Applyment of I2I(Style Transfer
)
CartoonGAN
1.Style:normal->cartoon
2.Network Strucure
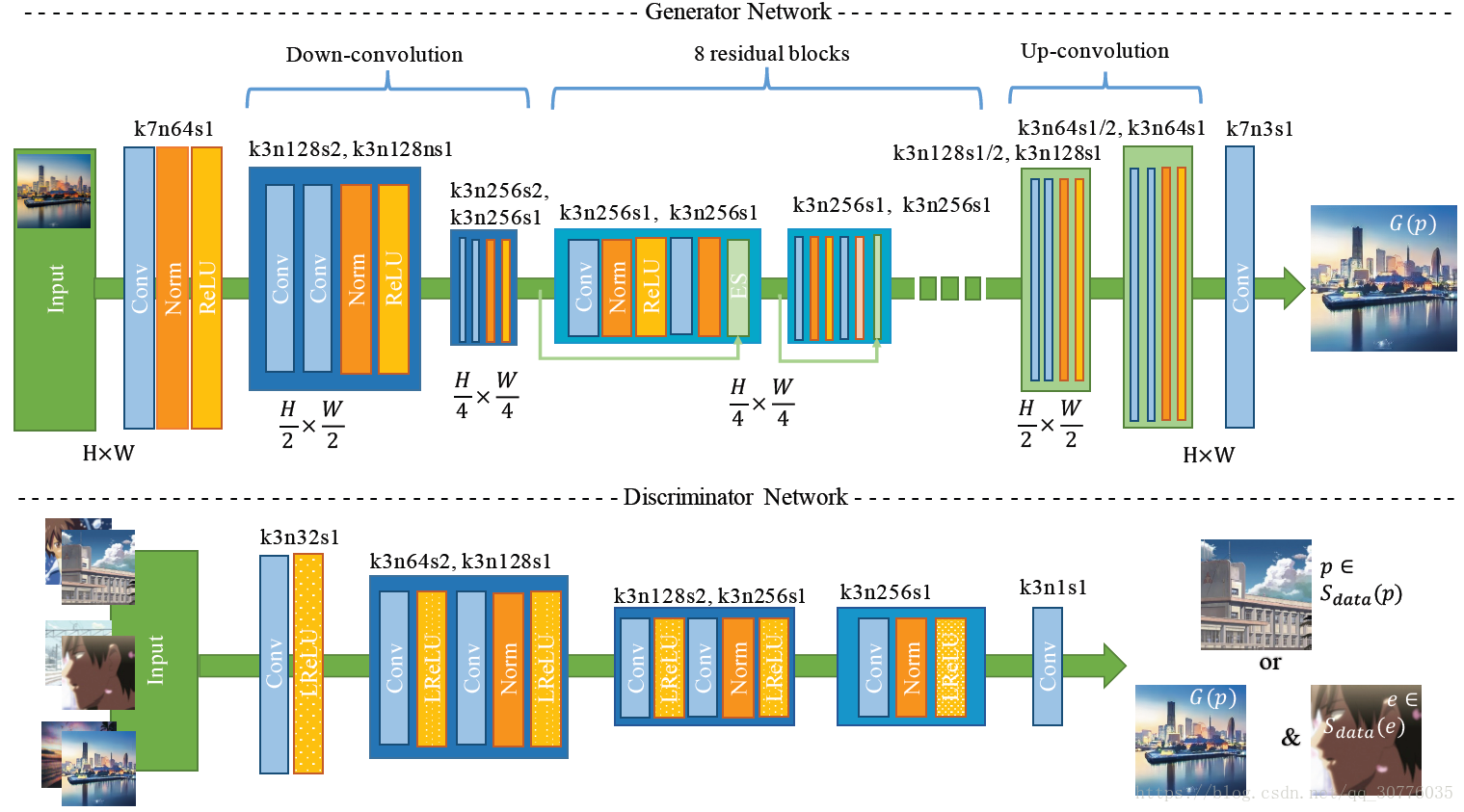
3.Loss Func
- Adversarial loss(!! without edge:fake)
- Content Loss:pretrianed VGG
- Total

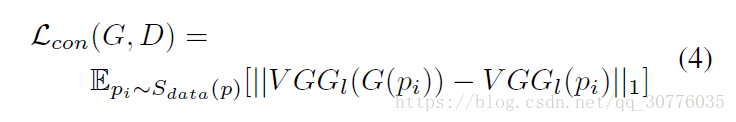
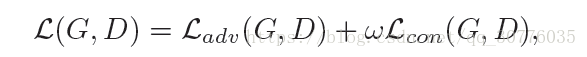
4.Metric
- Qualitative :images
5.DataSets
- Photos:Flickr
- Cartton:key frames of cartoon films
6.Other contributes
- Initialization
Pre-train the generator network G with only the semantic content loss Lcon(G;D).
