1. Kylin的基本介绍
Kylin是一种MOLAP(Multidimensional OLAP),基于多维数据集,需要预计算。另一种OLAP是ROLAP(Relational OLAP),基于关系型数据库,不需要预计算,例如Presto
一个多维数据集称为一个OLAP Cube,例如城市、品类、月份这三个维度,形成共七种组合的数据集。Cuboid是其中的一个组合数据集,例如城市、品类组合形成的数据集
2. Kylin的特点
- 可伸缩性
- 支持标准SQL接口
- 支持标准数据库协议,可以集成各种BI工具。ODBC可以与Tableau、Excel、PowerBI 等工具集成。JDBC与Saiku、BIRT等Java工具集成。RestAPI可以与JavaScript、Web网页集成
- 推出了MDX工具,可以以Kylin为数据源,对接多种数据分析工具,比如Excel、Tableau等。这样Excel就能通过MDX查询Kylin的数据了
- Kylin还开发了Zepplin的插件,可以使用Zepplin来访问Kylin服务
- 单节点Kylin可实现每秒70个查询,还可结合Zookeeper搭建Kylin集群
3. Kylin的架构
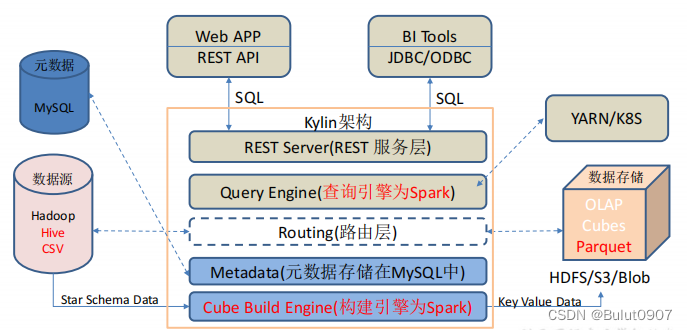
-
REST Server
是应用程序的入口点,为应用程序提供查询、获取结果、触发cube构建任务、获取元数据以及获取用户权限等 -
查询引擎(Query Engine)
当cube准备就绪后,查询引擎就能够获取并解析用户查询。它随后与系统中的其它组件进行交互,从而向用户返回对应的结果 -
路由层(Routing)
Routing路由层先从数据储存层的Cubes进行查询,如果查询不到,则从数据源层Hive(查询引擎是Spark)进行查询 -
数据储存(Cubes)
把所有的数据按照文件存储,每个Segment会存在一个对应的HDFS的目录,所有的构建、查询都是直接通过读写文件的方式。对于小查询的性能会有一定损失,但对于复杂查询带来的提升是更可观的的
-
元数据管理工具(Metadata)
用于Kylin的所有元数据进行管理,包括cube元数据 -
任务构建引擎(Cube Build Engine)
构建引擎最终得到的数据存放到Parquet文件当中。构建过程分为两大步,第一步进行资源探测,收集构建Cube所需要的元数据信息。第二步使用Spark引擎去计算和构建