上一篇文章(点击链接:【Linux进程、线程、任务调度】二)讲了:
- fork vfork clone 的含义
- 写时拷贝技术
- Linux线程的实现本质
- 进程0 和 进程1
- 进程的睡眠和等待队列
- 孤儿进程的托孤 ,SUBREAPER
本篇文章接着上一篇文章记录以下学习内容:
- CPU/IO消耗型进程
- 吞吐率 vs. 响应
- SCHED_FIFO算法 与 SCHED_RR算法
- SCHED_NORMAL算法 和 CFS算法
- nice与renice
- chrt
本篇文章主要讲解Linux系统调度器。对于调度器来说,我们需要考虑的有:吞吐与响应,CPU消耗型与IO消耗型进程。这四点都是对于调度算法的输入来说的。
同时,调度器的单位是线程,但是线程,我们知道在第一篇文章中已经讲解了,线程是一种轻量级的进程。所以本篇文章在说调度的对象时说的都是进程,但是我们要理解,线程才是调度单位。这并不矛盾!!!
1、吞吐 vs. 响应
吞吐和响应之间的矛盾
- 响应:最小化某个任务的响应时间,哪怕以牺牲其他任务为代价
- 吞吐:全局视野,整个系统的workload被最大化处理
首先我们在考虑调度器的时候,我们要理解操作系统的调度器设计目标追求两点:吞吐率大和延迟低。
这两点是相互矛盾的。因为吞吐率大,势必要把更多的时间放到真实有用功上,而不是把时间浪费在进程上下文切换上。而延迟低,势必要求优先级高的进程可以随时抢占进来,打断别人,强行插队。但是上下文切换的时间,对吞吐率来讲,本身是一个消耗。花了很多时间在上下文切换上,相当于做了很多无用功。这种消耗可以低到2us或者更低(这看起来没什么?),但是上下文切换更大的消耗不是切换本身,而是切换导致的cache miss。本身跑微博跑的好好的,现在要切换过去跑微信,CPU的cache,是很难命中微信的。

不抢占,肯定响应差,抢了又会导致吞吐率下降。
Linux系统不是一个完全照顾吞吐的系统,也不是一个完全照顾相应的的系统。它作为一个软实时系统,实际上是想达到某种平衡(后面会讲)。同时也提供给用户一定的配置能力。在内核编译的时候,Kernel Features —> Preemption Model选项实际上可以让我们编译内核的时候,是倾向于支持吞吐,还是支持响应:
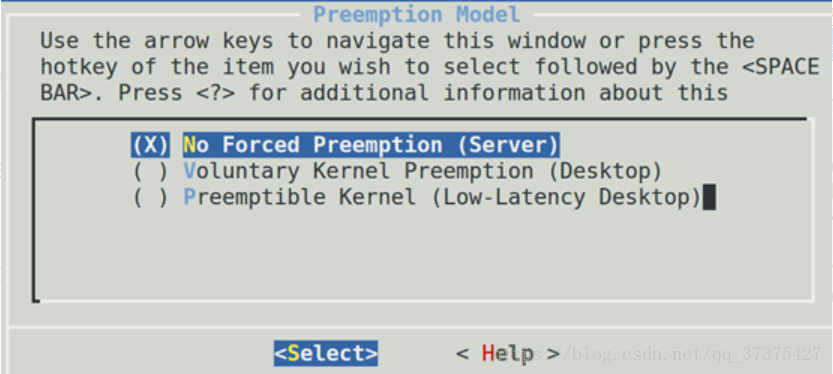
越往上面选,吞吐越好,越好下面选,响应越好。服务器你一个月也难得用一次鼠标,而桌面则显然要求一定的响应,这样可以保证UI行为的表现较好。但是Linux即便选择的是最后一个选项“Preemptible Kernel (Low-Latency Desktop)”,它仍然不是硬实时的(下一篇文章讲解为何Linux系统不是一个硬实时系统)。
2、IO消耗型 vs. CPU消耗型
进程分为:IO消耗型进程与CPU消耗型进程
- IO消耗型(狂睡,等IO资源等):CPU利用率低,进程的运行效率主要受限于I/O速度
- CPU消耗型(狂算):多数时间花在CPU上面(做运算)
一般而言,IO消耗型任务对延迟比较敏感,应该被优先调度。它虽然时间都花在IO上,不关心CPU的性能,但是它关心的是是否能够及时的拿到CPU的使用权。也就是是否可以及时的被CPU调度。当自己完成了IO操作,但是一直不被CPU调度,那肯定也是不行的。比如,你正在疯狂编译安卓系统,而等鼠标行为的用户界面老不工作(正在狂睡),但是鼠标一点,我们应该优先打断正在编译的进程,而去响应鼠标这个I/O,这样电脑的用户体验才符合人性。
3、实时进程调度
在早期2.6内核时,调度器使用的是优先级数组和Bitmaps
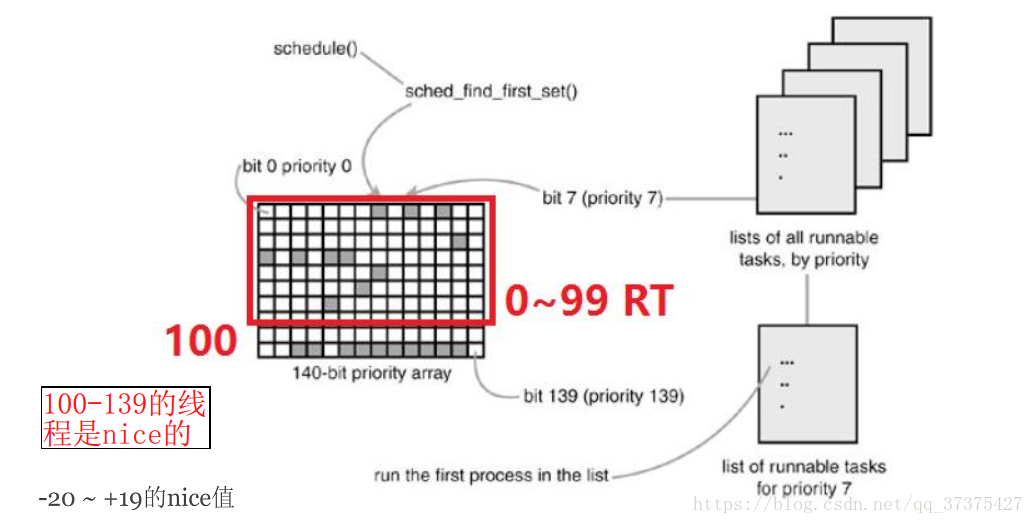
- 优先级号一共有0-139,其中0-99的是RT(实时)进程,100-139的是非实时进程。
- 某个优先级有TASK_RUNNING进程,响应bit设置为1.
- 调度第一个bitmap设置为1的进程。
对于Linux的RT进程,按照SCHED_FIFO和SCHED_RR的策略。
- SCHED_FIFO:不同优先级按照优先级高的先跑到睡眠,优先级低的再跑。同等优先级的先进先出,先ready的跑到睡,后ready的接着跑。
- SCHED_RR:不同优先级按照优先级高的先跑到睡眠,优先级低的再跑。同等优先级的进行时间片轮转。
比如Linux存在如下4个进程,T1~T4(内核里面优先级数字越低,优先级越高):

那么它们在Linux的跑法就是:

当然,Linux中大多数的进程都不是RT的,而是非RT的普通进程。并且,就算有RT的进程一直存在,CPU也不会一直被RT进程霸占,必须给普通进程留有一定的时间片。在Linux中存在一个RT门限。
在sched_rt_period_us时间内,RT进程最多跑sched_rt_runtime_us时间,剩下的时间必须留给非RT进程使用。
在Linux系统中上述两个时间在如下位置:
/proc/sys/kernel/sched_rt_period_us
/proc/sys/kernel/sched_rt_runtime_us
4、非实时进程的调度
4.1 早期2.6内核:
- 在不同的优先级进行时间片轮转
- -20 ~ 19的nice值
- 根据睡眠情况,动态奖励和惩罚
普通进程调度,进程不会像RT进程那样一致霸占CPU,而是所有的进程都轮转获得CPU,只是当优先级高的话,可获得更多的时间片,醒来后可以抢占优先级低的进程。
但是,当进程的CPU占有率高,或者一开始的优先级高的话,后面内核会降低它的优先级,这样可以让IO消耗型的进程能够竞争过CPU消耗型的进程。
从而保障IO消耗型的进程能够及时获得CPU使用权。
4.2 CFS完全公平调度策略
新内核采用的调度策略就不是那么简单了,为了很好的统一CPU消耗型与IO消耗型进程的调度,与优先级(nice值)的协调,新内核采用了一种策略:完全公平调度策略。
注意:完全公平调度策略是针对普通进程而言的。
完全公平调度策略,内部的实现使用的是红黑树。左边节点的值小于右边节点的值。
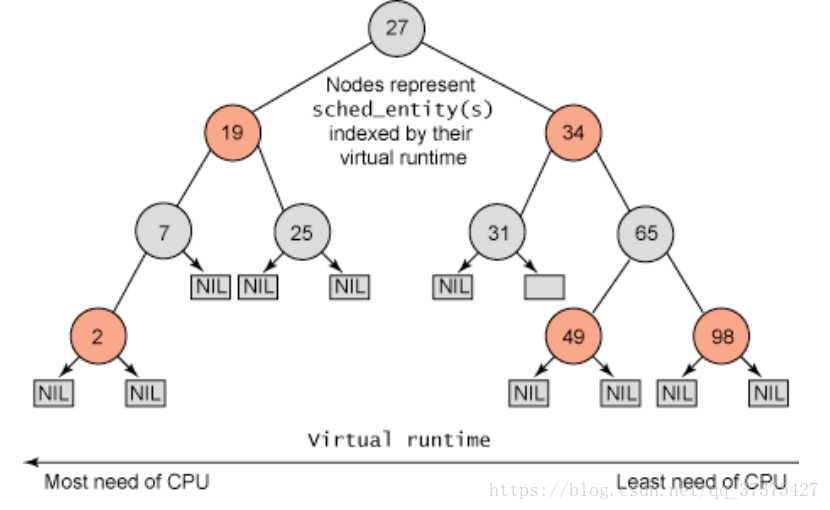
红黑树节点的值为vruntime,进程的虚拟运行时间。
vruntime = pruntime * NICE_0_LOAD/ weight
- pruntime:进程的物理运行时间,即实际的运行时间
- weight:权重
- NICE_0_LOAD:参数,等于1024,也是nice值为0的权重
nice值与weight值的对应关系:

