准备工作
- 三台虚拟机
192.168.48.11 HadoopNode01
192.168.48.12 HadoopNode02
192.168.48.13 HadoopNode03
- 配置ip地址映射
[root@HadoopNode0X ~]# vim /etc/hosts
192.168.48.11 HadoopNode01
192.168.48.12 HadoopNode02
192.168.48.13 HadoopNode03
- 关闭防火墙
[root@HadoopNode0X ~]# systemctl stop firewalld
[root@HadoopNode0X ~]# systemctl disable firewalld
- 修改hostname
[root@HadoopNode0X ~]# vim /etc/hostname
HadoopNode01|HadoopNode02|HadoopNode03
- 同步时钟
[root@HadoopNodeX ~]# yum install ntpdate -y
[root@HadoopNodeX ~]# ntpdate 0.asia.pool.ntp.org
- 配置SSH免密登录
[root@HadoopNodeX ~]# ssh-keygen -t rsa
[root@HadoopNodeX ~]# ssh-copy-id HadoopNode01
[root@HadoopNodeX ~]# ssh-copy-id HadoopNode02
[root@HadoopNodeX ~]# ssh-copy-id HadoopNode03
- 重启服务器
[root@HadoopNodeX ~]# reboot
安装JDK
- 上传JDK安装包(版本JDK8.0)
- 安装
[root@HadoopNodeX ~]# rpm -ivh jdk-8u181-linux-x64.rpm
[root@HadoopNodeX ~]# vi .bashrc JAVA_HOME=/usr/java/latest
CLASSPATH=.
PATH=$PATH:$JAVA_HOME/bin
export JAVA_HOME
export CLASSPATH
export PATH
[root@HadoopNodeX ~]# source .bashrc
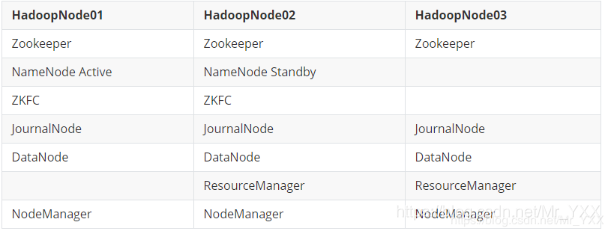
Zookeeper 和 HDFS集群正常
- HDFS/YARN集群暂时不需要
[root@HadoopNode01 ~]# jps
5859 Jps
1513 QuorumPeerMain
[root@HadoopNode02 ~]# jps
2552 Jps
1534 QuorumPeerMain
[root@HadoopNode03 ~]# jps
1892 QuorumPeerMain
2634 Jps
安装Spark HA集群
- 上传Hadoop安装包(版本2.9.2)
- 安装
[root@HadoopNodeX ~]# tar -zxf hadoop-2.9.2.tar.gz -C /usr
- 修改spark-env.sh配置文件
[root@HadoopNodeX spark-2.4.4]# cp conf/spark-env.sh.template conf/spark-env.sh
[root@HadoopNodeX spark-2.4.4]# vim conf/spark-env.sh
# 末尾添加如下配置
SPARK_WORKER_INSTANCES=1
SPARK_MASTER_PORT=7077
SPARK_WORKER_CORES=4
SPARK_WORKER_MEMORY=2g
LD_LIBRARY_PATH=/usr/hadoop-2.9.2/lib/native
SPARK_DIST_CLASSPATH=$(hadoop classpath)
export SPARK_MASTER_HOST
export SPARK_MASTER_PORT
export SPARK_WORKER_CORES
export SPARK_WORKER_MEMORY
export LD_LIBRARY_PATH
export SPARK_DIST_CLASSPATH
export SPARK_WORKER_INSTANCES
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=HadoopNode01:2181,HadoopNode02:2181,HadoopNode03:2181 -Dspark.deploy.zookeeper.dir=/spark"
- 修改slaves文件
[root@HadoopNodeX spark-2.4.4]# cp conf/slaves.template conf/slaves
[root@HadoopNodeX spark-2.4.4]# vim conf/slaves
HadoopNode01
HadoopNode02
HadoopNode03
- 配置环境变量
[root@HadoopNodeX ~]# vi /root/.bashrc
HADOOP_HOME=/usr/hadoop-2.9.2
JAVA_HOME=/usr/java/latest
SPARK_HOME=/usr/spark-2.4.4
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SPARK_HOME/bin:$SPARK_HOME/sbin
CLASSPATH=.
export HADOOP_HOME
export JAVA_HOME
export SPARK_HOME
export PATH
export CLASSPATH
[root@HadoopNodeX ~]# source ~/.bashrc
- 启动HA集群服务
[root@HadoopNodeX spark-2.4.4]# cp sbin/start-all.sh sbin/start-spark-all.sh
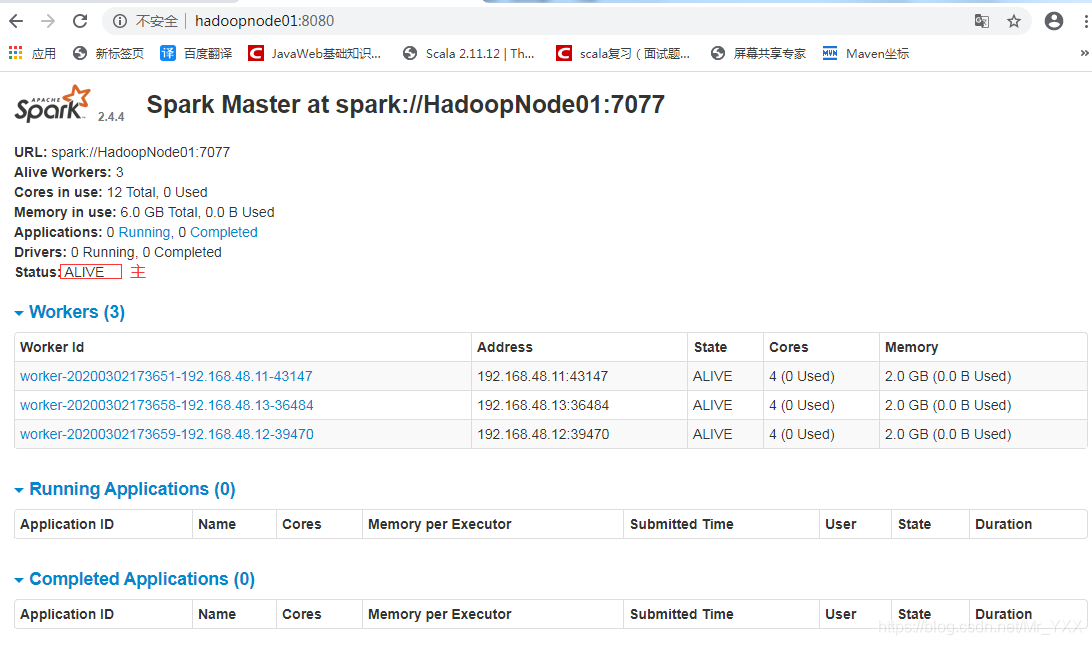
[root@HadoopNode01 spark-2.4.4]# start-spark-all.sh
[root@HadoopNode01 spark-2.4.4]# jps
4146 Master(主)
5859 Jps
4281 Worker(从)
1513 QuorumPeerMain
[root@HadoopNode02 spark-2.4.4]# jps
2310 Worker(从)
2552 Jps
1534 QuorumPeerMain
[root@HadoopNode03 spark-2.4.4]# jps
2499 Worker(从)
1892 QuorumPeerMain
2634 Jps
- 启动Master的备机
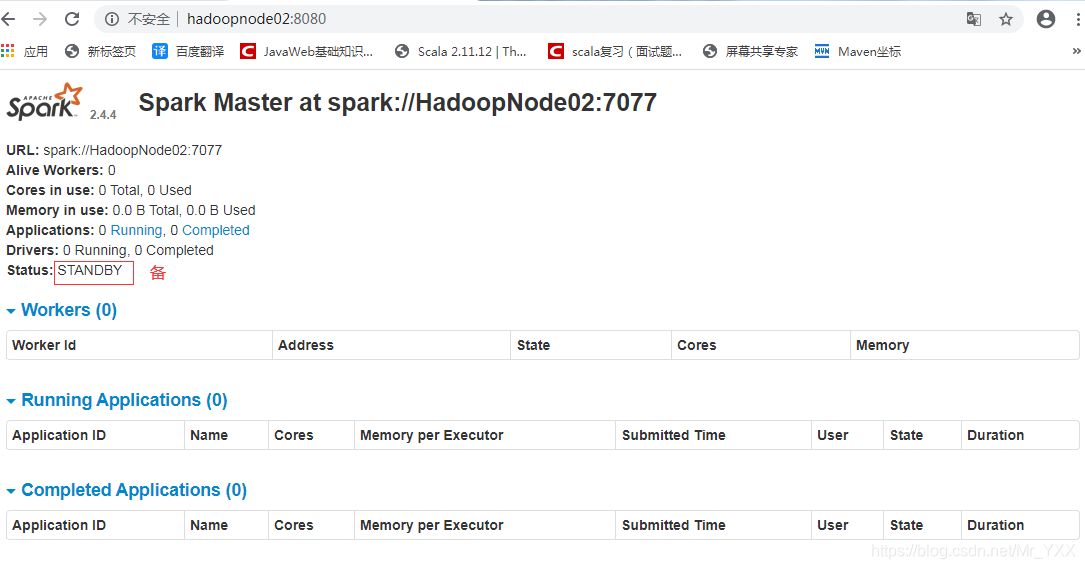
