机器学习实战的读书笔记+自己实战。
一、朴素贝叶斯算法介绍
假设有一个数据集,由两类组成(简化问题),对于每个样本的分类,我们都已经知晓。数据分布如下图(图取自MLiA):
现在出现一个新的点new_point (x,y),其分类未知。我们可以用p1(x,y)表示数据点(x,y)属于红色一类的概率,同时也可以用p2(x,y)表示数据点(x,y)属于蓝色一类的概率。那要把new_point归在红、蓝哪一类呢?
我们提出这样的规则:
如果p1(x,y) > p2(x,y),则(x,y)为红色一类。
如果p1(x,y) <p2(x,y), 则(x,y)为蓝色一类。
换人类的语言来描述这一规则:选择概率高的一类作为新点的分类。这就是贝叶斯决策理论的核心思想,即选择具有最高概率的决策。
用条件概率的方式定义这一贝叶斯分类准则:
扫描二维码关注公众号,回复: 10319902 查看本文章
如果p(red|x,y) > p(blue|x,y), 则(x,y)属于红色一类。
如果p(red|x,y) < p(blue|x,y), 则(x,y)属于蓝色一类。
也就是说,在出现一个需要分类的新点时,我们只需要计算这个点的
max(p(c1 | x,y),p(c2 | x,y),p(c3 | x,y)...p(cn| x,y))。其对于的最大概率标签,就是这个新点的分类啦。
那么问题来了,对于分类i 如何求解p(ci| x,y)?
没错,就是贝叶斯公式:

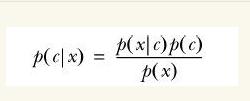
实例:判断一个文档是否为辱骂性文档
训练数据:在某网站摘下6篇评论文档,已知他们是正常或侮辱性的文档,将他分词得到词库,并计算在每个类别中不同的词对应的词频。
测试数据:摘取网站中另一评论文档,将他分词得到词向量,并与词库对比,得到在词库中的词是否出现。
这里的X表示多个特征(词)x1,x2,x3...组成的特征向量。
P(bad|x)表示:已知评论内容而这条评论是辱骂性评论的概率。
利用贝叶斯公式,进行转换:
P(bad|X) = p(X|bad) p(bad) / p(X)
P(normal | X) = p(X|normal)p(normal) / p(X)
比较上面两个概率的大小,如果p(bad|X) > p(normal|X),则这条评论是辱骂的,反之则不是。
朴素贝叶斯分类的正式定义如下:
1、设
![]()
为一个待分类项,而每个a为x的一个特征向量。
2、有类别集合
![]()
3、计算
![]()
4、如果
![]()
则
![]()
。
那么现在的关键就是如何计算第3步中的各个条件概率。我们可以这么做:
1、找到一个已知分类的待分类项集合,这个集合叫做训练样本集。
2、统计得到在各类别下各个特征属性的条件概率估计。即。
3、如果各个特征属性是条件独立的,则根据贝叶斯定理有如下推导:
![]()
因为分母对于所有类别为常数,因为我们只要将分子最大化皆可。又因为各特征属性是条件独立的,所以有:

这里要引入朴素贝叶斯假设了。如果认为每个词都是独立的特征,那么评论内容可以展开为:分词(x1,x2,x3...xn),因此有了下面的公式推导
P(bad|X) = p(X|bad)p(bad) = p(x1, x2, x3, x4...xn | bad) p(bad)
假设所有词相互条件独立,则进一步拆分:
P(bad|X) = p(x1|bad)p(x2|bad)p(x3|bad)...p(xn|bad) p(bad)
看公式p(bad|X)=p(x1|bad)p(x2|bad)p(x3|bad)...p(xn|bad) p(bad)
至此,P(xi|ad)很容易求解,就是在训练数据的辱骂文档中,各个词出现的频率。*注意但这并不是在这个测试数据中的概率,所以还应乘以0/1,但0会使整个概率变为0,所以我们对所有数据取对(ln),这样乘法就变为加法,即ln(p(bad|x))=∑(0 or 1)*ln(xi|bad)
那么原公式变为ln( p(x|bad) )~ln(p(bad|x))+ln( p(bad) )
P(bad)为训练集中侮辱性文档所占的概率。我们的问题也就迎刃而解了。
《机器学习实战》这本书使用的全英文文档,这里我们换一下数据集,改成孙笑川和edc开战下的评论,当然分词等代码也会做相应的修改。
其中1是辱骂性的句子,0是粉圈句子(标题党了,并不是区分粉丝,而是辱骂与否)
总体代码如下:
from numpy import *
import jieba
import jieba.posseg as pseg
import re
import jieba.analyse
def fenci(str):
tags = pseg.cut(str) #jieba分词
res=[]
for t in tags:
if(t.flag!='w' and t.flag!='x'):
res.append(t.word)
return res
def loadDataSet():
coachData=['这群楼上都他妈屌丝的不行',
'一群屌丝。弱智一样。',
'宝宝,好好休息',
'纯路人,你处世性格就像个铁憨憨',
'就想说,不要在意那些有恶意的人,如果你在意那就让他们得意了,您应该时刻记着还有我们在时刻支持您,不管以前的路怎么走,往后的日子会越来越好,加油!',