CFS调度策略:
当RT进程都睡眠了(或者RT进程已经跑了超过了sched_rt_runtime_us时间值),那么就该普通进程被调度了。Linux最先调度vruntime最小的进程,也就是位于红黑树最左边的进程。假设最先调度的进程是p1,那么随着p1的运行,p1的pruntime就会变大,就会导致p1的vruntime就会变大,那么p1在红黑树中的位置就会往右移动。下一次,就会调度最新的vruntime最小的进程(最新的红黑树最左边的进程)。
那么什么样的线程最容易被调度呢?由上述公式知,当pruntime小,weight值大的时候,vruntime小,最容易被调度到。而pruntime小意味着是IO消耗型进程,weight值大的意味着是nice值小(优先级高)的进程。
这样的话,我们就可以看到,红黑树很神奇的同时照顾了普通进程的CPU/IO消耗型与优先级(nice值)的情况。
比如有4个普通进程,如下表,目前显然T1的vruntime最小(这是它喜欢睡的结果),然后T1被调度到。
| pruntime | Weight | vruntime | |
|---|---|---|---|
| T1 | 8 | 1024(nice=0) | 8*1024/1024=8 |
| T2 | 10 | 526 (nice=3) | 10*1024/526=19 |
| T3 | 20 | 1024(nice=0) | 20*1024/1024=20 |
| T4 | 20 | 820 (nice=1) | 20*1024/820=24 |
然后,我们假设T1被调度再执行12个pruntime,它的vruntime将增大delta*1024/weight(这里delta是12,weight是1024),于是T1的vruntime成为20,那么这个时候vruntime最小的反而是T2(为19),此后,Linux将倾向于调度T2(尽管T2的nice值大于T1,优先级低于T1,但是它的vruntime现在只有19)。
所以普通进程的调度,是一个综合考虑IO/CPU消耗型与优先级的,通俗点说就是考虑你喜欢睡还是喜欢干活,以及你的nice值是多少(优先级高不高)。所以,Linux中进程的调度时间是不确定的,它具有随机性,无法判断一个进程的调度的延迟,更无法判断一个进程什么时候会被调度到,它是需要看看当前系统中是否还有其他进程在跑,以及被唤醒的进程的nice值以及它之前喜不喜欢睡觉!!!
还有一点要注意:普通进程在跑,如果突然有一个RT进程过来了,那么RT进程就是无敌的,它会被调度,直到它运行结束或者睡眠。
5、工具chrt和renice
chrt工具可以设置进程的调度策略与优先级,nice和renice可设置进程的nice值。renice是程序已经跑起来了你可以去设置nice值。
看一下程序:
two-loops.c
#include <stdio.h>
#include <pthread.h>
#include <sys/types.h>
void *thread_fun(void *param)
{
printf("thread pid:%d, tid:%lu\n", getpid(), pthread_self());
while (1) ;
return NULL;
}
int main(void)
{
pthread_t tid1, tid2;
int ret;
printf("main pid:%d, tid:%lu\n", getpid(), pthread_self());
ret = pthread_create(&tid1, NULL, thread_fun, NULL);
if (ret == -1) {
perror("cannot create new thread");
return 1;
}
ret = pthread_create(&tid2, NULL, thread_fun, NULL);
if (ret == -1) {
perror("cannot create new thread");
return 1;
}
if (pthread_join(tid1, NULL) != 0) {
perror("call pthread_join function fail");
return 1;
}
if (pthread_join(tid2, NULL) != 0) {
perror("call pthread_join function fail");
return 1;
}
return 0;
}
-
编译并在后天运行两份:
$ gcc two-loops.c -pthread
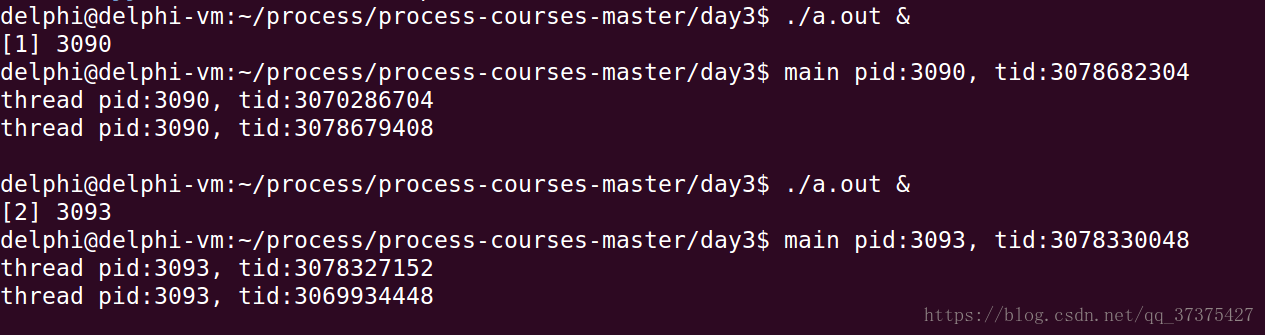
top命令查看CPU利用率:

