要点
Spark SQL/DataFrame如何理解?
如何使用spark SQL编写统计代码?
如何查看spark任务监控过程?
Spark SQL程序开发需要注意哪些内容?
1、Spark SQL/DataFrame如何理解
Spark SQL 是 Spark 生态系统里用于处理结构化大数据的模块,该模块里最重要的概念就是 DataFrame, 相信熟悉 R 语言的工程师对此并不陌生。Spark 的 DataFrame 是基于早期版本中的 SchemaRDD,所以很自然的使用分布式大数据处理的场景。Spark DataFrame 以 RDD 为基础,但是带有 Schema 信息,它类似于传统数据库中的二维表格。
Spark SQL 模块目前支持将多种外部数据源的数据转化为 DataFrame,并像操作 RDD 或者将其注册为临时表的方式处理和分析这些数据。当前支持的数据源有:
Json
文本文件
RDD
关系数据库
Hive
Parquet一旦将 DataFrame 注册成临时表,我们就可以使用类 SQL 的方式操作这些数据,我们将在下文的案例中详细向读者展示如何使用 Spark SQL/DataFrame 提供的 API 完成数据读取,临时表注册,统计分析等步骤。
2、如何使用spark SQL编写统计代码
案例介绍与编程实现
案例一:
a.案例描述与分析
本案例中,我们将使用 Spark SQL 分析包含 5 亿条人口信息的结构化数据,数据存储在文本文件上,总大小为 705m。文件总共包含三列,第一列是 ID,第二列是性别信息 (F -> 女,M -> 男),第三列是人口的身高信息,单位是 cm。实际上这个文件与我们在本系列文章第一篇中的案例三使用的格式是一致的,读者可以参考相关章节,并使用提供的测试数据生成程序,生成 5 千万条数据,用于本案例中。为了便于读者理解,本案例依然把用于分析的文本文件的内容片段贴出来,具体格式如下。
文件大小:

文件格式内容:
上传Hdfs:
本例中,我们的统计任务如下:
用 SQL 语句的方式统计男性中身高超过 180cm 的人数。
用 SQL 语句的方式统计女性中身高超过 170cm 的人数。
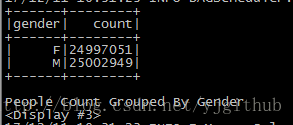
对人群按照性别分组并统计男女人数。
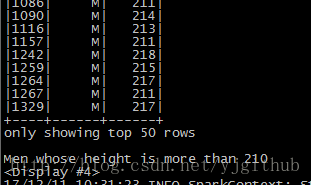
用类 RDD 转换的方式对 DataFrame 操作来统计并打印身高大于 210cm 的前 50 名男性。
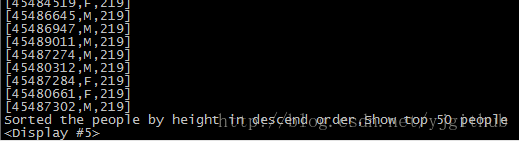
对所有人按身高进行排序并打印前 50 名的信息。
统计男性的平均身高。
统计女性身高的最大值。
b.编码实现
b1.数据制造
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.util.Random;
/**
* args[0] : 文件路径
* args[1] : 生成数据量条数
* Created by Administrator on 2017/12/8.
*/
public class samplePeopleInfo {
public static void main(String[] args) {
if (args.length < 2) {
System.out.println("file path or num is null");
System.exit(1);
}
String filePath = args[0];
int peopleNum = Integer.valueOf(args[1]);
File file = new File(filePath);
FileWriter fw = null;
BufferedWriter writer = null;
Random rand = new Random();
int age = 0;
int se = 0;
String sex = null;
try {
fw = new FileWriter(file);
writer = new BufferedWriter(fw);
for(int i = 1;i<= peopleNum ;i++){
age = rand.nextInt(100)+120;
se = rand.nextInt(2);
if(se!=0){
sex = "F";
}else {
sex = "M";
}
writer.write(i+","+sex+","+age);
writer.newLine();//换行
writer.flush();
}
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
writer.close();
fw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
b2:业务代码编写
package com
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SQLContext}
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
/**
* args(0) : HDFS数据文件地址
* Created by Administrator on 2017/12/8.
