every blog every motto: Until you make peace with who you are, you’ll never be content with what you have.
0. 前言
实战sklearn超参数搜索。
注: 训练时间较长。
1. 代码部分
1. 导入模块
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import sklearn
import pandas as pd
import os
import sys
import time
import tensorflow as tf
from tensorflow import keras
print(tf.__version__)
print(sys.version_info)
for module in mpl,np,pd,sklearn,tf,keras:
print(module.__name__,module.__version__)

2. 读取数据
from sklearn.datasets import fetch_california_housing
# 房价预测
housing = fetch_california_housing()
print(housing.DESCR)
print(housing.data.shape)
print(housing.target.shape)
3. 划分样本
# 划分样本
from sklearn.model_selection import train_test_split
x_train_all,x_test,y_train_all,y_test = train_test_split(housing.data,housing.target,random_state=7)
x_train,x_valid,y_train,y_valid = train_test_split(x_train_all,y_train_all,random_state=11)
print(x_train.shape,y_train.shape)
print(x_valid.shape,y_valid.shape)
print(x_test.shape,y_test.shape)

4. 数据归一化
# 归一化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
x_train_scaled = scaler.fit_transform(x_train)
x_valid_scaled = scaler.transform(x_valid)
x_test_scaled = scaler.transform(x_test)
5. 构建模型、训练
RandomizedSearchCV
步骤:
- 转换为sklearn的model(上节实现)
- 定义参数集合(本节实现)
- 搜索参数(本节实现)
# RandomizedSearchCV
# 步骤
# 1. 转换为sklearn的model
# 2. 定义参数集合
# 3. 搜索参数
def build_model(hidden_layers=1,layer_size=30,learning_rate=3e-3):
model = keras.models.Sequential()
model.add(keras.layers.Dense(layer_size,activation='relu',input_shape=x_train.shape[1:]))
for _ in range(hidden_layers - 1):
model.add(keras.layers.Dense(layer_size,activation='relu'))
model.add(keras.layers.Dense(1))
optimizer = keras.optimizers.SGD(learning_rate)
model.compile(loss="mse",optimizer=optimizer)
return model
# 转成sklearn model
sklearn_model = keras.wrappers.scikit_learn.KerasRegressor(build_model)
# 回调函数
callbacks = [keras.callbacks.EarlyStopping(patience=5,min_delta=1e-3)]
# 训练
history = sklearn_model.fit(x_train_scaled,y_train,epochs=100,validation_data=(x_valid_scaled,y_valid),callbacks=callbacks)
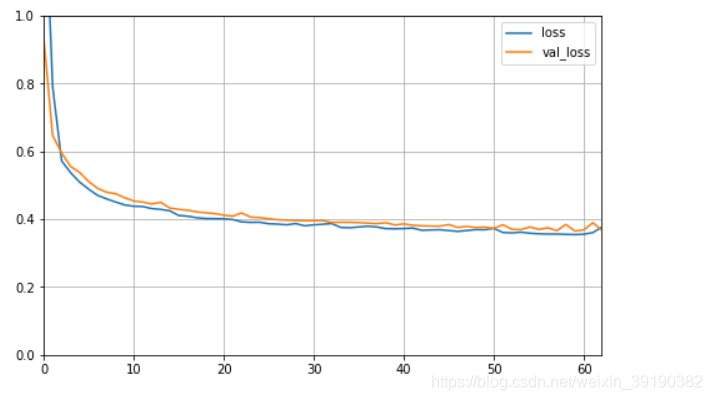
6. 学习曲线
# 学习曲线
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize=(8,5))
plt.grid(True)
plt.gca().set_ylim(0,1)
plt.show()
plot_learning_curves(history)
7. 超参数搜索
cross_validation:训练集分成n份,n-1训练,最后一份验证
from scipy.stats import reciprocal
# f(x) = 1/(x*log(b/a)) a<=x <=b
param_distribution = {
"hidden_layers":[1,2,3,4],
"layer_size":np.arange(1,100),
"learning_rate":reciprocal(1e-4,1e-2),
}
from sklearn.model_selection import RandomizedSearchCV
random_search_cv = RandomizedSearchCV(sklearn_model,param_distribution,n_iter = 10,n_jobs=1)
random_search_cv.fit(x_train_scaled,y_train,epochs=100,validation_data=(x_valid_scaled,y_valid),callbacks=callbacks)
# cross_validation:训练集分成n份,n-1训练,最后一份验证
8. 查询最好参数、分值、模型
# 查询最好参数、分值、模型
print(random_search_cv.best_params_)
print(random_search_cv.best_score_)
print(random_search_cv.best_estimator_)

9. 获取最好模型,并在测试集上验证
# 获取最好模型,对测试集进行测试
model = random_search_cv.best_estimator_.model
model.evaluate(x_test_scaled,y_test)