'女菩萨,看看?嗷',
'透你们?的',
'女菩萨可以嗦一下你的??',
'在我心中你是最好的 ',
'宝宝注意身体 工作加油',
'啊啊啊啊啊注意身体 好好休息',
'早早早 好好休息好好照顾自己']
classVec = [1,1,0,1,0,1,1,1,0,0,0,0] #1 is abusive, 0 not
postingList=[]
for i in range(len(coachData)):
postingList.append(fenci(coachData[i]))
return postingList,classVec
def createVocabList(dataSet):
vocabSet = set([]) #create empty set
for document in dataSet:
vocabSet = vocabSet | set(document) #union of the two sets
return list(vocabSet)
def setOfWords2Vec(vocabList, inputSet):
returnVec = [0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] = 1
#else: print("the word: %s is not in my Vocabulary!" % word)
return returnVec
def trainNB0(trainMatrix,trainCategory):
numTrainDocs = len(trainMatrix)
numWords = len(trainMatrix[0])
pAbusive = sum(trainCategory)/float(numTrainDocs)
p0Num = ones(numWords); p1Num = ones(numWords) #change to ones()
p0Denom = 2.0; p1Denom = 2.0 #change to 2.0
for i in range(numTrainDocs):
if trainCategory[i] == 1:
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else:
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = log(p1Num/p1Denom) #change to log()
p0Vect = log(p0Num/p0Denom) #change to log()
return p0Vect,p1Vect,pAbusive
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
p1 = sum(vec2Classify * p1Vec) + log(pClass1) #element-wise mult
p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1)
if p1 > p0:
return 1
else:
return 0
listOPosts,listClasses=loadDataSet()
myVocabList=createVocabList(listOPosts)
trainMat=[]
for postinDoc in listOPosts:
trainMat.append(setOfWords2Vec(myVocabList,postinDoc))
p0V,p1V,pAb=trainNB0(trainMat,listClasses)
testStr='铁憨憨,给老子爬'
testEntry=fenci(testStr)
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
print(testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb))
testStr='宝宝,好好照顾好自己呀'
testEntry=fenci(testStr)
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
print(testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb))
testStr='天空一声惊雷响,新津降下孙笑川。 年少不知精子贵,欲把香?都透穿。 手持雷霆双节棍,亲?莱莱一锅端。 步入中年威名响,敢骂冠希铁憨憨。 自称地下Rap皇,电鳗 ? 恰的酸。 老来亲属无人怜,日日走访鬼门关。 终因纵欲无节制,小命丧于红塔山。'
testEntry=fenci(testStr)
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
print(testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb))