文章目录
在此文章 《基于Centos7.5完整部署分布式Hadoop3.1.2》里,已经给出详细的hadoop和yarn的部署过程,既然已经解决了大数据开发中“hdfs”的数据存储部署,那么就要考虑如何基于底层分布式文件基础上运行计算框架,以便进行更高层次的应用开发。在本篇文章中,将给出完整部署spark计算框架集群。
1、spark版本(仅列出spark相关)
spark-2.4.4-bin-hadoop2.7,该版本的spark支持hadoop2.7以及之后的版本
scala-2.13.1:使用Scala语言开发数据处理逻辑,当然也可使用python进行spark数据处理逻辑开发,官网有给出pyspark相关指导教程。
三台节点都需要配置,目录放置路径:
[root@nn opt]# ls
hadoop-3.1.2 jdk1.8.0_161 scala-2.13.1 spark-2.4.4-bin-hadoop2.7
spark HA集群规划,这里只列出spark HA集群的有关进程,hadoop的进程不再列出
| IP,hostname | spark集群中负责的角色 | Spark 路径 | Scala路径 | 物理内存 |
|---|---|---|---|---|
| 192.188.0.4,nn | master,worker,spark-history-server | /opt/spark-2.4.4-bin-hadoop2.7 | /opt/scala-2.13.1 | 2G |
| 192.188.0.5,dn1 | master,worker | /opt/spark-2.4.4-bin-hadoop2.7 | /opt/scala-2.13.1 | 1G |
| 192.188.0.6,dn2 | master,worker | /opt/spark-2.4.4-bin-hadoop2.7 | /opt/scala-2.13.1 | 1G |
这里spark master节点nn的物理内存给了2G,因为该节点不仅仅启动了spark相关主服务,还得启动hadoop相关主服务,如果物理内存不足,在后面章节中启动spark-shell或者跑application都无法正常启动,提示资源不足。
2、设置path环境
三个节点都需要设置
[root@nn opt]# vi /etc/profile
export JAVA_HOME=/opt/jdk1.8.0_161
export HADOOP_HOME=/opt/hadoop-3.1.2
export SCALA_HOME=/opt/scala-2.13.1
export SPARK_HOME=/opt/spark-2.4.4-bin-hadoop2.7/
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SPARK_HOME/bin:$SCALA_HOME/bin:
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
3、配置spark集群的相关文件
# 拷贝一份spark-env.sh文件用于配置spark环境
[root@dn1 ~]# cp /opt/spark-2.4.4-bin-hadoop2.7/conf/spark-env.sh.template /opt/spark-2.4.4-bin-hadoop2.7/conf/spark-env.sh
[root@dn1 ~]# cd /opt/spark-2.4.4-bin-hadoop2.7/
[root@dn1 spark-2.4.4-bin-hadoop2.7]# ls conf/
docker.properties.template slaves.template
fairscheduler.xml.template spark-defaults.conf.template
log4j.properties.template spark-env.sh
metrics.properties.template spark-env.sh.template
[root@dn1 spark-2.4.4-bin-hadoop2.7]# vi conf/spark-env.sh
只需在spark-env.sh文件头部加入以下环境变量
export SCALA_HOME=/opt/scala-2.12.8
export JAVA_HOME=/opt/jdk1.8.0_161
# 设定192.188.0.4,nn节点为spark master
export SPARK_MASTER_IP=nn
export SPARK_WORKER_MEMORY=1g
# hadoop的配置文件**site.xml所在目录
export HADOOP_CONF_DIR=/opt/hadoop-3.1.2/etc/hadoop
修改conf目录下的slaves文件
[root@dn1 conf]# pwd
/opt/spark-2.4.4-bin-hadoop2.7/conf
[root@dn1 conf]# cp slaves.template slaves
[root@dn1 conf]# vi slaves
dn1
dn2
为减少spark主节点nn的内存资源消耗,这里不再将nn设为Worker角色
将修改过的两个文件拷贝到其他两个节点
[root@dn1 spark-2.4.4-bin-hadoop2.7]# scp -r conf/ dn1:/opt/spark-2.4.4-bin-hadoop2.7/
[root@dn1 spark-2.4.4-bin-hadoop2.7]# scp -r conf/ dn2:/opt/spark-2.4.4-bin-hadoop2.7/
4、启动spark集群进程
4.1 启动spark-master进程
spark的进程启动是有步骤的,需先启动master服务,再启动worker进程,因为worker启动需要通过spark://nn:7077 spark协议的7077端口与master节点通信,否则master节点和worker之间无法形成集群。
[root@nn sbin]# ./start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /opt/spark-2.4.4-bin-hadoop2.7//logs/spark-root-org.apache.spark.deploy.master.Master-1-nn.out
# nn节点上
[root@nn sbin]# jps
24292 DataNode
24155 NameNode
25339 NodeManager
30638 Master
30750 Jps
# dn1节点上:
[root@dn1 ~]# jps
18480 Jps
12805 ResourceManager
12365 DataNode
12942 NodeManager
# dn2节点上:
[root@dn2 ~]# jps
13144 DataNode
13244 SecondaryNameNode
19437 Jps
13599 NodeManager
以上表示主节点已经启动Master进程,其他节点dn1和dn2还未启动Worker进程。可以通过log日志文件内容看到其启动过程,这里不再给出,当然更直观的方式是在web端查看:页面http://nn:8080/或者http://192.188.0.4:8080可以直观看到master状态,此时workers还未启动,可以按到显示workers数量为0
4.2 在spark master启动后,启动Worker节点
在spark主节点上nn,启动workers,这些workers的对应的节点就是路径/opt/spark-2.4.4-bin-hadoop2.7/conf下slaves文件配置到2个节点:dn1,dn2。
-
启动spark集群上所有的workers节点命令:start-slaves.sh
-
启动本节点上的work进程:start-slave.sh
-
可以对比其shell脚本的差别,在start-slaves.sh脚本后面可以看到
"${SPARK_HOME}/sbin/start-slave.sh" "spark://$SPARK_MASTER_HOST:$SPARK_MASTER_PORT"
start-slaves.sh其实是在其他节点运行./start-slave.sh spark://nn:7077实现批量启动其他work节点
[root@nn sbin]# pwd
/opt/spark-2.4.4-bin-hadoop2.7/sbin
[root@nn sbin]# ./start-slaves.sh
dn1: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark-2.4.4-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-dn1.out
dn2: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark-2.4.4-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-dn2.out
# # nn节点上spark Master
[root@nn sbin]# jps
24292 DataNode
24155 NameNode
25339 NodeManager
30638 Master
30750 Jps
# dn1节点上spark Worker进程
[root@dn1 ~]# jps
12805 ResourceManager
23045 Jps
23000 Worker
12365 DataNode
12942 NodeManager
# dn2节点上spark Worker进程
[root@dn2 ~]# jps
24789 Worker
24837 Jps
13144 DataNode
13244 SecondaryNameNode
13599 NodeManager
在spark的master web端:http://nn:8080或者http://192.188.0.4:8080可以看到2个worker均active
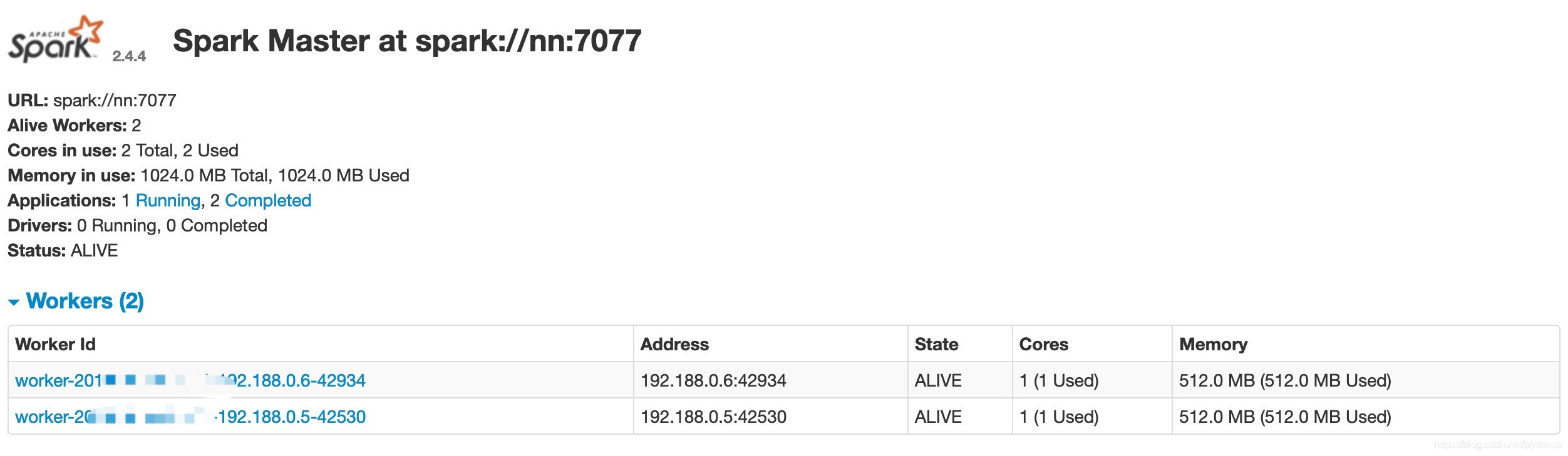 每个worker的最大可用内存512m,vCPU 1颗
每个worker的最大可用内存512m,vCPU 1颗
5、设置启动spark-shell的默认环境(非常关键的配置)
5.1 配置spark-defaults.conf