* //致命的缺点,可以从sparkUI看到,每个sql都是从新加载数据,性能缓慢
*/
object PeopleDataStatistics {
private val schemaString = "id,gender,height"
def main(args: Array[String]): Unit = {
if (args.length < 1) {
println("Usage:PeopleDataStatistics2 filePath")
System.exit(1)
}
val conf = new SparkConf().setAppName("Spark Analysis:PeopleDataStatistics")
val sc = new SparkContext(conf)
val peopleDateRdd = sc.textFile(args(0).trim);
val sqlCtx = new SQLContext(sc)
val schemaArr = schemaString.split(",")
val schema = StructType(schemaArr.map(fieldName => StructField(fieldName,StringType,true)))
val rowRdd : RDD[Row] = peopleDateRdd
.map(_.split(","))
.map(eachRow => Row(eachRow(0),eachRow(1),eachRow(2)))
val peopleDF = sqlCtx.createDataFrame(rowRdd,schema)
//注意DF缓存在内存中,会根据数据量节省很多时间
peopleDF.persist(StorageLevel.MEMORY_ONLY_SER)
peopleDF.registerTempTable("people")
//get the male people whose height is more than 180
val higherMale180 = sqlCtx.sql("" +
"select *" +
" from people" +
" where height > 180 and gender = 'F'")
println("Men whose height are more than 180: " + higherMale180.count())
println("<Display #1>")
//get the female people whose height is more than 170
val higherMale170 = sqlCtx.sql("" +
"select *" +
" from people" +
" where height > 170 and gender = 'M'")
println("female whose height are more than 170: " + higherMale170.count())//job 1
println("<Display #2>")
//Grouped the people by gender and count the number
peopleDF.groupBy(peopleDF("gender")).count().show()
println("People Count Grouped By Gender")
println("<Display #3>")
//count and print the first 50 men with a height greater than 210cm
peopleDF.filter(peopleDF("gender").equalTo("M")).filter(peopleDF("height") > 210).show(50)
println("Men whose height is more than 210")
println("<Display #4>")
//To sort all people by height and print the top 50
peopleDF.sort(peopleDF("height").desc).take(50).foreach { println }
println("Sorted the people by height in descend order,Show top 50 people")
println("<Display #5>")
//The average height of a man was counted
peopleDF.filter(peopleDF("gender").equalTo("M")).agg(Map("height" -> "avg")).show()
println("The Average height for Men")
println("<Display #6>")
//The Max height of a women was counted
peopleDF.filter(peopleDF("gender").equalTo("F")).agg("height" -> "max").show()
println("The Max height for Women:")
println("<Display #7>")
//......
println("All the statistics actions are finished on structured People data.")
