前期准备:3个以上linux虚拟机集群(推荐centos),并且配置免密登录
hadoop伪分布式集群
每个虚拟机需要安装jdk
1.从spark官网下载编译好的spark文件,如下图

2.上传文件到计划作为Master的虚拟机,解压到安装路径的路径 /home/hadoop/apps
tar -zxvf spark-2.3.0-bin-hadoop2.7.tgz -C /home/hadoop/apps
3.名字太长,mv换成spark
mv spark-2.3.0-bin-hadoop2.7 spark
drwxr-xr-x. 10 hadoop hadoop 194 4月 27 09:41 hadoop
drwxrwxr-x. 8 hadoop hadoop 159 4月 28 07:47 hive
drwxr-xr-x. 13 hadoop hadoop 211 2月 23 03:42 spark
4.进入spark,将
spark-env.sh.template文件名改成spark-env.sh
mv spark-env.sh.template spark-env.sh
5.vi
spark-env.sh ,配置JAVA_HOME , SPARK_MASTER_IP, SPARK_MASTER_PORT

cat /etc/profile
复制JDK的路径 export JAVA_HOME=/usr/local/jdk1.8.0_162
输入本机jdk地址,IP地址(或者是主机名),7077是spark默认端口,做rpc通信
5.mv slaves.
template slaves ,并配置worker的IP地址,或者是主机名(推荐使用主机名,可以通过vi /etc/hosts来配置)
vi slaves
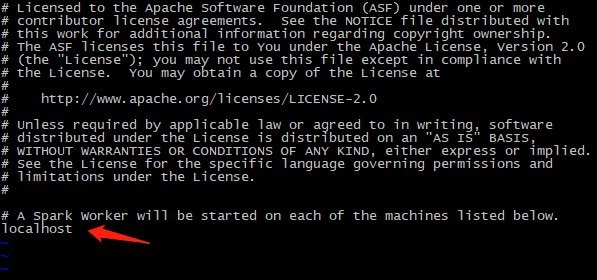
默认是单机,将本机做worker
如果是将本机既做Master 也做worker,那么保持不动
如果只将本机做Master,则删除localhost
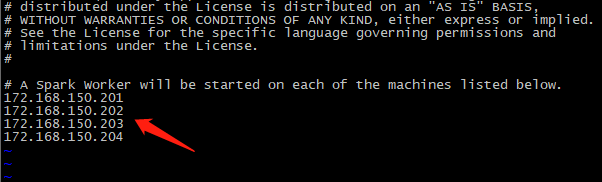
如果集群里每个主机都配置hosts文件,则可以直接写主机名

6.使用scp 命令 复制spark到所有的worker虚拟机上的相应目录
scp -r spark/ mini1:/home/hadoop/apps/
scp -r spark/ mini2:/home/hadoop/apps/
scp -r spark/ mini3:/home/hadoop/apps/
scp -r spark/ mini4:/home/hadoop/apps/
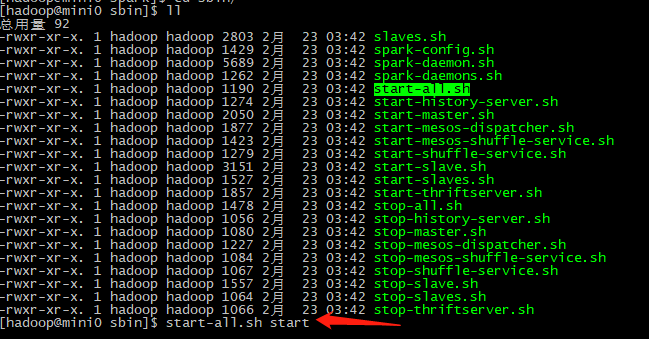
7.如上图,会报错:
-bash: /home/hadoop/apps/hadoop-2.7.5/sbin/start-all.sh: 没有那个文件或目录。
这是因为启动的还是hadoop的start-all.sh, 建议加上绝对位置,如:apps/spark/sbin/start-all.sh
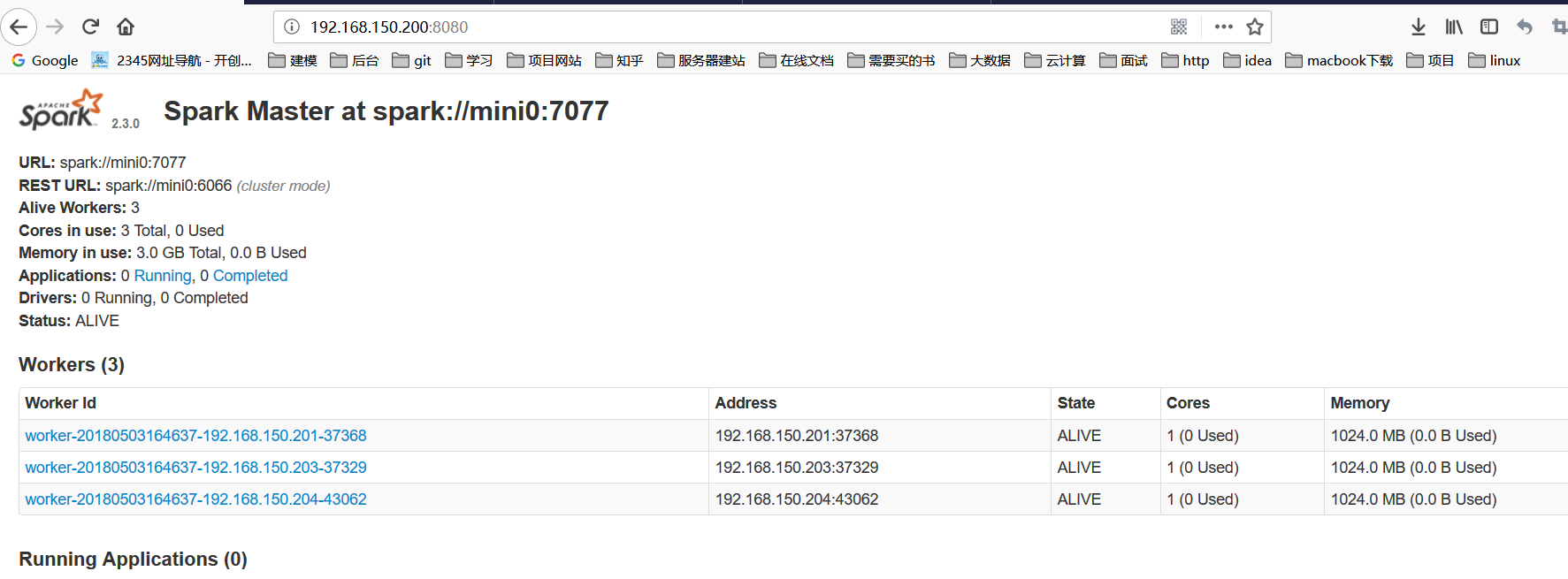
8.启动成功之后,jps查看当前服务,master和worker是否已经启动