注意,在启动spark-shell之前,如果需要对/opt/spark-2.4.4-bin-hadoop2.7/conf目录下的配置文件:spark-defaults.conf.template相关参数进行修改,例如需要结合spark-history-server的配置,那么除了新建一份spark-defaults.conf,还需要对里面参数正确,否则启动spark-shell会提示出错并退出
因为本文测试使用2G内存,所以需要对配置文件里面做修改,修改如下
[root@nn conf]# cp spark-defaults.conf.template spark-defaults.conf
[root@nn conf] spark-defaults.conf
# spark集群主节点的入口
spark.master spark://nn:7077
spark.eventLog.enabled true
# 在hadoop core-site.xml设置的hdfs入口地址,directory需自行在hdfs文件系统上创建
# 通过命令可创建:hdfs dfs -mkdir /directory
# 同时日志目录作为spark-history-server的日志目录
spark.eventLog.dir hdfs://nn:9000/directory
spark.serializer org.apache.spark.serializer.KryoSerializer
# spark主节点driver内存,默认为5G,这里设为1g
spark.driver.memory 1g
spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
如果以上入口地址设错,或者未在namenode节点的hdfs文件系统上创建directory目录,都会导致无法启动spark-shell
若不对spark-defaults.conf.template参数修改,例如不需要启动history服务,则无需创建spark-defaults.conf文件,也无需进行上述设置,可以直接启动spark-shell
5.2 spark-defaults.conf的详细的设置
参考官网配置指引
其实该配置就是用来spark集群调优的关键配置
主要分为几大部分的参数配置:
- Application Properties
- Runtime Environment
- Spark UI
- Compression and Serialization
- Memory Management
- Execution Behavior
- Networking
- Scheduling
- Dynamic Allocation
5.3 启动spark-shell
首次启动spark-shell时,会出现‘WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform’的提示,参考文章提示:centos预装的glibc库是2.17版本,而hadoop期望是2.14版本,可以忽略该警告,在hadoop日志配置文件设置:
[root@dn2 ~]# vi /opt/hadoop-3.1.2/etc/hadoop/log4j.properties
# 新增以下内容
log4j.logger.org.apache.hadoop.util.NativeCodeLoader=ERROR
# 启动成功提示
[root@nn bin]# spark-shell
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://nn:4040
Spark context available as 'sc' (master = spark://nn:7077, app id = app-2019*****-0004).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.4
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_161)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
可以在http://nn:4040查看,若有计算任务提交,可以直观查看spark job 、excutors等进度,参考官方说明:
Every SparkContext launches a web UI, by default on port 4040, that displays useful information about the application. This includes:
- A list of scheduler stages and tasks
- A summary of RDD sizes and memory usage
- Environmental information.
- Information about the running executors
但以上启动是有问题的,表面上看,spark-shell已正常启动,但测试机器最大内存为2G,启动spark-shell若不限定executor-memory内存使用(默认值1G)那么在执行计算任务时,spark-shell会一直提示 scheduler资源不足:
WARN scheduler.TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient memory
导致job一直waiting状态
解决办法:
启动spark-shell限制相关资源的使用:
spark-shell --executor-memory 512m --total-executor-cores 3 --executor-cores 1
6、在spark-shell交互式计算words
6.1 存放words的文件已经上传到hdfs文件系统上的/app目录下
[root@nn sbin]# hdfs dfs -ls /app
Found 2 items
-rw-r--r-- 3 root supergroup 41 ** /app/title.txt
-rw-r--r-- 3 root supergroup 76 ** /app/words.txt
# title.txt内容:
hadoop spark zookeeper
spark zookeeper
# words.txt内容:
foo is foo
bar is not bar
hadoop file system is the infrastructure of big data
6.2带参数启动spark-shell
[root@dn1 ~]# spark-shell --master spark://nn:7077 --executor-memory 512m --total-executor-cores 3 --executor-cores 1 --num-executors 2
# SparkContext,也可以在web端查看http://nn:4040
scala> sc
res2: org.apache.spark.SparkContext = org.apache.spark.SparkContext@e71bd92
# 统计hdfs目录/app下所有文件里面words,scala语言的链式调用
scala> sc.textFile("hdfs://nn:9000/app").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).sortBy(_._2,false).collect
# 统计结果返回一个scala数组
res0: Array[(String, Int)] = Array((is,3), ("",2), (bar,2), (foo,2), (spark,2), (hadoop,2), (zookeeper,2), (not,1), (system,1), (big,1), (infrastructure,1), (the,1), (data,1), (file,1))
或者在此spark-shell上交互式使用Scala写简单的统计语句
scala> val file=sc.textFile("hdfs://nn:9000/app")
file: org.apache.spark.rdd.RDD[String] = hdfs://nn:9000/app MapPartitionsRDD[21] at textFile at <console>:24
scala> val rdd = file.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey(_+_).sortBy(_._2,false)
rdd: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[29] at sortBy at <console>:25
scala> rdd.collect()
res6: Array[(String, Int)] = Array((is,3), ("",2), (bar,2), (foo,2), (hadoop,2), (zookeeper,2), (spark,2), (not,1), (system,1), (data,1), (file,1), (big,1), (infrastructure,1), (the,1))
7、使用spark的相关web服务页面查看application执行计算作业的详细过程(非常重要)
下面以一个Application 执行job前和执行job后的页面来说明application,job,task等内容
Application 执行job前
A、查看application执行的详情页面
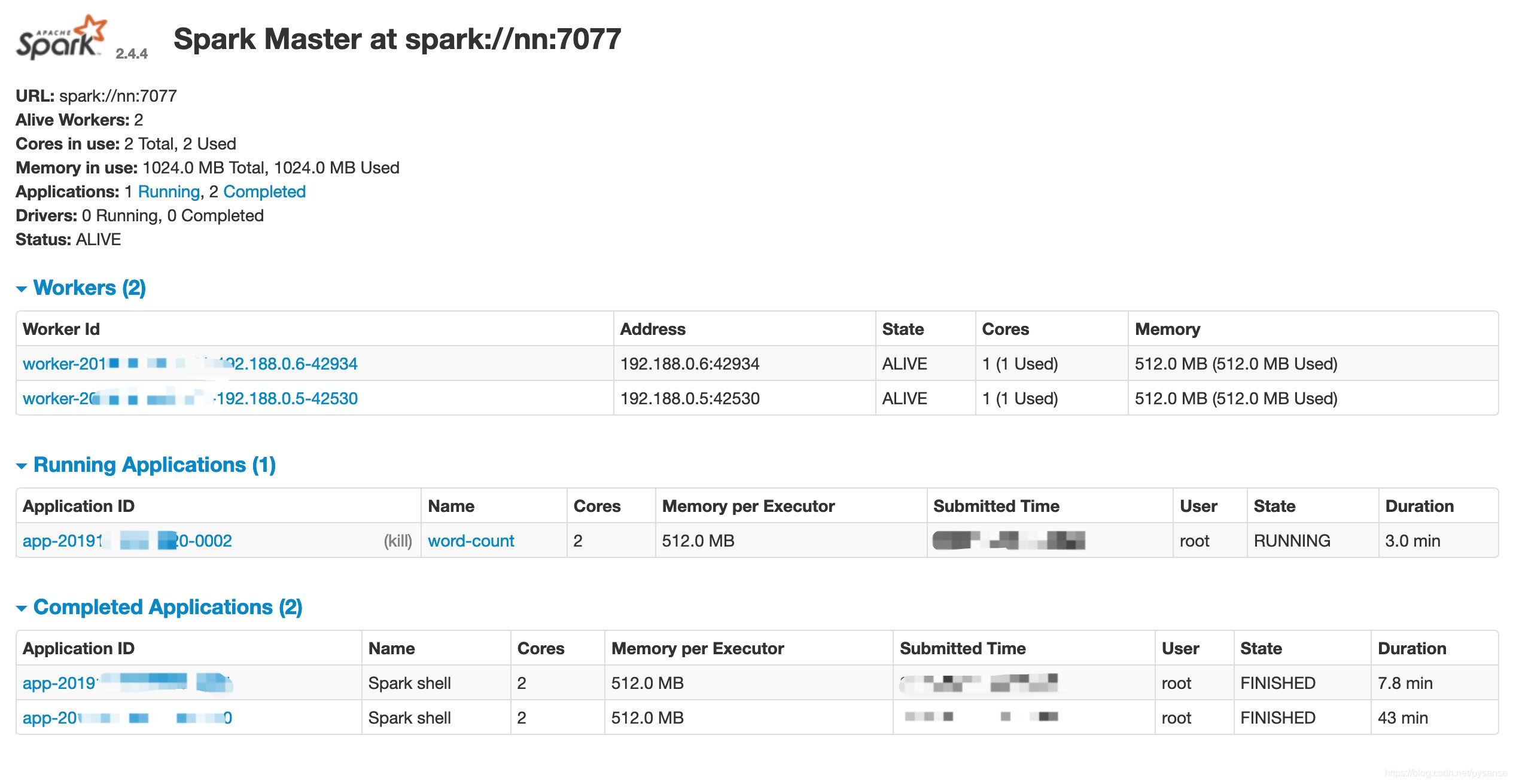
在nn节点上,启动一个名字为word-count的application:
[root@nn sbin]# spark-shell --executor-memory 512m --total-executor-cores 3 --executor-cores 1 --num-executors 2 --name word-count
在spark-shell启动后,会提示:
Spark context Web UI available at http://nn:4040
Spark context available as ‘sc’ (master = spark://nn:7077, app id = app-2019*****-0002).