}
}
c.提交并运行
编码完成后,把项目打成 jar 包,在这里,我们将源码打成名为 DataDemo.jar
/opt/cloudera/parcels/CDH/bin/spark-submit \
--class com.PeopleDataStatistics \
--master spark://namenode1:7077 \
--driver-memory 8g \
--executor-memory 2g \
--total-executor-cores 12 \
/var/lib/flume-ng/cyj/DataDemo.jar hdfs://172.20.1.102:8020/user/flume/Test/samplePeopleInfomin.txtd.监控执行过程
在提交后,我们可以在 Spark web console(http://:8080) 中监控程序执行过程。下面我们将分别向读者展示如何监控程序产生的 Jobs,Stages,以及 D 可视化的查看 DAG 信息。
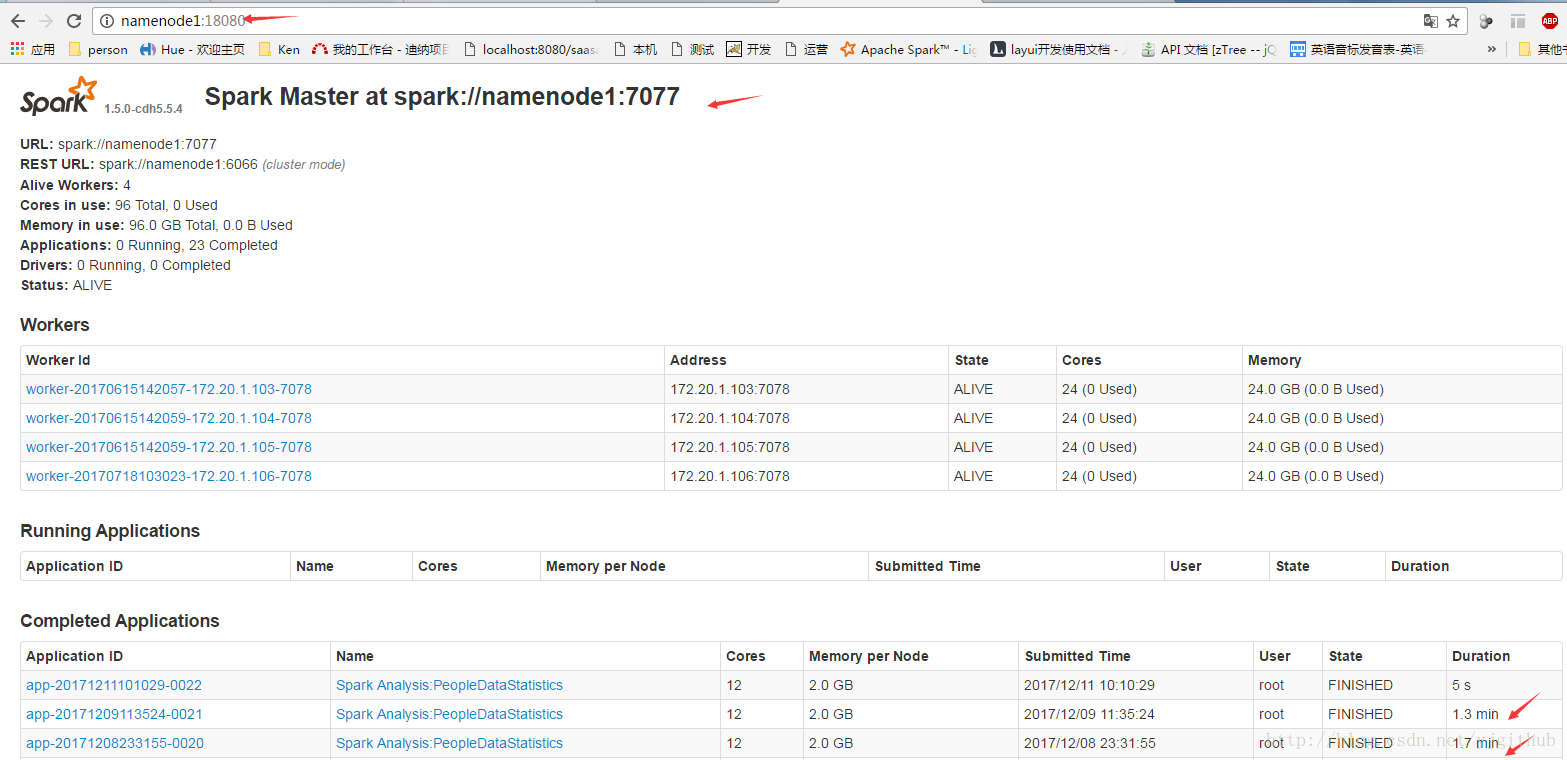
ps: 这里我有两个分析,ID-0021 / ID 0020
ID-0021 : 将数据存内存中 (peopleDF.persist(StorageLevel.MEMORY_ONLY_SER))
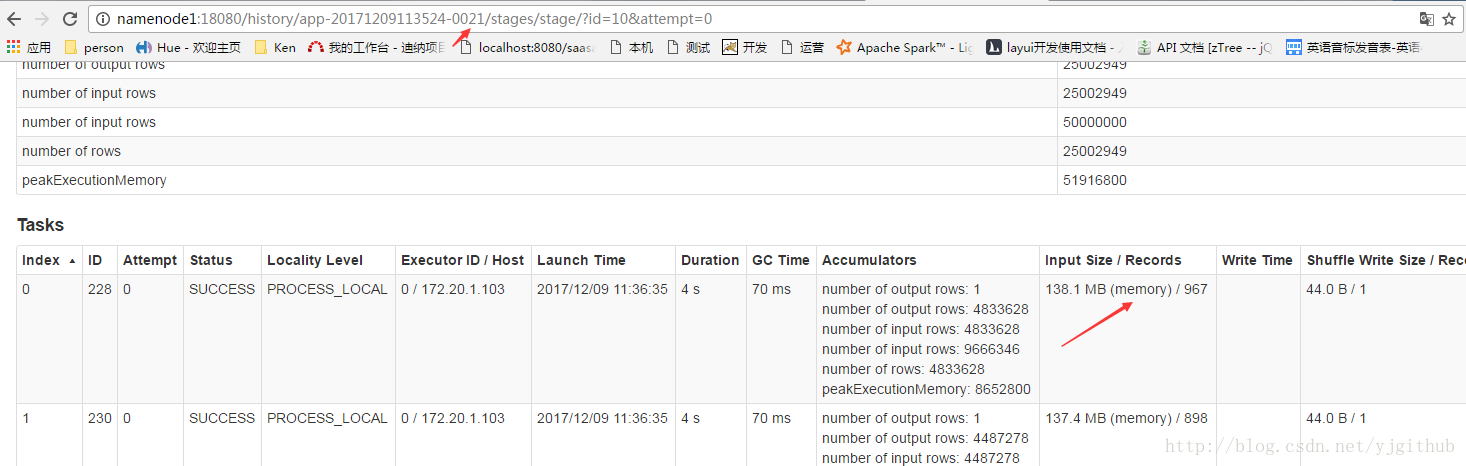
ID 0020 : 每次sql都从hadoop中拉取数据
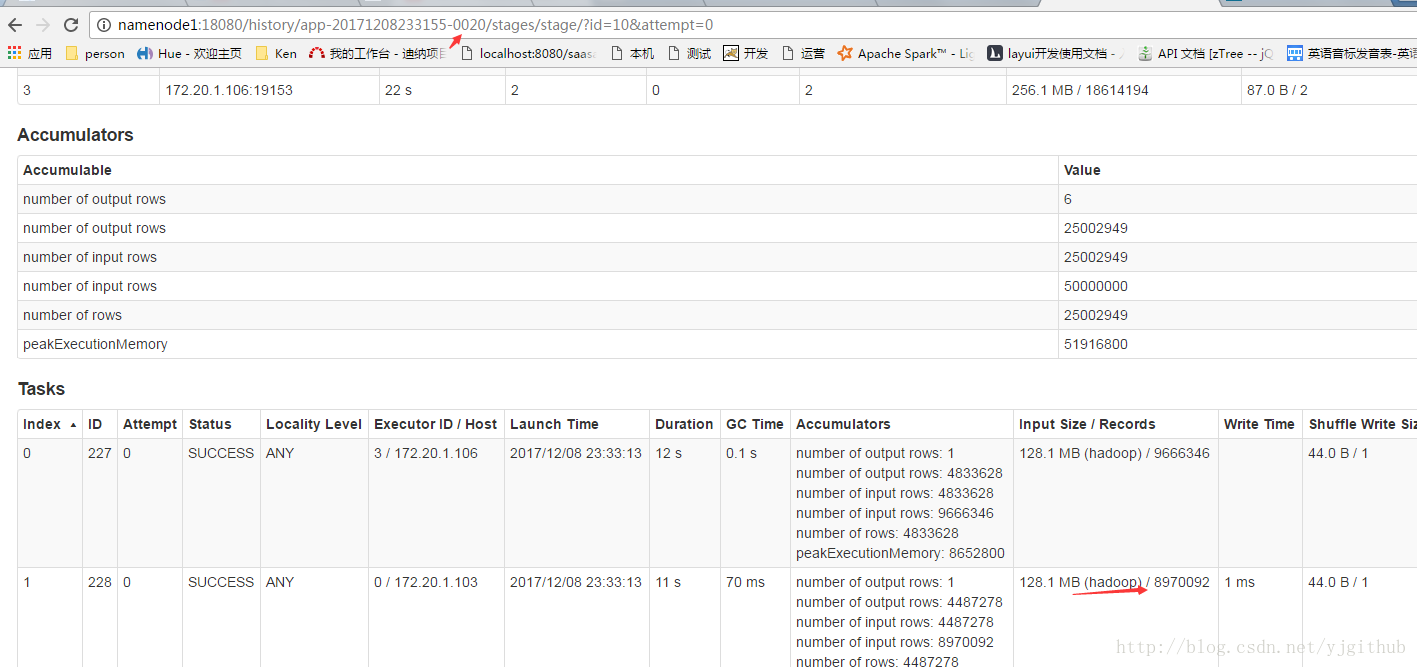
ps:这里也是个性能调优,重复利用的RDD,尽量缓存起来,速度会提升很多
运行结果:

案例二:
a.案例描述与分析
在案例一中,我们将存储于 HDFS 中的文件转换成 DataFrame 并进行了一系列的统计,细心的读者会发现,都是一个关联于一个 DataFrame 的简单查询和统计,那么在案例二中,我们将向读者展示如何连接多个 DataFrame 做更复杂的统计分析。
在本案例中,我们将统计分析 100W用户和 1 000W条交易数据。对于用户数据,它是一个包含 6 个列 (ID, 性别, 年龄, 注册日期, 角色 (从事行业), 所在区域) 的文本文件,具有以下格式。