9.最后登录web管理页面 master的ip:8080
第二部分-----spark的wordcount
1.进入hadoop的目录,拿LICENSE.txt做wordcount的文件,
2.hadoop fs -put LICENSE.txt /wordcount/input 将LISCENSE.txt文件上传到hdfs的目录/wordclount/input下
通过 hadoop fs -ls /wordcount/input 查看hdfs下的文件

3.进去spark目录, bin/spark-shell
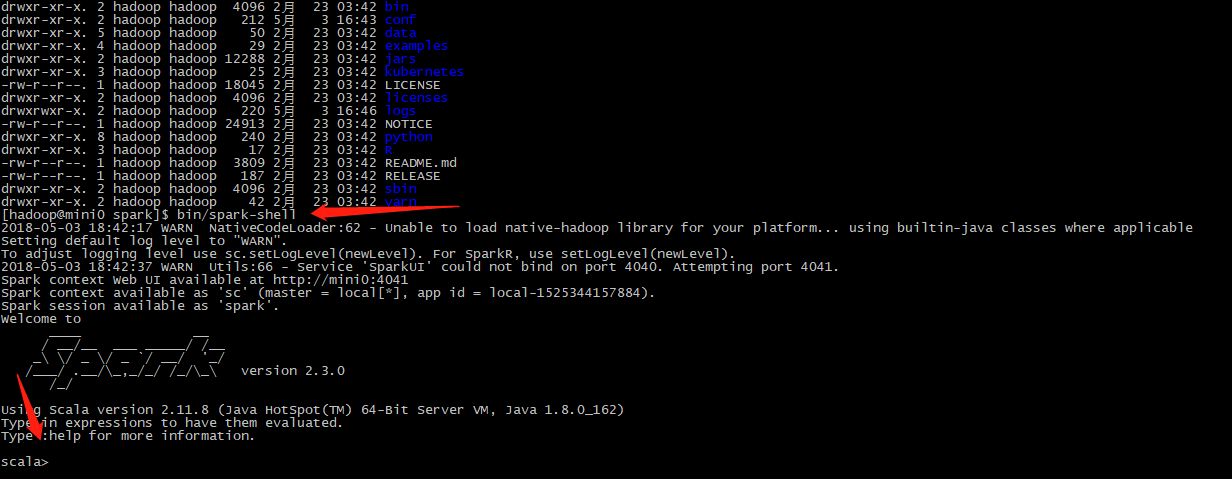
4.执行下面的命令(spark建议使用scala)
sc.textFile("hdfs://mini0:9000/wordcount/input/LICENSE.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("hdfs://mini0:9000/wordcount/out")

5.退出scala,执行 hadoop fs -ls /wordcount/out

6.执行 hadoop fs -cat /wordcount/out/part-00000(例如:absolutely 这个单词出现了4次)