http://nn:4040针对当前运行application的job详情,如果执行统计命令后退出spark-shell,那么web服务退出,http://nn:4040将无法访问,也即无法查看当前application执行过程的情况,所有需要配置application 的spark-history-server,用来查看之前已经完成或者未完成的application情况的历史记录
http://nn:4040页面:
app id = app-2019*-0002Jobs栏目内容:
可以看到目前该application没有job需要执行
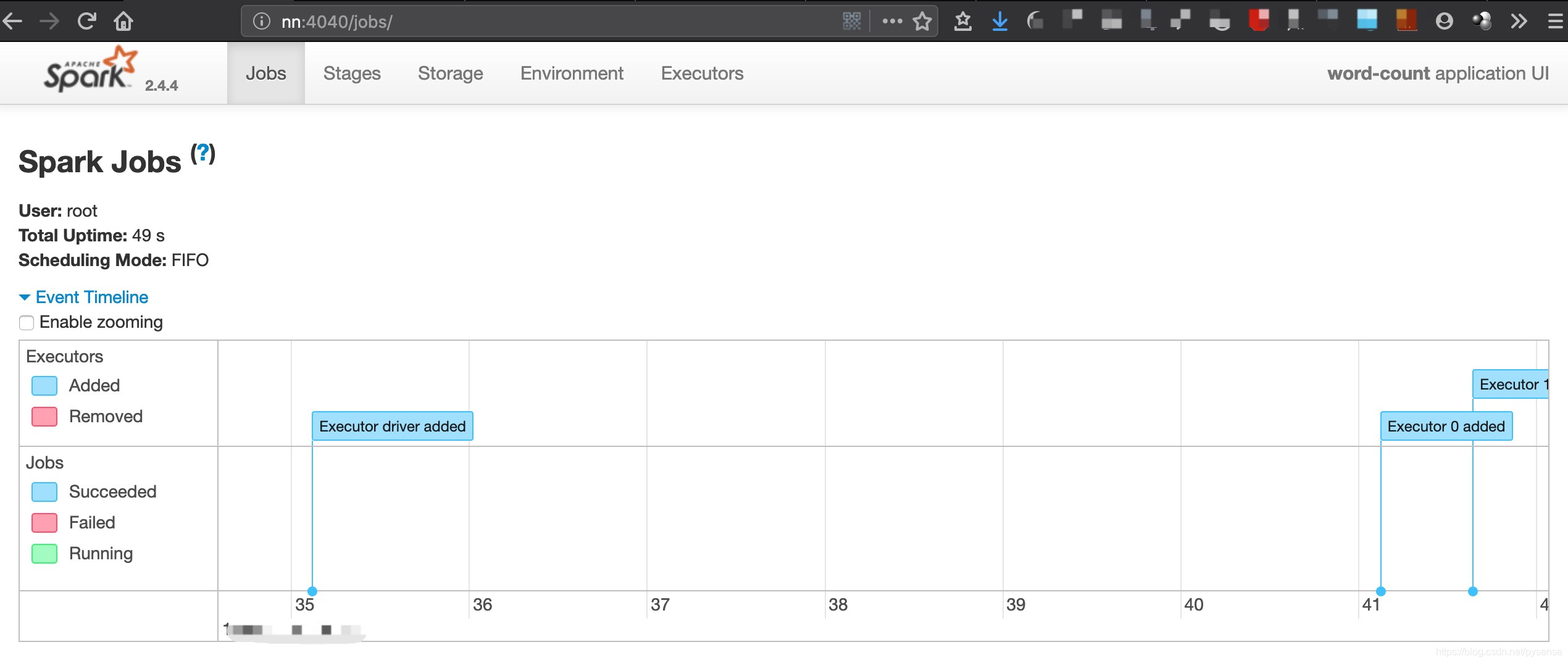 app id = app-2019*-0002的executor内容:
app id = app-2019*-0002的executor内容:
该application分配了两个executor,分别为dn1节点和dn2节点,nn节点则作为driver
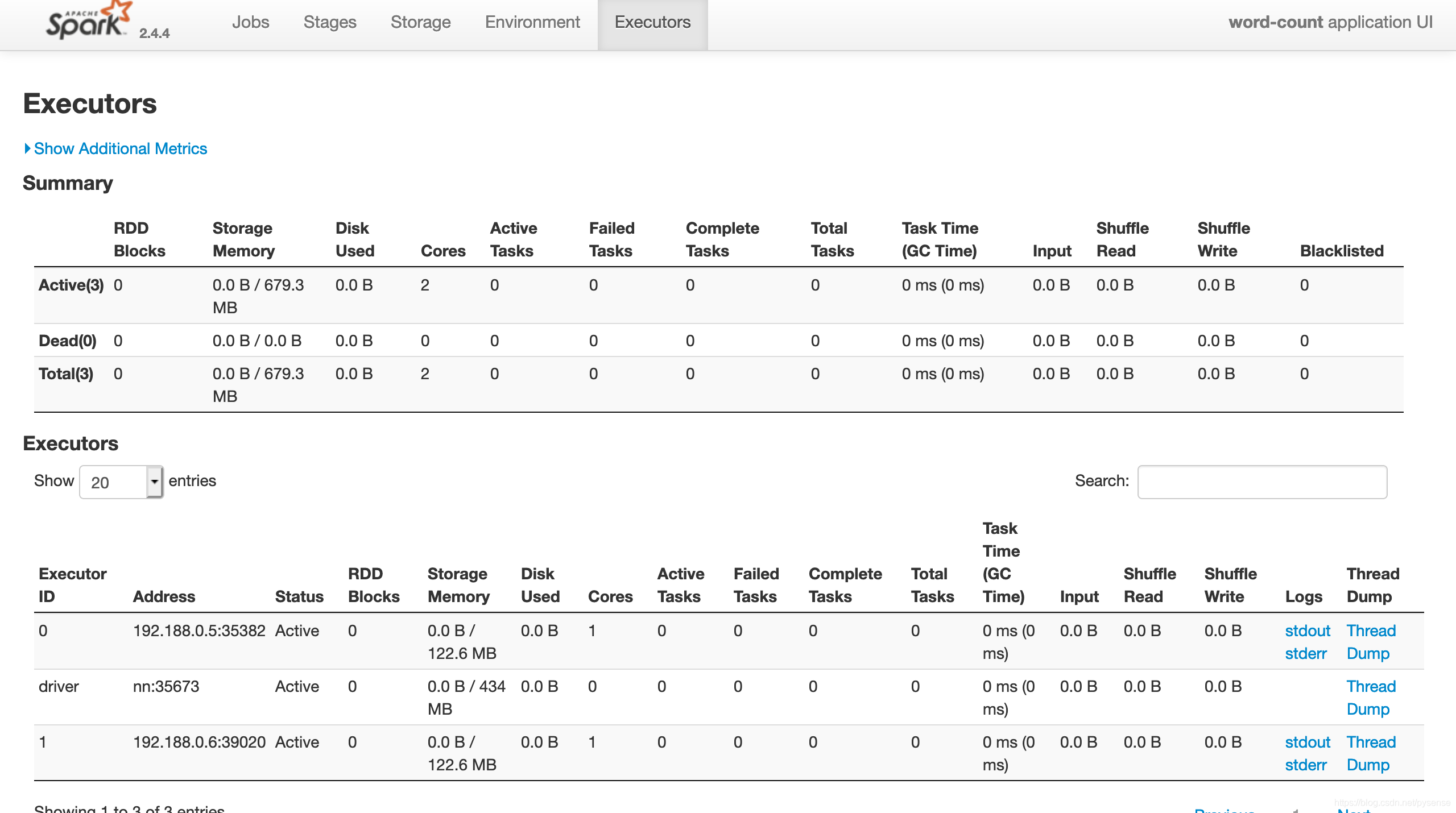 B、查看所有正在完成、已完成的application管理页面:spark master:http://nn:8080
B、查看所有正在完成、已完成的application管理页面:spark master:http://nn:8080
该页面可以看到spark集群的资源分配情况、worker情况、正在runing的application以及已经完成的application
C、在A部分提到如果要回看已经完成application运行情况,则需要启动spark-history-server,这里给出配置文件说明
配置Spark History Server服务
history只需在spark主节点上配置,无需在其他两个节点上配置。
spark-history-server其实就是一个web服务,spark.eventLog.dir存放所有application事件日志,web服务通过把这些application运行日志内容以web UI提供查看
[root@nn conf]# vi spark-env.sh