[root@HadoopNode02 spark-2.4.4]# start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/spark-2.4.4/logs/spark-root-org.apache.spark.deploy.master.Master-1-HadoopNode02.out
[root@HadoopNode02 spark-2.4.4]# jps
3042 Master
3219 Jps
2310 Worker
1534 QuorumPeerMain
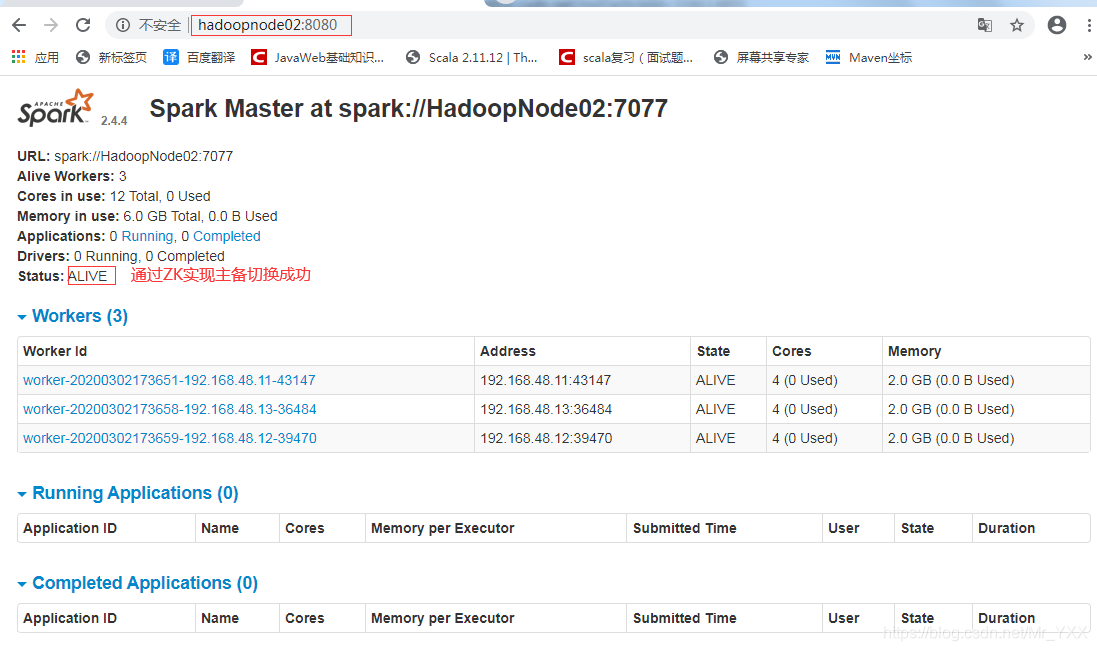
- 测试主备切换
[root@HadoopNode01 spark-2.4.4]# jps
4146 Master
6840 Jps
4281 Worker
1513 QuorumPeerMain
[root@HadoopNode01 spark-2.4.4]# kill -9 4146
[root@HadoopNode01 spark-2.4.4]# jps
6966 Jps
4281 Worker
1513 QuorumPeerMain
- 关闭HA集群服务
[root@HadoopNodeX spark-2.4.4]# cp sbin/stop-all.sh sbin/start-spark-all.sh
[root@HadoopNode01 spark-2.4.4]# start-spark-all.sh