用户数据

对于交易数据,它是一个包含 5 个列 (交易单号, 交易日期, 产品种类, 价格, 用户 ID) 的文本文件,具有以下格式。
交易数据
b.编码实现
b1.数据生成
用户数据:
package Sql.peopleinfo
import java.io.FileWriter
import scala.util.Random
/**
* Created by Administrator on 2017/12/8.
*/
object UserDataGenerator {
private val FILE_PATH = "F:/sparkTestData/UserDataMin.txt"
private val ROLE_ID_ARRAY = Array[String]("ROLE001","ROLE002","ROLE003","ROLE004","ROLE005")
private val REGION_ID_ARRAY = Array[String]("REG001","REG002","REG003","REG004","REG005")
private val MAX_USER_AGE = 60
//how many records to be generated 100W
private val MAX_RECORDS = 1000000
def main(args:Array[String]): Unit = {
generateDataFile(FILE_PATH , MAX_RECORDS)
}
private def generateDataFile(filePath : String, recordNum: Int): Unit = {
var writer:FileWriter = null
try {
writer = new FileWriter(filePath,true)
val rand = new Random()
for (i <- 1 to recordNum) {
//generate the gender of the user
var gender = getRandomGender
//
var age = rand.nextInt(MAX_USER_AGE)
if (age < 10) {
age = age + 10
}
//generate the registering date for the user
var year = rand.nextInt(16) + 2000
var month = rand.nextInt(12)+1
//to avoid checking if it is a valid day for specific month
//we always generate a day which is no more than 28
var day = rand.nextInt(28) + 1
var registerDate = year + "-" + month + "-" + day
//generate the role of the user
var roleIndex:Int = rand.nextInt(ROLE_ID_ARRAY.length)
var role = ROLE_ID_ARRAY(roleIndex)
//generate the region where the user is
var regionIndex:Int = rand.nextInt(REGION_ID_ARRAY.length)
var region = REGION_ID_ARRAY(regionIndex)
writer.write(i + " " + gender + " " + age + " " + registerDate
+ " " + role + " " + region)
writer.write(System.getProperty("line.separator"))
}
}catch {
case e:Exception => println("Error occurred:" + e)
}finally {
if (writer != null)
writer.close()
}
println("User Data File generated successfully.")