# 从配置说明可以看出,所有配置hisory服务的属性值可由以下属性设定
# - SPARK_HISTORY_OPTS, to set config properties only for the history server (e.g. "-Dx=y")
# 配置history日志存放目录,可以配置多个属性值
SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=9001
-Dspark.history.retainedApplications=5
-Dspark.history.fs.logDirectory=hdfs://nn:9000/directory"
web访问端口为9001,保留最近5个application的日志,application的日志存放在hdfs://nn:9000/directory
其他配置项
其他相关参数:
| Property Name | Default | Meaning |
|---|---|---|
| spark.history.fs.update.interval | 10s | 文件系统历史提供程序在日志目录中检查新日志或更新日志的周期。较短的间隔可以更快地检测新应用程序,但代价是需要更多的服务器负载重新读取更新的应用程序。一旦更新完成,已完成和未完成的应用程序的清单将反映更改 |
| spark.history.retainedApplications | 50 | 在缓存中保留UI数据的应用程序数量。如果超过这个上限,那么最老的应用程序将从缓存中删除。如果应用程序不在缓存中,则必须从磁盘加载它(如果是从UI访问它) |
| spark.history.fs.cleaner.enabled | false | 是否周期性的删除storage中的event log(生产必定是true) |
| spark.history.fs.cleaner.interval | 1d | 多久删除一次 |
| spark.history.fs.cleaner.maxAge | 7d | 每次删除多久的event log,配合上一个参数就是每天删除前七天的数据 |
spark-history页面截图:
 Application 执行job后
Application 执行job后
当application开始runing后,可以看到相关job运行情况