可以看到,运行的两个程序的CPU利用率都接近百分之百。
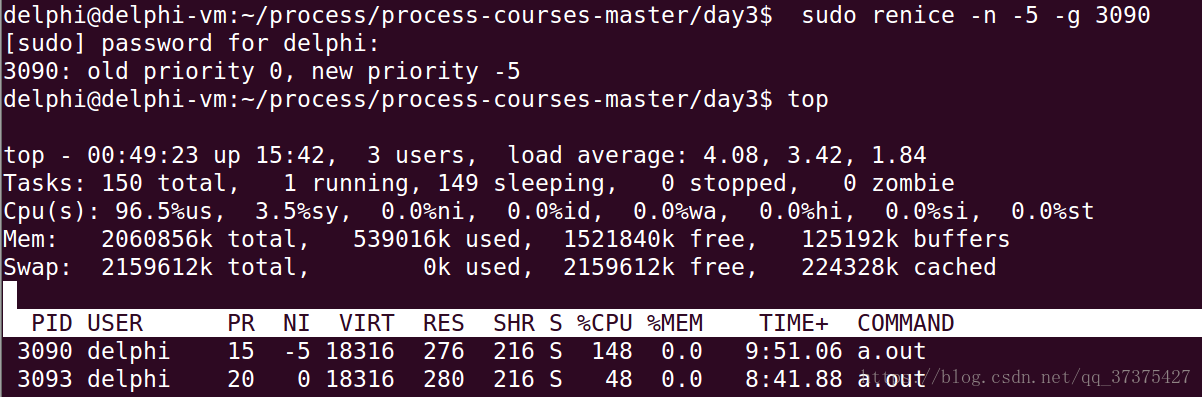
renice其中之一,再观察CPU利用率
可以很明显的看到,renice修改了进程的优先级,导致进程的CPU占有率变了。
- 编译并在后台运行一份

top查看器CPU利用率接近百分之200:

把它所有的线程设置为SCHED_FIFO调度策略,优先级为50:
$ chrt -f -p 50 3110
- -f代表FIFO,-p代表进程pid 50为设置的优先级
然后会发现进程的CPU利用率会降低一些。
当然设置调度策略(SCHED_FIFO)和RT优先级,除了可以用chrt工具,还可以直接在代码里写:

6、总结
掌握以下内容:
- CPU消耗型与IO消耗型
- 吞吐与响应的关系
- SCHED_FIFO 与SCHED_RR调度策略
- SCHED_NORMAL和CFS完全公平调度策略
- nice和renice
- chrt工具
探讨学习加:
qq:1126137994
微信:liu1126137994