}
private def getRandomGender() :String = {
val rand = new Random()
val randNum = rand.nextInt(2) + 1
if (randNum % 2 == 0) {
"M"
} else {
"F"
}
}
}
交易记录:
package Sql.peopleinfo
import java.io.FileWriter
import scala.util.Random
/**
* Created by Administrator on 2017/12/8.
*/
object ConsumingDataGenerator {
private val FILE_PATH = "F:/sparkTestData/ConsumingDataMin.txt"
// how many records to be generated
private val MAX_RECORDS = 10000000
// we suppose only 10 kinds of products in the consuming data
private val PRODUCT_ID_ARRAY = Array[Int](1,2,3,4,5,6,7,8,9,10)
// we suppose the price of most expensive product will not exceed 2000 RMB
private val MAX_PRICE = 2000
// we suppose the price of cheapest product will not be lower than 10 RMB
private val MIN_PRICE = 10
//the users number which should be same as the one in UserDataGenerator object
private val USERS_NUM = 1000000
def main(args:Array[String]): Unit = {
generateDataFile(FILE_PATH,MAX_RECORDS);
}
private def generateDataFile(filePath : String, recordNum: Int): Unit = {
var writer:FileWriter = null
try {
writer = new FileWriter(filePath,true)
val rand = new Random()
for (i <- 1 to recordNum) {
//generate the buying date
var year = rand.nextInt(16) + 2000
var month = rand.nextInt(12)+1
//to avoid checking if it is a valid day for specific
// month,we always generate a day which is no more than 28
var day = rand.nextInt(28) + 1
var recordDate = year + "-" + month + "-" + day
//generate the product ID
var index:Int = rand.nextInt(PRODUCT_ID_ARRAY.length)
var productID = PRODUCT_ID_ARRAY(index)
//generate the product price
var price:Int = rand.nextInt(MAX_PRICE)
if (price == 0) {
price = MIN_PRICE
}
// which user buys this product
val userID = rand.nextInt(USERS_NUM)+1
writer.write(i + " " + recordDate + " " + productID
+ " " + price + " " + userID)
writer.write(System.getProperty("line.separator"))
}
writer.flush()
} catch {
case e:Exception => println("Error occurred:" + e)
} finally {
if (writer != null)
writer.close()
}
println("Consuming Data File generated successfully.")
}
}
b2.业务代码
package Sql.peopleinfo
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.SQLContext
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by Administrator on 2017/12/8.