A、application的jobs图示
该word-count app启动了两个job
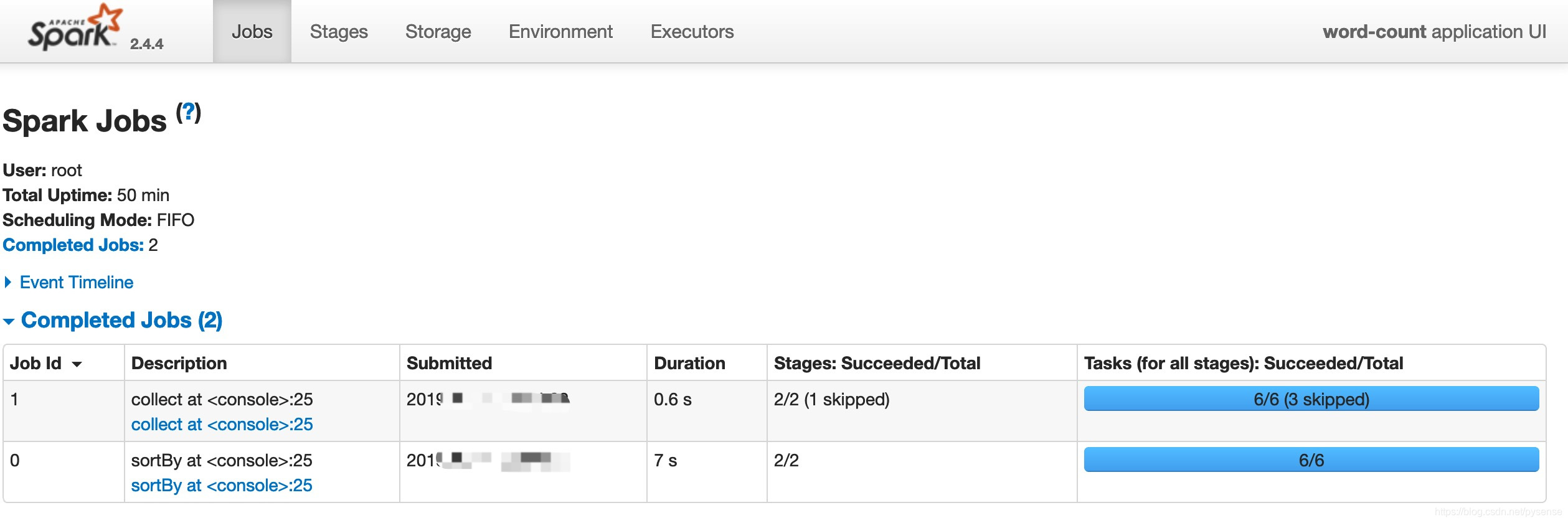
job-0主要负责作业中Transformation链操作:
sc.textFile("hdfs://nn:9000/app").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).sortBy(_._2,false)
job-0分解
job-1负责作业最后阶段Action操作:
.collect
application、job、stage、task构成关系
这里job-1的stage2是skip的,因为job-0已经完成了同样的操作,其他job无法重复执行。
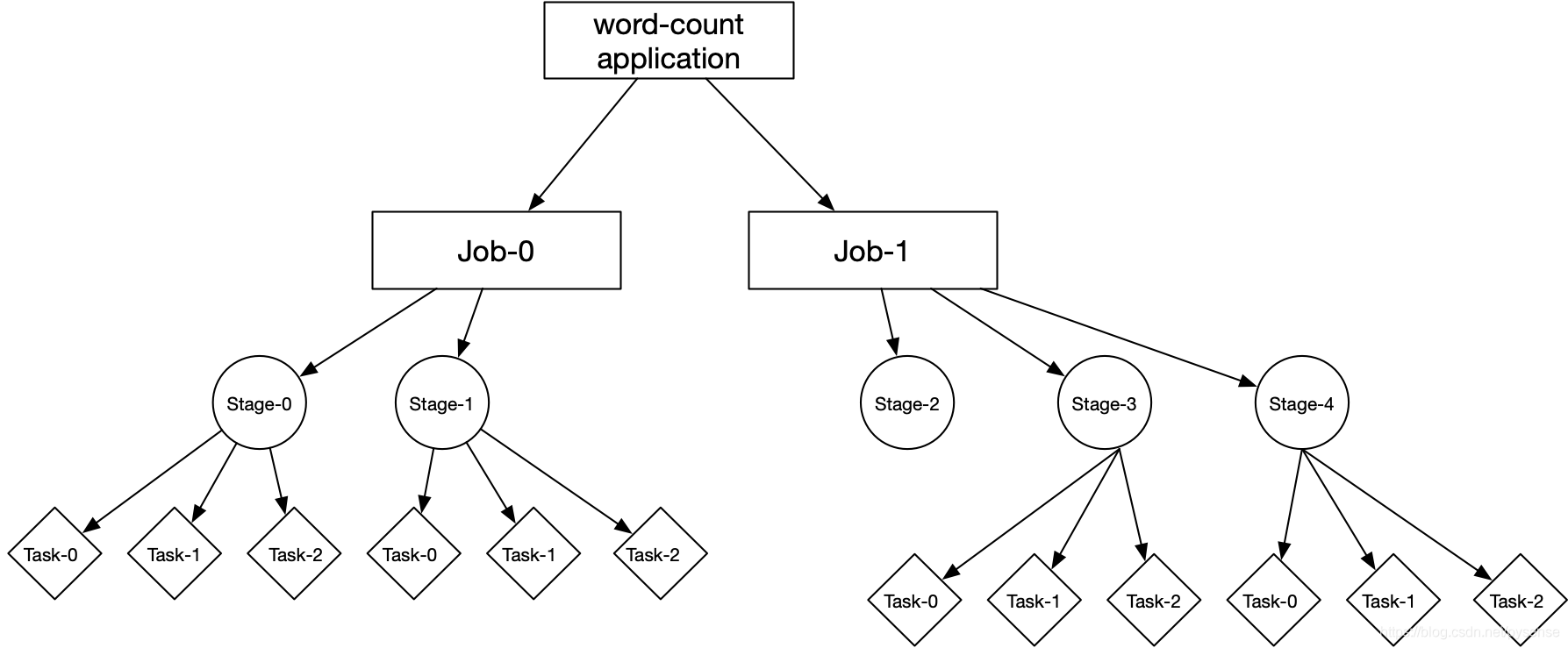 B、job-0、job-1对于的stage图
B、job-0、job-1对于的stage图
job-0:stage-0和stage-1
 job-1:stage-2、stage-3、stage-4
job-1:stage-2、stage-3、stage-4
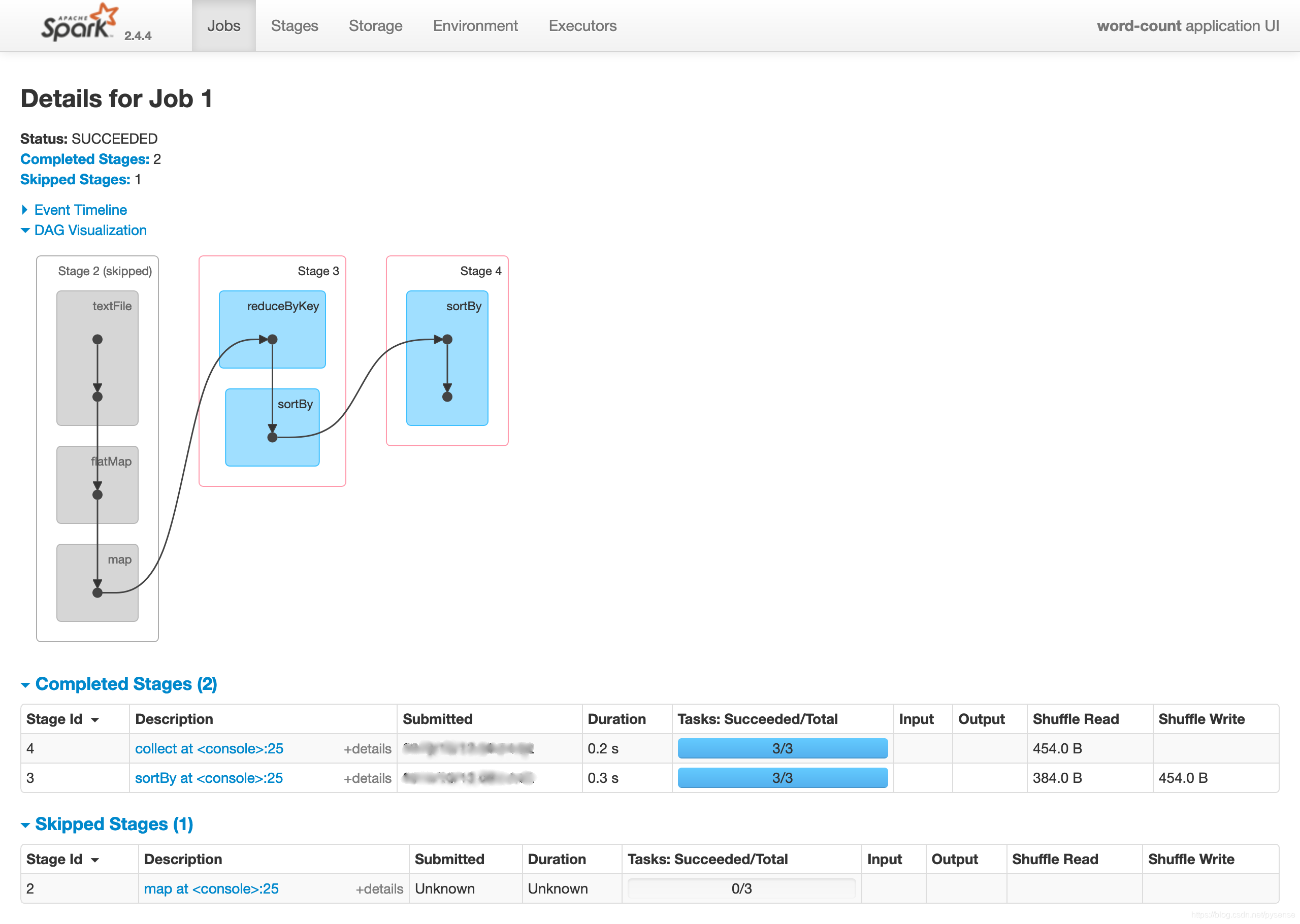
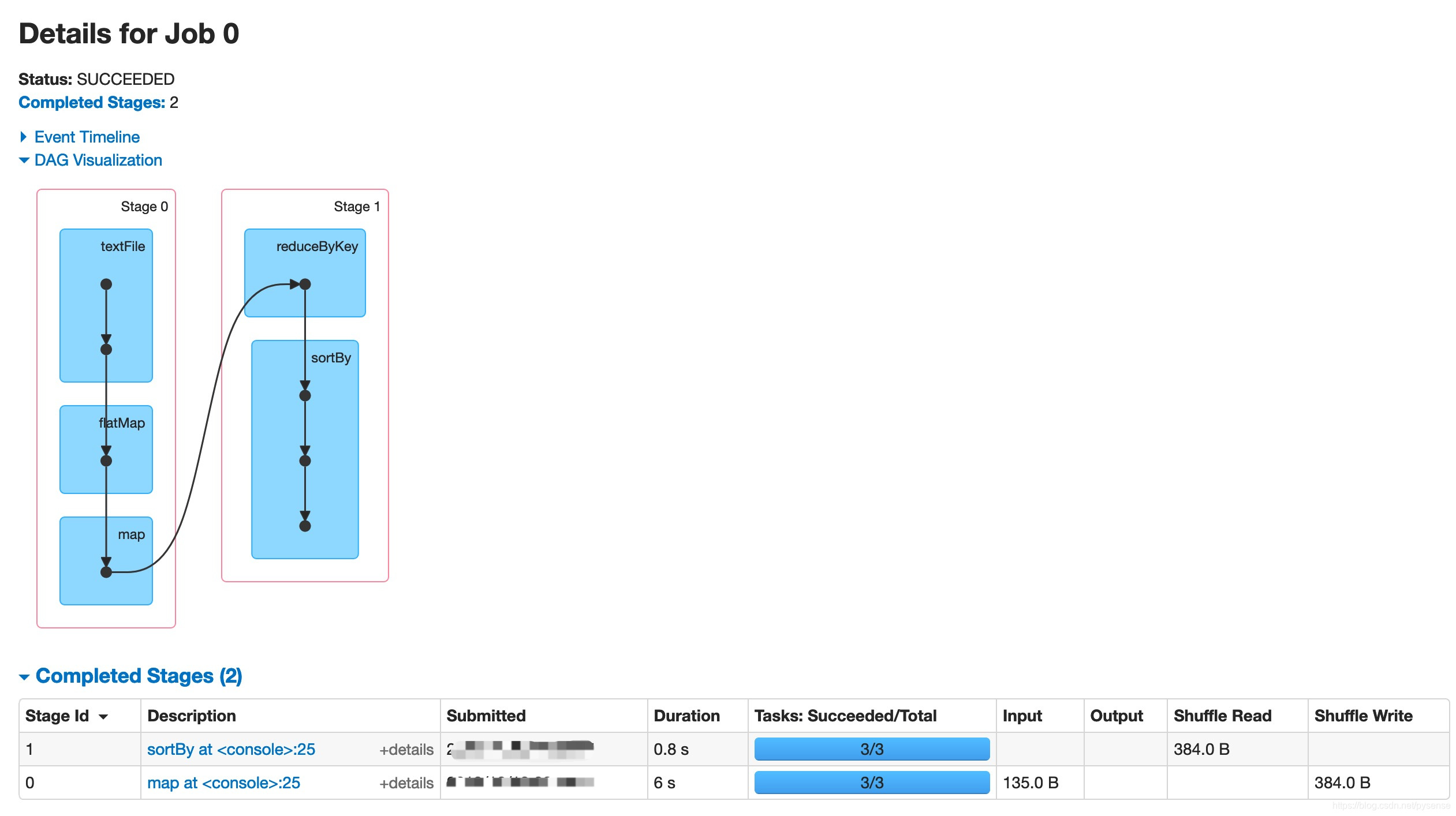
C、以job-0为例:stage-0和stage-1的具体任务执行图DAG调度过程
job-0:stage-0,其实就是map阶段,对应shuffle write
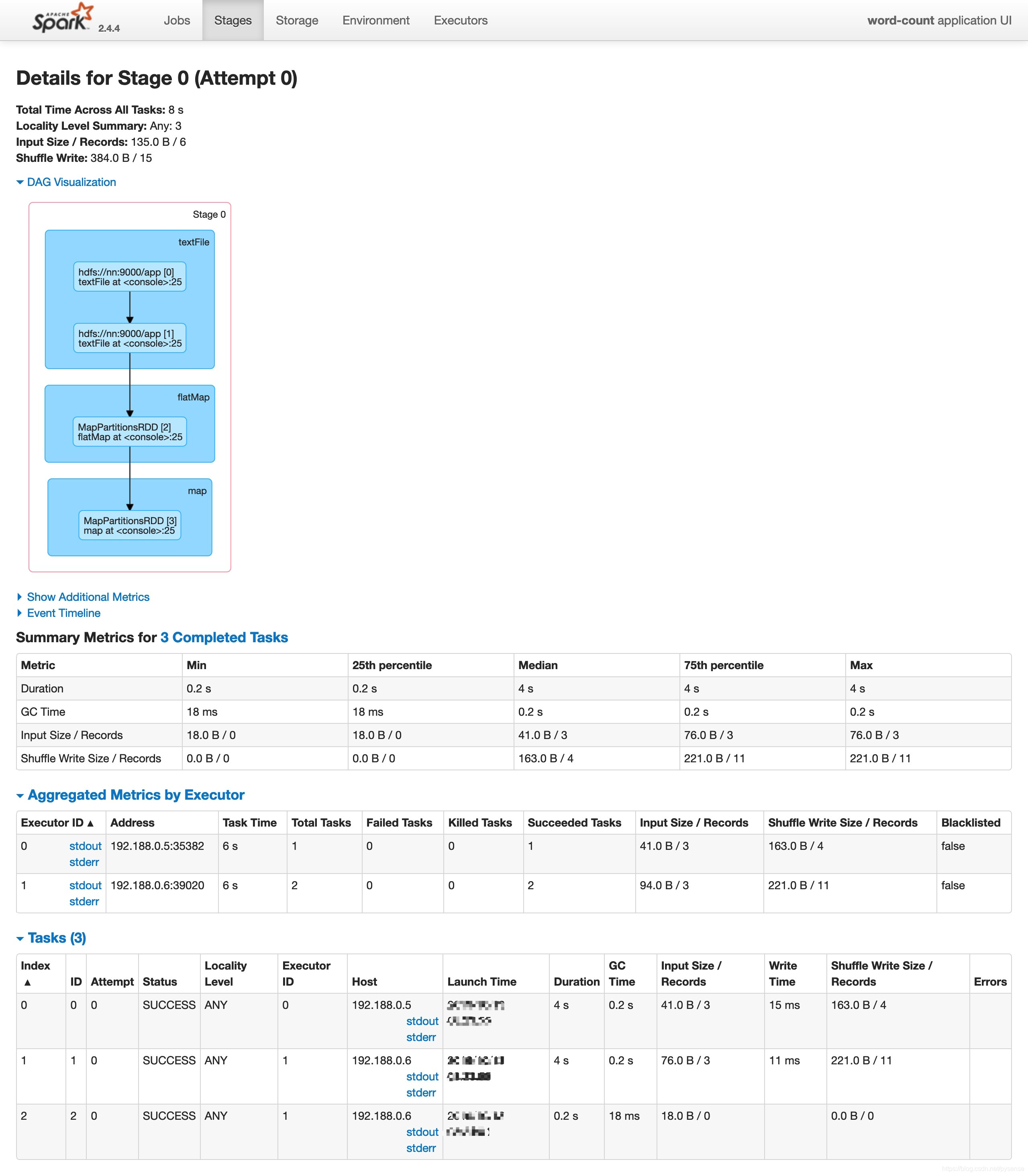
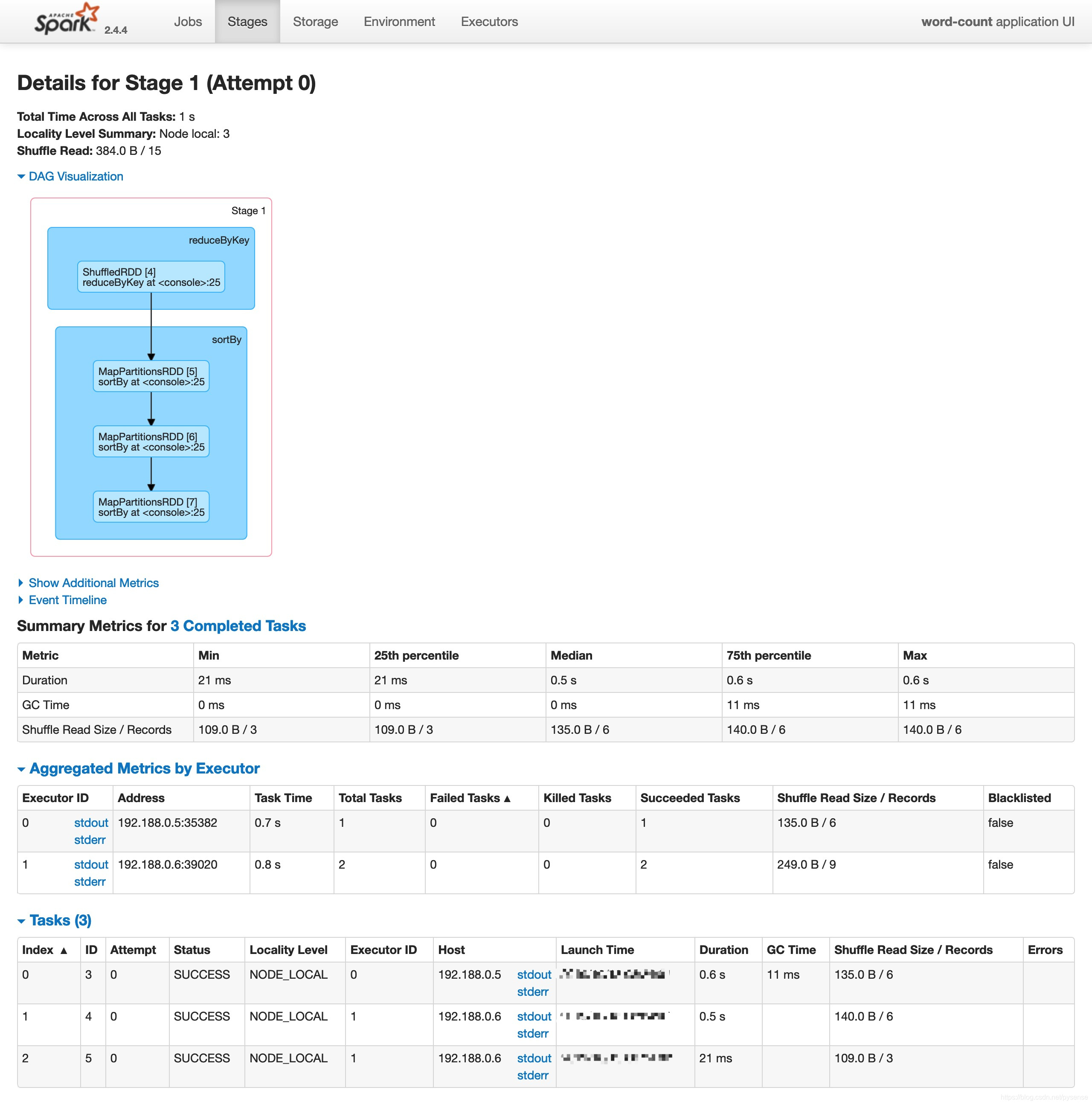
job-1:stage-1,其实就是reduce阶段,对应shuffle read
8、启动spark HA集群
前面的测试都是基于一个master带2个slave节点的集群,若nn节点上的master进程挂了,显然无法达到高可用集群,因此本章节也给出其配置过程,后面多篇文章会有大数据实时项目相关组件的部署,全部组件都基于HA方式运行,近可能贴近生产环境。
