key * (4 + 5))#41, value#40]
+- Join Inner, (key#37 = key#39)
:- Project [key#37]
: +- Filter (isnotnull(key#37) && (key#37 > 10)) // 上述一步,是把aa这个表的数据全部拿出来了;
// 优化过程中先做了个谓词下压,把条件先给压下来了
// 压下来之后,再做Join,它的性能肯定是要好一些的
: +- CatalogRelation `default`.`aa`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [key#37, value#38]
+- Filter ((key#39 > 10) && isnotnull(key#39))
+- CatalogRelation `default`.`aa`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [key#39, value#40]
// 物理执行计划
// InnerJoin转换为SortMergeJoin了 这里 这一步先不用管这么多,了解即可
== Physical Plan ==
*Project [(key#37 * 9) AS (key * (4 + 5))#41, value#40]
+- *SortMergeJoin [key#37], [key#39], Inner
:- *Sort [key#37 ASC NULLS FIRST], false, 0
: +- Exchange hashpartitioning(key#37, 200)
: +- *Filter (isnotnull(key#37) && (key#37 > 10))
: +- HiveTableScan [key#37], CatalogRelation `default`.`aa`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [key#37, value#38]
+- *Sort [key#39 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(key#39, 200)
+- *Filter ((key#39 > 10) && isnotnull(key#39))
+- HiveTableScan [key#39, value#40], CatalogRelation `default`.`aa`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [key#39, value#40]
Time taken: 1.218 seconds, Fetched 1 row(s)普通的字段到了Schema Catalog之后,就知道是从哪个表哪个库里出来的去取了;取出来之后,优化一下,该谓词下压的谓词下压,该过滤的过滤;之后到了物理执行计划,再做MapJoin、broadcastjoin、SortMergeJoin等等的优化。这个过程与Hive没有本质的区别