*/
//define case class for user
case class User(userID:String,gender:String,age:Int,registerDate:String,role:String,region:String)
//define case class for consuming data
case class Order(orderID:String,orderDate:String,productID:Int,price:Int,userID:String)
object UserConsumingDataStatistics {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
if (args.length < 1) {
println("Usage:UserConsumingDataStatistics userDataFilePath consumingDataFilePath")
System.exit(1)
}
val conf = new SparkConf().setAppName("UserConsumingDataStatistics")
//Kryo serializer is more quickly by default java serializer
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val ctx = new SparkContext(conf)
val sqlCtx = new SQLContext(ctx)
//隐士转换
//需要添加import sqlContext.implicits._,才可以调用.toDF
import sqlCtx.implicits._
//Convert user data RDD to a DataFrame and register it as a temp table
val userDF = ctx.textFile(args(0)).map(_.split(" ")).map(
u => User(u(0), u(1), u(2).toInt,u(3),u(4),u(5))).toDF()
userDF.registerTempTable("user")
//Convert consuming data RDD to a DataFrame and register it as a temp table
val orderDF = ctx.textFile(args(1)).map(_.split(" ")).map(o => Order(
o(0), o(1), o(2).toInt,o(3).toInt,o(4))).toDF()
orderDF.registerTempTable("orders")
//cache the DF in memory with serializer should make the program run much faster
userDF.persist(StorageLevel.MEMORY_ONLY_SER)
orderDF.persist(StorageLevel.MEMORY_ONLY_SER)
//业务逻辑
//The number of people who have orders in the year 2015
val count = orderDF.filter(orderDF("orderDate").contains("2015"))
.join(userDF,orderDF("userID").equalTo(userDF("userID"))).count()
println("The number of people who have orders in the year 2015:" + count)
//total orders produced in the year 2014
val countOfOrders2014 = sqlCtx.sql("" +
"SELECT *" +
" FROM orders" +
" where orderDate like '2014%'").count()
println("total orders produced in the year 2014:" + countOfOrders2014)
//Orders that are produced by user with ID 1 information overview
val countOfOrdersForUser1 = sqlCtx.sql("" +
"SELECT" +
" o.orderID," +
" o.productID," +
" o.price," +
" u.userID" +
" FROM orders o,user u" +
" where u.userID = 1 and u.userID = o.userID").show()
println("Orders produced by user with ID 1 showed.")
//Calculate the max,min,avg prices for the orders that are producted by user with ID 10
val orderStatsForUser10 = sqlCtx.sql("" +
"SELECT" +
" max(o.price) as maxPrice," +
" min(o.price) as minPrice," +
" avg(o.price) as avgPrice," +
" u.userID" +
" FROM orders o, user u" +
" where u.userID = 10 and u.userID = o.userID" +
" group by u.userID")
println("Order statistic result for user with ID 10:")
orderStatsForUser10.collect().map(order => "Minimum Price=" + order.getAs("minPrice")
+ ";Maximum Price=" + order.getAs("maxPrice")
+ ";Average Price=" + order.getAs("avgPrice")
).foreach(result => println(result))
}
}
c.提交运行
./spark-submit –class Sql.peopleinfo.UserConsumingDataStatistics\
–master spark://:7077 \
–num-executors 6 \
–driver-memory 8g \
–executor-memory 2g \
–executor-cores 2 \
/home/fams/DataDemo.jar \
hdfs://:9000/user/fams/inputfiles/UserData.txt \
hdfs://:9000/user/fams/inputfiles/ConsumingData.txt
d.结果数据

3.Spark SQL程序开发需要注意哪些内容?
Spark SQL 程序开发过程中,我们有两种方式确定 schema,第一种是反射推断 schema,如本文的案例二,这种方式下,我们需要定义样本类 (case class) 来对应数据的列;第二种方式是通过编程方式来确定 schema,这种方式主要是通过 Spark SQL 提供的 StructType 和 StructField 等 API 来编程实现,这种方式下我们不需要定义样本类,如本文中的案例一
在程序实现中,我们需要使用以便隐式的把 RDD 转化成 DataFrame 来操作。
本文展示的 DataFrame API 使用的方法只是其中很小的一部分,但是一旦读者掌握了开发的基本流程,就能通过参考 DataFrame API 文档 写出更为复杂的程序。
通常来说,我们有两种方式了解 Spark 程序的执行流程。第一种是通过在控制台观察输出日志,另一种则更直观,就是通过 Spark Web Console 来观察 Driver 程序里各个部分产生的 job 信息以及 job 里包含的 stages 信息。
需要指出的是,熟练的掌握 Spark SQL/DataFrame 的知识对学习最新的 Spark 机器学习库 ML Pipeline 至关重要,因为 ML Pipeline 使用 DataFrame 作为数据集来支持多种的数据类型。
笔者在测试的过程中发现,处理相同的数据集和类似的操作,Spark SQL/DataFrame 比传统的 RDD 转换操作具有更好的性能。这是由于 SQL 模块的 Catalyst 对用户 SQL 做了很好的查询优化。在以后的文章中会向读者详细的介绍该组件。