spark HA集群基于zookeeper集群实现,因此需要环境配置好并启动zookeeper服务,这里不再累赘,可以参考本人blog中有关zk集群的配置过程。
8.1 配置文件
spark HA配置相对简单,改动三个文件: spark-defaults.conf,slaves,spark-env.sh
将三个节点spark-defaults.conf都做以下配置:
[root@nn conf]# pwd
/opt/spark-2.4.4-bin-hadoop2.7/conf
[root@nn conf] vi spark-defaults.conf
# 因为spark要配成HA模式,因此不再指定nn节点为active节点
#spark.master spark://nn:7077
spark.eventLog.enabled true
# 注意这里eventLog.dir,因为本文中hadoop 集群还不是HA模式,NameNode主节点仅有nn节点,因此设为nn:9000。若hadoop集群为HA模式,这里的路径需要设为 :hdfs://hdapp/directory。在后面的spark on yarn 文章也还会提到这一点。
spark.eventLog.dir hdfs://nn:9000/directory
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 512m
spark.driver.cores 1
spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
将3个节点都为加入到slaves文件,每个节点都需配置该slaves文件。
[root@dn1 conf]# pwd
/opt/spark-2.4.4-bin-hadoop2.7/conf
[root@dn1 conf]# cp slaves.template slaves
[root@dn1 conf]# vi slaves
nn
dn1
dn2
更改spark-env.sh
export SCALA_HOME=/opt/scala-2.12.8
export JAVA_HOME=/opt/jdk1.8.0_161
# spark HA配置里,不再指定某个节点为master
#export SPARK_MASTER_IP=182.10.0.4