Disentanged representaiton space in Content & Attribute
Diverse Image-to-Image Translation via
Disentangled Representations
1.Main
Better performance in I2I task:diverse realistic
2.Structure
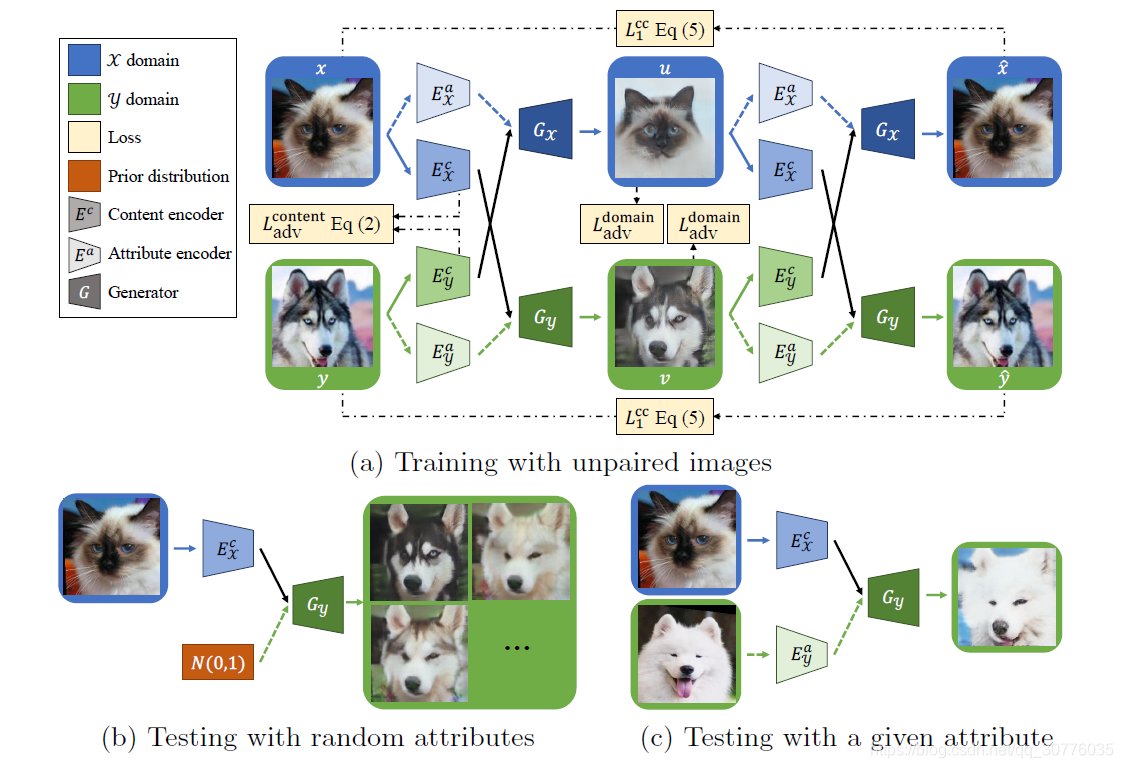
3. Loss func
-
Content Loss
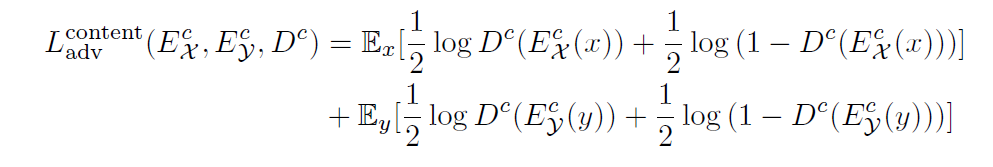
-
Cycle Loss
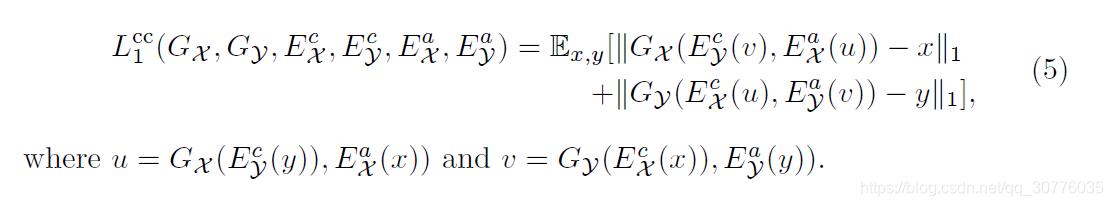
-
Domain adversarial loss:
Ldomain=logDd(u)+log(1-Dd(v)) -
Self-reconstruction loss:L1 for
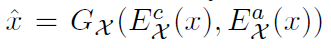
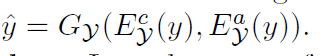
*KL loss
attribute distribution
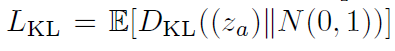
-
Cycle in Lantent space(for attribute distribution)
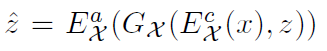
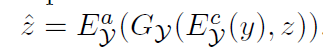
-
all
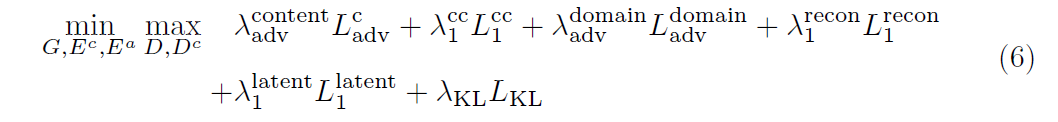
4.Datasets
- Yosemite (summer and winter scenes),
- artworks (Monet and van Gogh)
- edge-to-shoes
- photo-to-portrait cropped from subsets of the WikiArt dataset 1
- CelebA dataset
- NIST [24] to MNIST-M [12]
- classication and pose estimation tasks with Synthetic Cropped LineMod to Cropped LineMod
5.Metric
Qualitative Evaluation
- transfered images
- Linear interpolation
Quantitative Evaluation - Realism:user study
- diversity:LPIPS metric
- Reconstruction:compare with paired data
- Domain Adaptation: Accuracy