export SPARK_WORKER_MEMORY=512m
# 加入zookeeper集群,由zk统一管理
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=nn:2181,dn1:2181,dn2:2181 -Dspark.deploy.zookeeper.dir=/spark"
#hadoop的配置文件**site.xml所在目录
export HADOOP_CONF_DIR=/opt/hadoop-3.1.2/etc/hadoop
在三个节点上都需按以上内容做相同配置。
8.2 启动和测试spark HA
首先启动nn节点上slaves进程,此时三个节点都是worker角色
[root@nn spark-2.4.4-bin-hadoop2.7]# ./sbin/start-slaves.sh
nn: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark-2.4.4-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-nn.out
dn1: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark-2.4.4-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-dn1.out
dn2: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark-2.4.4-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-dn2.out
接着在nn节点上启动master进程,此时nn节点将被选举为active状态
[root@nn spark-2.4.4-bin-hadoop2.7]# ./sbin/start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /opt/spark-2.4.4-bin-hadoop2.7//logs/spark-root-org.apache.spark.deploy.master.Master-1-nn.out
最后,分别在dn1和dn2节点上启动master进程,此时因nn节点已经优先成为active角色,故这两个节点虽然启动master,但会处于standby模式
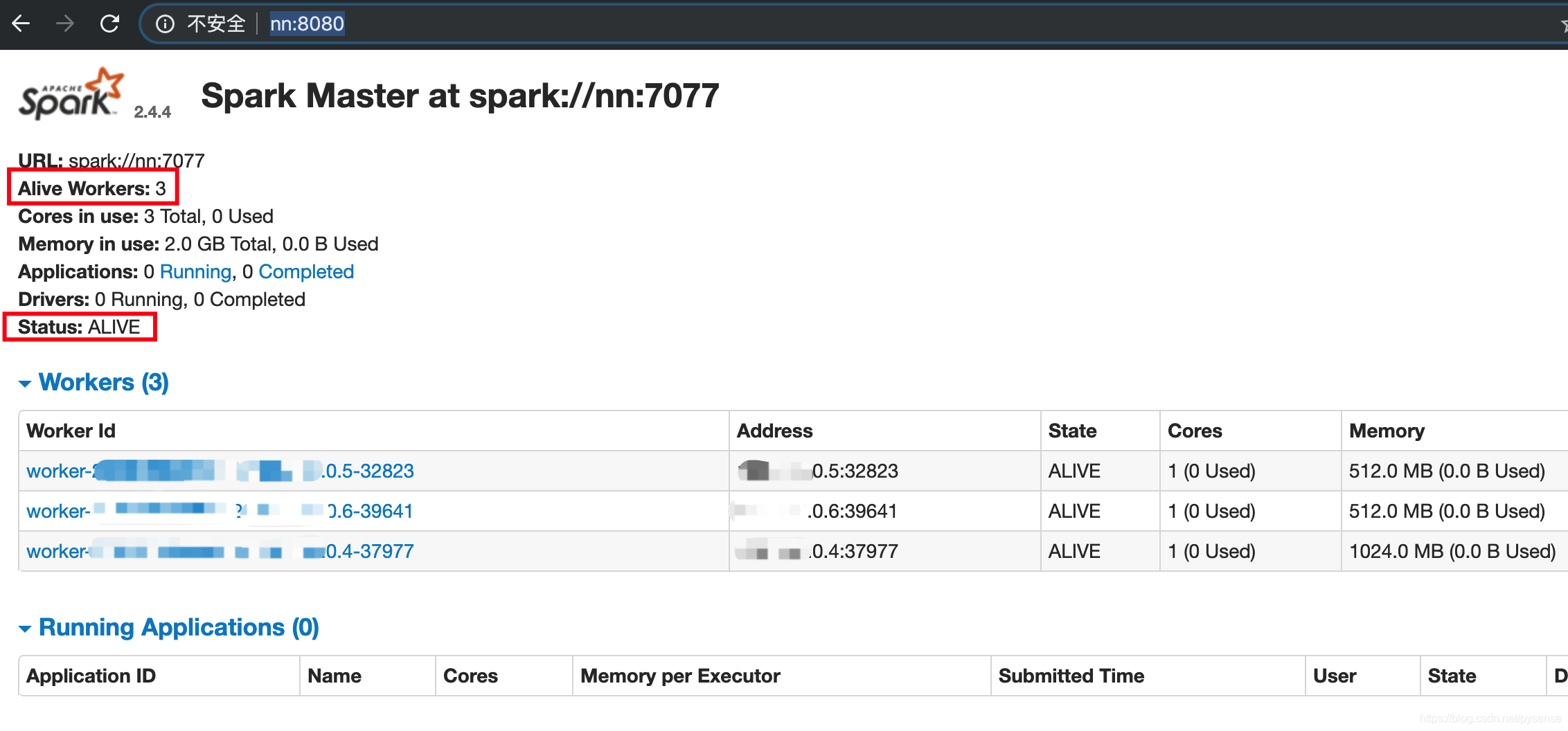
通过spark web UI查看以上集群情况:
首先访问http://nn:8080,可以看到当前nn节点为active状态且有3个alive workers
 访问
访问http://dn1:8080,dn1节点为standby模式,而且无自己的workers
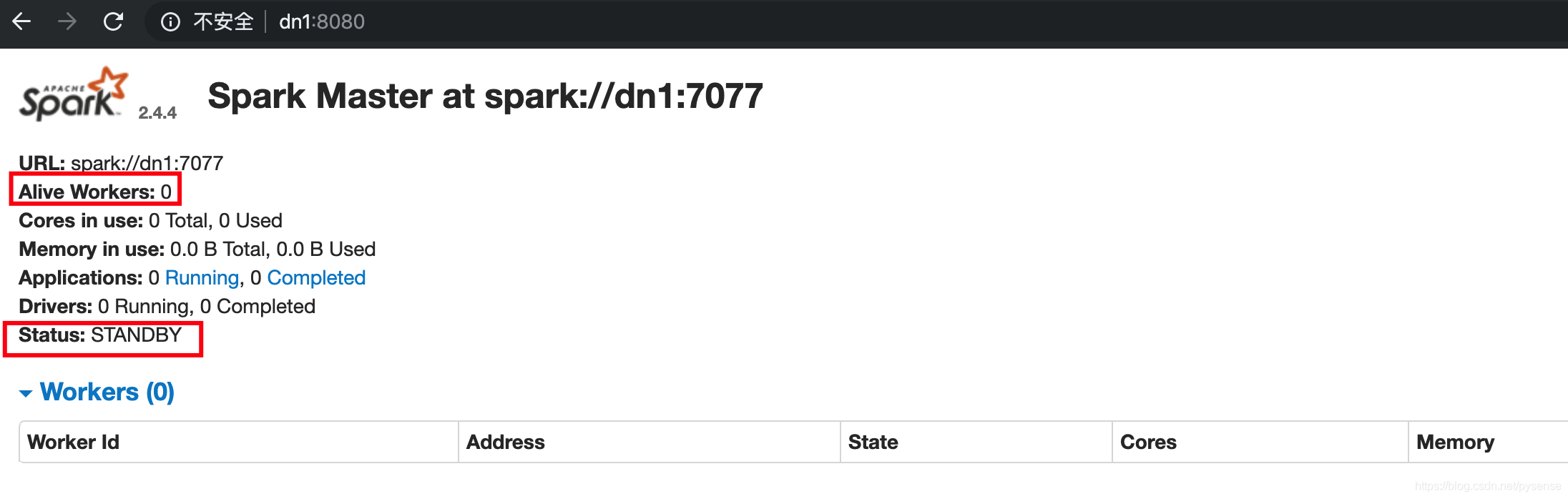 访问
访问http://dn2:8080,dn2节点为standby模式,而且无自己的workers
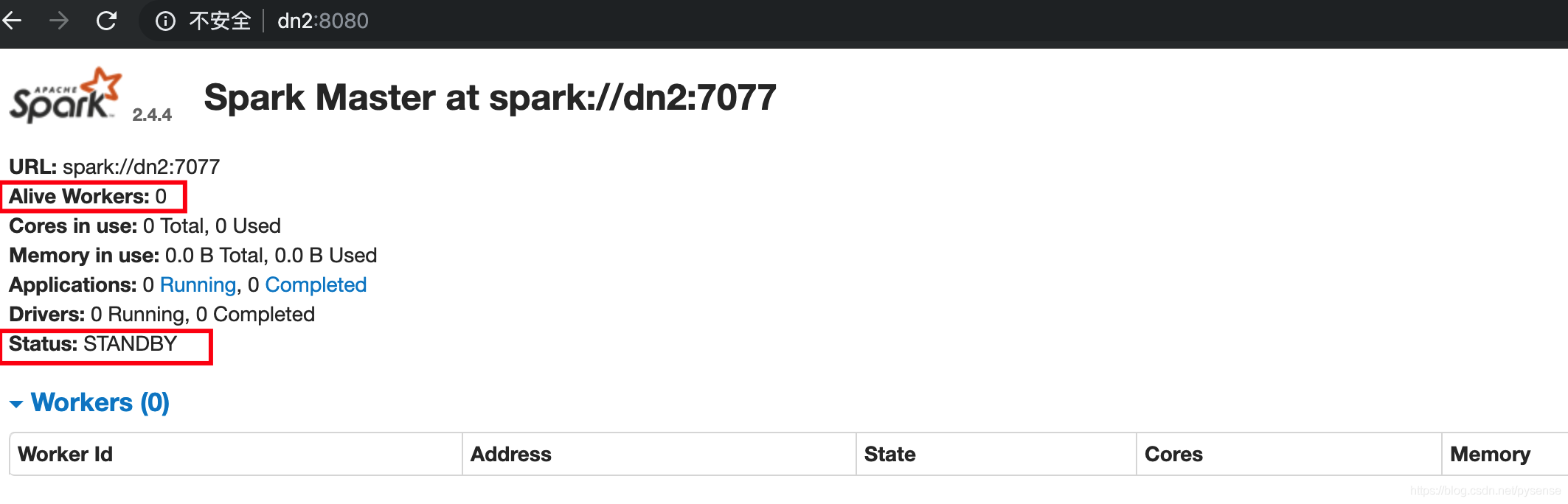 kill掉nn上master进程,观测spark 集群的master切换情况。
kill掉nn上master进程,观测spark 集群的master切换情况。
[root@nn spark-2.4.4-bin-hadoop2.7]# jps
7094 Master
7322 Jps
7019 Worker
4892 QuorumPeerMain
5853 NameNode
5933 DataNode
6253 DFSZKFailoverController
6062 JournalNode
[root@nn spark-2.4.4-bin-hadoop2.7]# kill -9 7094
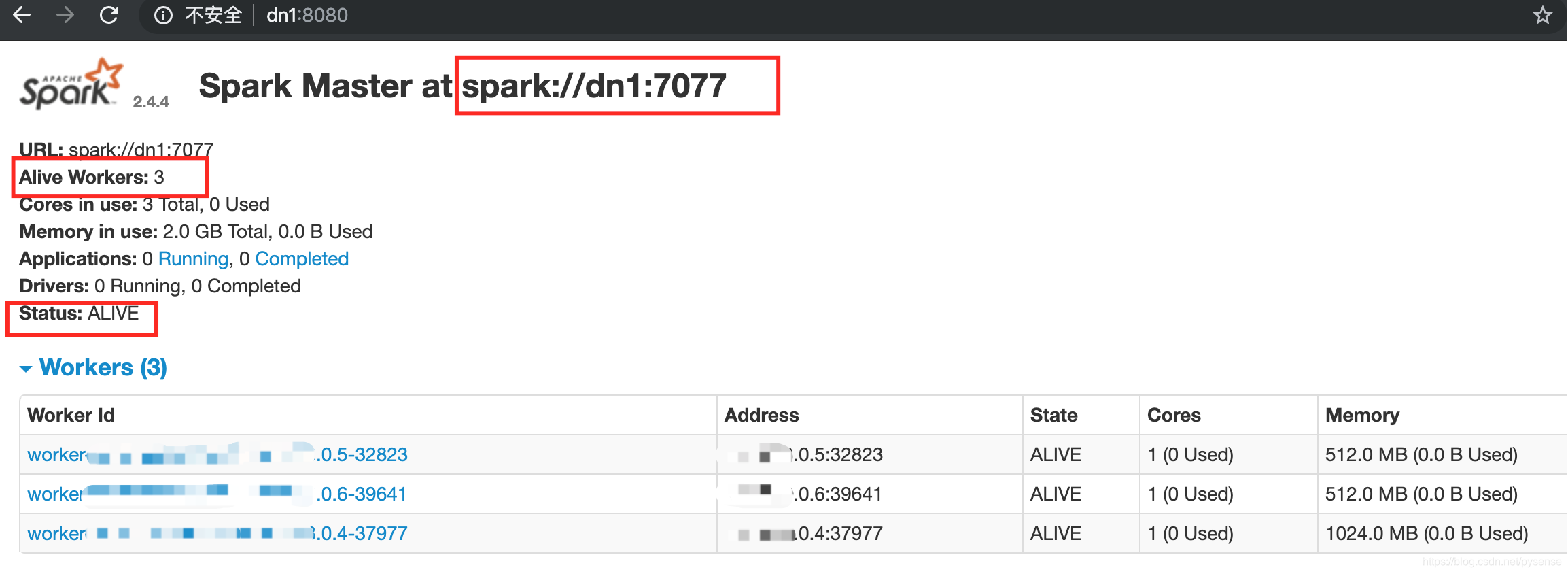
访问http://dn1:8080,dn1节点由standby变为active模式且有3个alive workers,而dn2仍然standby模式,说明HA部署正常。
9、结束
本文详细讨论了基于hadoop上搭建spark HA集群,并对执行的application做了简单的介绍,注意到,这里spark HA集群并没有引入yarn资源调度服务,后面的文章会给出配置过程。同时本文没有对spark架构及其原理做更多的探讨,相关文章也在之后给出。
